 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Gemini Robotics Policies in a Veo World Simulator
Dec 11, 2025Generative world models hold significant potential for simulating interactions with visuomotor policies in varied environments. Frontier video models can enable generation of realistic observations and environment interactions in a scalable and general manner. However, the use of video models in robotics has been limited primarily to in-distribution evaluations, i.e., scenarios that are similar to ones used to train the policy or fine-tune the base video model. In this report, we demonstrate that video models can be used for the entire spectrum of policy evaluation use cases in robotics: from assessing nominal performance to out-of-distribution (OOD) generalization, and probing physical and semantic safety. We introduce a generative evaluation system built upon a frontier video foundation model (Veo). The system is optimized to support robot action conditioning and multi-view consistency, while integrating generative image-editing and multi-view completion to synthesize realistic variations of real-world scenes along multiple axes of generalization. We demonstrate that the system preserves the base capabilities of the video model to enable accurate simulation of scenes that have been edited to include novel interaction objects, novel visual backgrounds, and novel distractor objects. This fidelity enables accurately predicting the relative performance of different policies in both nominal and OOD conditions, determining the relative impact of different axes of generalization on policy performance, and performing red teaming of policies to expose behaviors that violate physical or semantic safety constraints. We validate these capabilities through 1600+ real-world evaluations of eight Gemini Robotics policy checkpoints and five tasks for a bimanual manipulator.
Gemini Robotics: Bringing AI into the Physical World
Mar 25, 2025Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.
Adaptive Data Optimization: Dynamic Sample Selection with Scaling Laws
Oct 15, 2024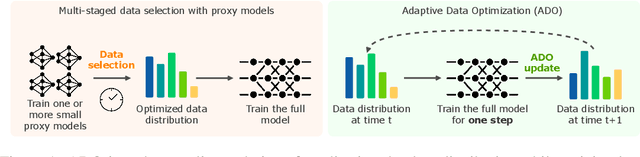
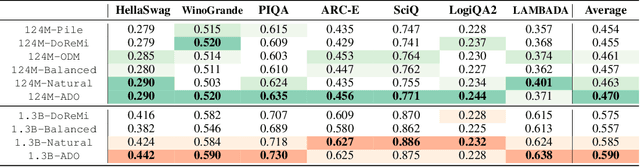
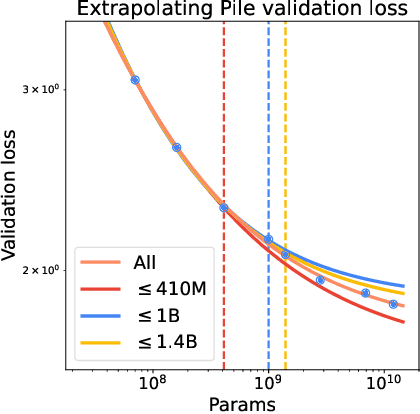
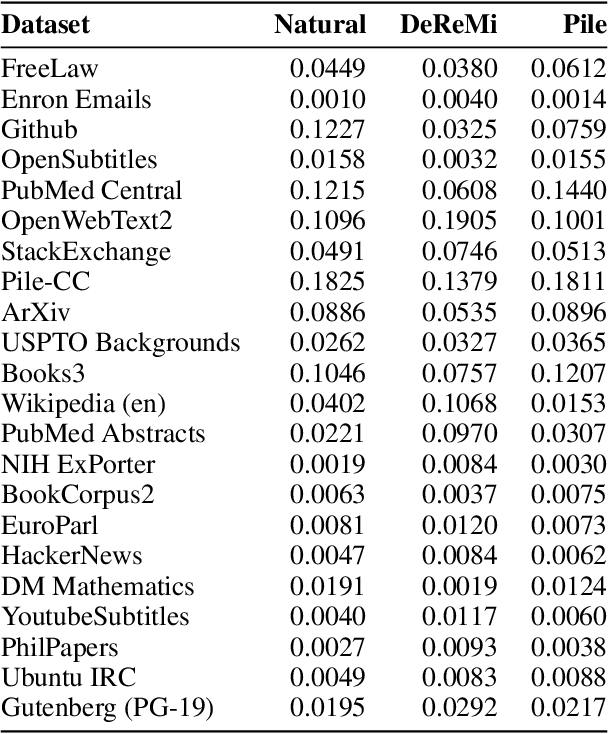
The composition of pretraining data is a key determinant of foundation models' performance, but there is no standard guideline for allocating a limited computational budget across different data sources. Most current approaches either rely on extensive experiments with smaller models or dynamic data adjustments that also require proxy models, both of which significantly increase the workflow complexity and computational overhead. In this paper, we introduce Adaptive Data Optimization (ADO), an algorithm that optimizes data distributions in an online fashion, concurrent with model training. Unlike existing techniques, ADO does not require external knowledge, proxy models, or modifications to the model update. Instead, ADO uses per-domain scaling laws to estimate the learning potential of each domain during training and adjusts the data mixture accordingly, making it more scalable and easier to integrate. Experiments demonstrate that ADO can achieve comparable or better performance than prior methods while maintaining computational efficiency across different computation scales, offering a practical solution for dynamically adjusting data distribution without sacrificing flexibility or increasing costs. Beyond its practical benefits, ADO also provides a new perspective on data collection strategies via scaling laws.
Universal Neural Functionals
Feb 07, 2024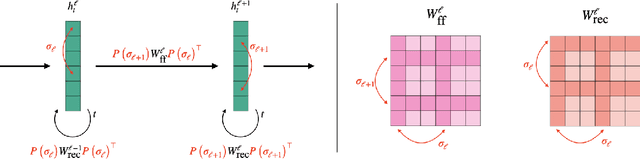

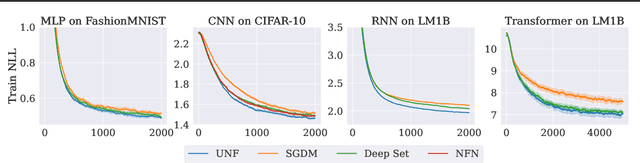
A challenging problem in many modern machine learning tasks is to process weight-space features, i.e., to transform or extract information from the weights and gradients of a neural network. Recent works have developed promising weight-space models that are equivariant to the permutation symmetries of simple feedforward networks. However, they are not applicable to general architectures, since the permutation symmetries of a weight space can be complicated by recurrence or residual connections. This work proposes an algorithm that automatically constructs permutation equivariant models, which we refer to as universal neural functionals (UNFs), for any weight space. Among other applications, we demonstrate how UNFs can be substituted into existing learned optimizer designs, and find promising improvements over prior methods when optimizing small image classifiers and language models. Our results suggest that learned optimizers can benefit from considering the (symmetry) structure of the weight space they optimize. We open-source our library for constructing UNFs at https://github.com/AllanYangZhou/universal_neural_functional.
AutoFT: Robust Fine-Tuning by Optimizing Hyperparameters on OOD Data
Jan 18, 2024Foundation models encode rich representations that can be adapted to a desired task by fine-tuning on task-specific data. However, fine-tuning a model on one particular data distribution often compromises the model's original performance on other distributions. Current methods for robust fine-tuning utilize hand-crafted regularization techniques to constrain the fine-tuning process towards the base foundation model. Yet, it is hard to precisely specify what characteristics of the foundation model to retain during fine-tuning, as this depends on how the pre-training, fine-tuning, and evaluation data distributions relate to each other. We propose AutoFT, a data-driven approach for guiding foundation model fine-tuning. AutoFT optimizes fine-tuning hyperparameters to maximize performance on a small out-of-distribution (OOD) validation set. To guide fine-tuning in a granular way, AutoFT searches a highly expressive hyperparameter space that includes weight coefficients for many different losses, in addition to learning rate and weight decay values. We evaluate AutoFT on nine natural distribution shifts which include domain shifts and subpopulation shifts. Our experiments show that AutoFT significantly improves generalization to new OOD data, outperforming existing robust fine-tuning methods. Notably, AutoFT achieves new state-of-the-art performance on the WILDS-iWildCam and WILDS-FMoW benchmarks, outperforming the previous best methods by $6.0\%$ and $1.5\%$, respectively.
Fleet Policy Learning via Weight Merging and An Application to Robotic Tool-Use
Oct 02, 2023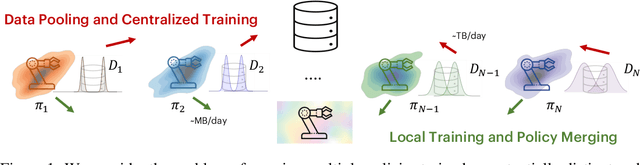

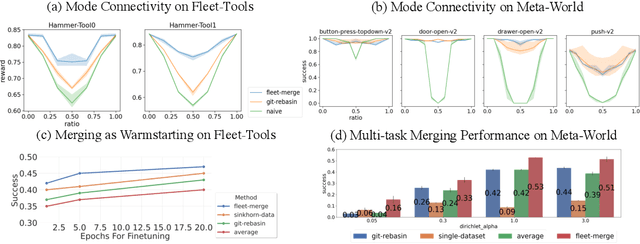
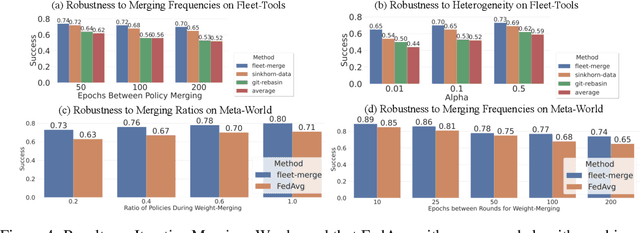
Fleets of robots ingest massive amounts of streaming data generated by interacting with their environments, far more than those that can be stored or transmitted with ease. At the same time, we hope that teams of robots can co-acquire diverse skills through their experiences in varied settings. How can we enable such fleet-level learning without having to transmit or centralize fleet-scale data? In this paper, we investigate distributed learning of policies as a potential solution. To efficiently merge policies in the distributed setting, we propose fleet-merge, an instantiation of distributed learning that accounts for the symmetries that can arise in learning policies that are parameterized by recurrent neural networks. We show that fleet-merge consolidates the behavior of policies trained on 50 tasks in the Meta-World environment, with the merged policy achieving good performance on nearly all training tasks at test time. Moreover, we introduce a novel robotic tool-use benchmark, fleet-tools, for fleet policy learning in compositional and contact-rich robot manipulation tasks, which might be of broader interest, and validate the efficacy of fleet-merge on the benchmark.
Neural Processing of Tri-Plane Hybrid Neural Fields
Oct 02, 2023
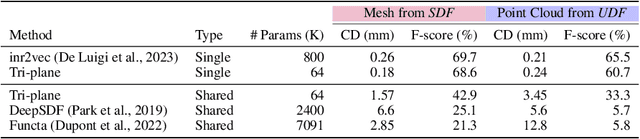
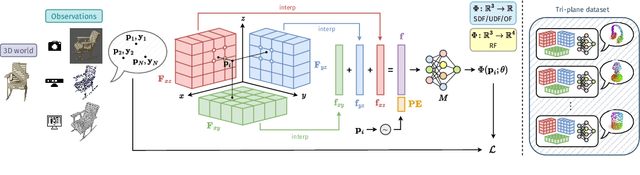

Driven by the appealing properties of neural fields for storing and communicating 3D data, the problem of directly processing them to address tasks such as classification and part segmentation has emerged and has been investigated in recent works. Early approaches employ neural fields parameterized by shared networks trained on the whole dataset, achieving good task performance but sacrificing reconstruction quality. To improve the latter, later methods focus on individual neural fields parameterized as large Multi-Layer Perceptrons (MLPs), which are, however, challenging to process due to the high dimensionality of the weight space, intrinsic weight space symmetries, and sensitivity to random initialization. Hence, results turn out significantly inferior to those achieved by processing explicit representations, e.g., point clouds or meshes. In the meantime, hybrid representations, in particular based on tri-planes, have emerged as a more effective and efficient alternative to realize neural fields, but their direct processing has not been investigated yet. In this paper, we show that the tri-plane discrete data structure encodes rich information, which can be effectively processed by standard deep-learning machinery. We define an extensive benchmark covering a diverse set of fields such as occupancy, signed/unsigned distance, and, for the first time, radiance fields. While processing a field with the same reconstruction quality, we achieve task performance far superior to frameworks that process large MLPs and, for the first time, almost on par with architectures handling explicit representations.
Simple Embodied Language Learning as a Byproduct of Meta-Reinforcement Learning
Jun 14, 2023



Whereas machine learning models typically learn language by directly training on language tasks (e.g., next-word prediction), language emerges in human children as a byproduct of solving non-language tasks (e.g., acquiring food). Motivated by this observation, we ask: can embodied reinforcement learning (RL) agents also indirectly learn language from non-language tasks? Learning to associate language with its meaning requires a dynamic environment with varied language. Therefore, we investigate this question in a multi-task environment with language that varies across the different tasks. Specifically, we design an office navigation environment, where the agent's goal is to find a particular office, and office locations differ in different buildings (i.e., tasks). Each building includes a floor plan with a simple language description of the goal office's location, which can be visually read as an RGB image when visited. We find RL agents indeed are able to indirectly learn language. Agents trained with current meta-RL algorithms successfully generalize to reading floor plans with held-out layouts and language phrases, and quickly navigate to the correct office, despite receiving no direct language supervision.
Just Ask for Calibration: Strategies for Eliciting Calibrated Confidence Scores from Language Models Fine-Tuned with Human Feedback
May 24, 2023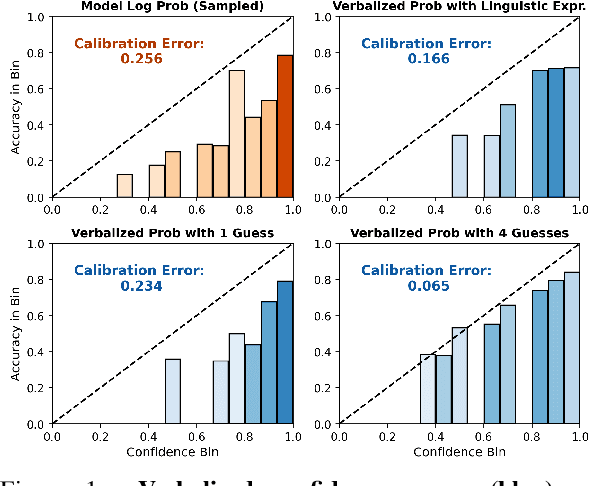
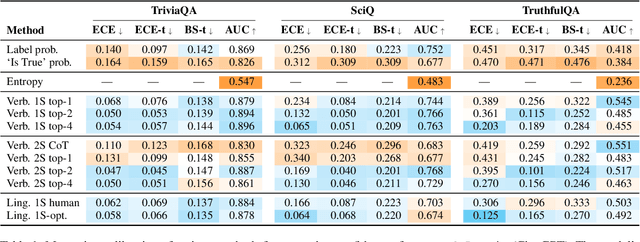
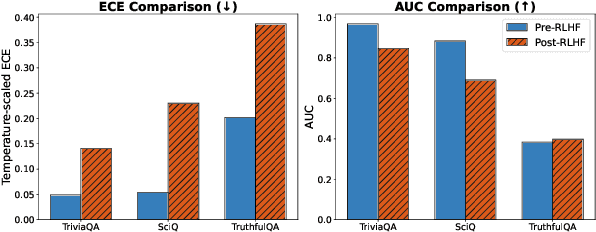
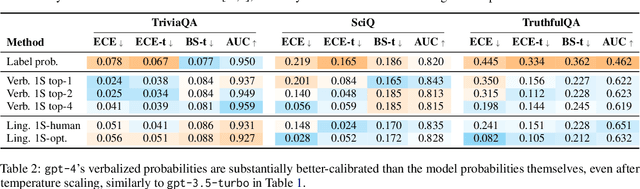
A trustworthy real-world prediction system should be well-calibrated; that is, its confidence in an answer is indicative of the likelihood that the answer is correct, enabling deferral to a more expensive expert in cases of low-confidence predictions. While recent studies have shown that unsupervised pre-training produces large language models (LMs) that are remarkably well-calibrated, the most widely-used LMs in practice are fine-tuned with reinforcement learning with human feedback (RLHF-LMs) after the initial unsupervised pre-training stage, and results are mixed as to whether these models preserve the well-calibratedness of their ancestors. In this paper, we conduct a broad evaluation of computationally feasible methods for extracting confidence scores from LLMs fine-tuned with RLHF. We find that with the right prompting strategy, RLHF-LMs verbalize probabilities that are much better calibrated than the model's conditional probabilities, enabling fairly well-calibrated predictions. Through a combination of prompting strategy and temperature scaling, we find that we can reduce the expected calibration error of RLHF-LMs by over 50%.
Neural Functional Transformers
May 22, 2023
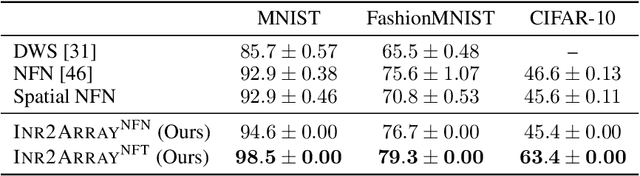
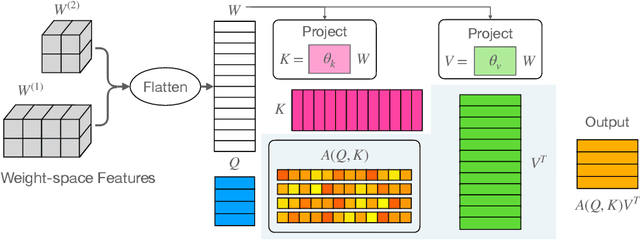

The recent success of neural networks as implicit representation of data has driven growing interest in neural functionals: models that can process other neural networks as input by operating directly over their weight spaces. Nevertheless, constructing expressive and efficient neural functional architectures that can handle high-dimensional weight-space objects remains challenging. This paper uses the attention mechanism to define a novel set of permutation equivariant weight-space layers and composes them into deep equivariant models called neural functional Transformers (NFTs). NFTs respect weight-space permutation symmetries while incorporating the advantages of attention, which have exhibited remarkable success across multiple domains. In experiments processing the weights of feedforward MLPs and CNNs, we find that NFTs match or exceed the performance of prior weight-space methods. We also leverage NFTs to develop Inr2Array, a novel method for computing permutation invariant latent representations from the weights of implicit neural representations (INRs). Our proposed method improves INR classification accuracy by up to $+17\%$ over existing methods. We provide an implementation of our layers at https://github.com/AllanYangZhou/nfn.