 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenThoughts: Data Recipes for Reasoning Models
Jun 05, 2025Reasoning models have made rapid progress on many benchmarks involving math, code, and science. Yet, there are still many open questions about the best training recipes for reasoning since state-of-the-art models often rely on proprietary datasets with little to no public information available. To address this, the goal of the OpenThoughts project is to create open-source datasets for training reasoning models. After initial explorations, our OpenThoughts2-1M dataset led to OpenThinker2-32B, the first model trained on public reasoning data to match DeepSeek-R1-Distill-32B on standard reasoning benchmarks such as AIME and LiveCodeBench. We then improve our dataset further by systematically investigating each step of our data generation pipeline with 1,000+ controlled experiments, which led to OpenThoughts3. Scaling the pipeline to 1.2M examples and using QwQ-32B as teacher yields our OpenThoughts3-7B model, which achieves state-of-the-art results: 53% on AIME 2025, 51% on LiveCodeBench 06/24-01/25, and 54% on GPQA Diamond - improvements of 15.3, 17.2, and 20.5 percentage points compared to the DeepSeek-R1-Distill-Qwen-7B. All of our datasets and models are available on https://openthoughts.ai.
AutoFT: Robust Fine-Tuning by Optimizing Hyperparameters on OOD Data
Jan 18, 2024Foundation models encode rich representations that can be adapted to a desired task by fine-tuning on task-specific data. However, fine-tuning a model on one particular data distribution often compromises the model's original performance on other distributions. Current methods for robust fine-tuning utilize hand-crafted regularization techniques to constrain the fine-tuning process towards the base foundation model. Yet, it is hard to precisely specify what characteristics of the foundation model to retain during fine-tuning, as this depends on how the pre-training, fine-tuning, and evaluation data distributions relate to each other. We propose AutoFT, a data-driven approach for guiding foundation model fine-tuning. AutoFT optimizes fine-tuning hyperparameters to maximize performance on a small out-of-distribution (OOD) validation set. To guide fine-tuning in a granular way, AutoFT searches a highly expressive hyperparameter space that includes weight coefficients for many different losses, in addition to learning rate and weight decay values. We evaluate AutoFT on nine natural distribution shifts which include domain shifts and subpopulation shifts. Our experiments show that AutoFT significantly improves generalization to new OOD data, outperforming existing robust fine-tuning methods. Notably, AutoFT achieves new state-of-the-art performance on the WILDS-iWildCam and WILDS-FMoW benchmarks, outperforming the previous best methods by $6.0\%$ and $1.5\%$, respectively.
Conservative Prediction via Data-Driven Confidence Minimization
Jun 08, 2023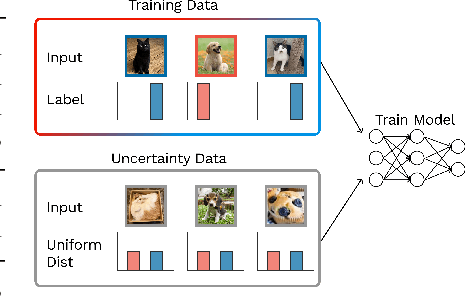
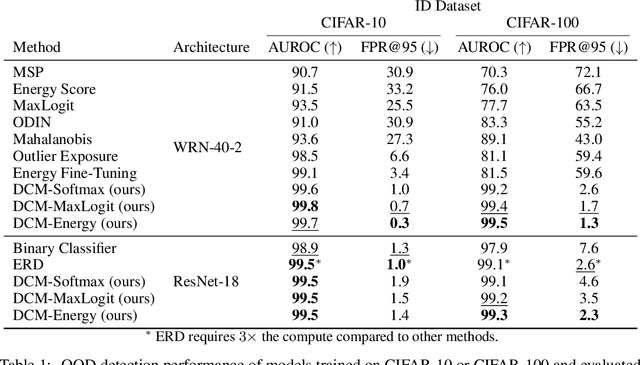
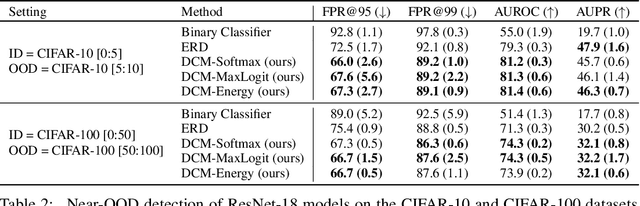
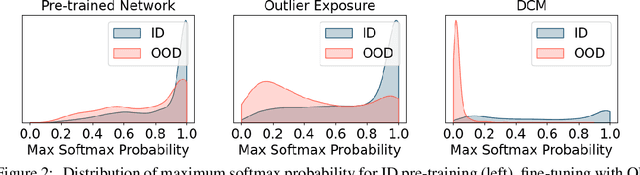
Errors of machine learning models are costly, especially in safety-critical domains such as healthcare, where such mistakes can prevent the deployment of machine learning altogether. In these settings, conservative models -- models which can defer to human judgment when they are likely to make an error -- may offer a solution. However, detecting unusual or difficult examples is notably challenging, as it is impossible to anticipate all potential inputs at test time. To address this issue, prior work has proposed to minimize the model's confidence on an auxiliary pseudo-OOD dataset. We theoretically analyze the effect of confidence minimization and show that the choice of auxiliary dataset is critical. Specifically, if the auxiliary dataset includes samples from the OOD region of interest, confidence minimization provably separates ID and OOD inputs by predictive confidence. Taking inspiration from this result, we present data-driven confidence minimization (DCM), which minimizes confidence on an uncertainty dataset containing examples that the model is likely to misclassify at test time. Our experiments show that DCM consistently outperforms state-of-the-art OOD detection methods on 8 ID-OOD dataset pairs, reducing FPR (at TPR 95%) by 6.3% and 58.1% on CIFAR-10 and CIFAR-100, and outperforms existing selective classification approaches on 4 datasets in conditions of distribution shift.
Wild-Time: A Benchmark of in-the-Wild Distribution Shift over Time
Nov 25, 2022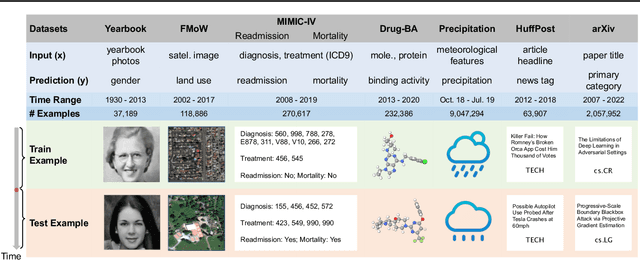
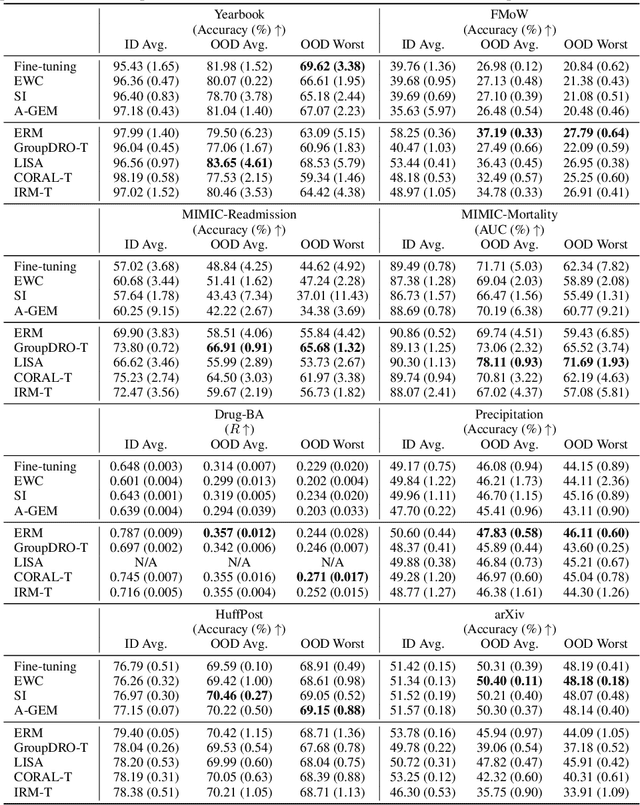
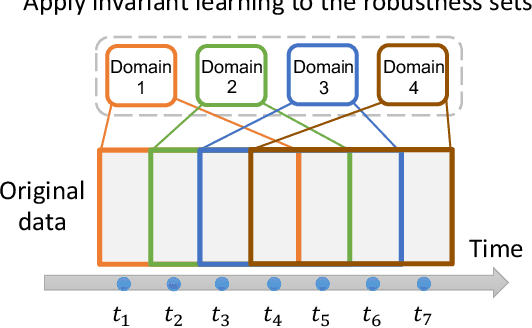
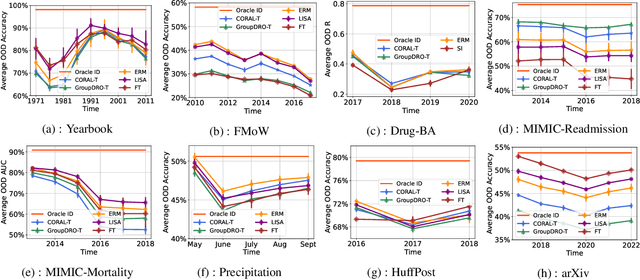
Distribution shift occurs when the test distribution differs from the training distribution, and it can considerably degrade performance of machine learning models deployed in the real world. Temporal shifts -- distribution shifts arising from the passage of time -- often occur gradually and have the additional structure of timestamp metadata. By leveraging timestamp metadata, models can potentially learn from trends in past distribution shifts and extrapolate into the future. While recent works have studied distribution shifts, temporal shifts remain underexplored. To address this gap, we curate Wild-Time, a benchmark of 5 datasets that reflect temporal distribution shifts arising in a variety of real-world applications, including patient prognosis and news classification. On these datasets, we systematically benchmark 13 prior approaches, including methods in domain generalization, continual learning, self-supervised learning, and ensemble learning. We use two evaluation strategies: evaluation with a fixed time split (Eval-Fix) and evaluation with a data stream (Eval-Stream). Eval-Fix, our primary evaluation strategy, aims to provide a simple evaluation protocol, while Eval-Stream is more realistic for certain real-world applications. Under both evaluation strategies, we observe an average performance drop of 20% from in-distribution to out-of-distribution data. Existing methods are unable to close this gap. Code is available at https://wild-time.github.io/.