 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrospective In-Context Learning for Temporal Credit Assignment with Large Language Models
Feb 19, 2026Learning from self-sampled data and sparse environmental feedback remains a fundamental challenge in training self-evolving agents. Temporal credit assignment mitigates this issue by transforming sparse feedback into dense supervision signals. However, previous approaches typically depend on learning task-specific value functions for credit assignment, which suffer from poor sample efficiency and limited generalization. In this work, we propose to leverage pretrained knowledge from large language models (LLMs) to transform sparse rewards into dense training signals (i.e., the advantage function) through retrospective in-context learning (RICL). We further propose an online learning framework, RICOL, which iteratively refines the policy based on the credit assignment results from RICL. We empirically demonstrate that RICL can accurately estimate the advantage function with limited samples and effectively identify critical states in the environment for temporal credit assignment. Extended evaluation on four BabyAI scenarios show that RICOL achieves comparable convergent performance with traditional online RL algorithms with significantly higher sample efficiency. Our findings highlight the potential of leveraging LLMs for temporal credit assignment, paving the way for more sample-efficient and generalizable RL paradigms.
Expanding the Capabilities of Reinforcement Learning via Text Feedback
Feb 02, 2026The success of RL for LLM post-training stems from an unreasonably uninformative source: a single bit of information per rollout as binary reward or preference label. At the other extreme, distillation offers dense supervision but requires demonstrations, which are costly and difficult to scale. We study text feedback as an intermediate signal: richer than scalar rewards, yet cheaper than complete demonstrations. Textual feedback is a natural mode of human interaction and is already abundant in many real-world settings, where users, annotators, and automated judges routinely critique LLM outputs. Towards leveraging text feedback at scale, we formalize a multi-turn RL setup, RL from Text Feedback (RLTF), where text feedback is available during training but not at inference. Therefore, models must learn to internalize the feedback in order to improve their test-time single-turn performance. To do this, we propose two methods: Self Distillation (RLTF-SD), which trains the single-turn policy to match its own feedback-conditioned second-turn generations; and Feedback Modeling (RLTF-FM), which predicts the feedback as an auxiliary objective. We provide theoretical analysis on both methods, and empirically evaluate on reasoning puzzles, competition math, and creative writing tasks. Our results show that both methods consistently outperform strong baselines across benchmarks, highlighting the potential of RL with an additional source of rich supervision at scale.
Maximum Likelihood Reinforcement Learning
Feb 02, 2026Reinforcement learning is the method of choice to train models in sampling-based setups with binary outcome feedback, such as navigation, code generation, and mathematical problem solving. In such settings, models implicitly induce a likelihood over correct rollouts. However, we observe that reinforcement learning does not maximize this likelihood, and instead optimizes only a lower-order approximation. Inspired by this observation, we introduce Maximum Likelihood Reinforcement Learning (MaxRL), a sampling-based framework to approximate maximum likelihood using reinforcement learning techniques. MaxRL addresses the challenges of non-differentiable sampling by defining a compute-indexed family of sample-based objectives that interpolate between standard reinforcement learning and exact maximum likelihood as additional sampling compute is allocated. The resulting objectives admit a simple, unbiased policy-gradient estimator and converge to maximum likelihood optimization in the infinite-compute limit. Empirically, we show that MaxRL Pareto-dominates existing methods in all models and tasks we tested, achieving up to 20x test-time scaling efficiency gains compared to its GRPO-trained counterpart. We also observe MaxRL to scale better with additional data and compute. Our results suggest MaxRL is a promising framework for scaling RL training in correctness based settings.
Reasoning as an Adaptive Defense for Safety
Jul 01, 2025



Reasoning methods that adaptively allocate test-time compute have advanced LLM performance on easy to verify domains such as math and code. In this work, we study how to utilize this approach to train models that exhibit a degree of robustness to safety vulnerabilities, and show that doing so can provide benefits. We build a recipe called $\textit{TARS}$ (Training Adaptive Reasoners for Safety), a reinforcement learning (RL) approach that trains models to reason about safety using chain-of-thought traces and a reward signal that balances safety with task completion. To build TARS, we identify three critical design choices: (1) a "lightweight" warmstart SFT stage, (2) a mix of harmful, harmless, and ambiguous prompts to prevent shortcut behaviors such as too many refusals, and (3) a reward function to prevent degeneration of reasoning capabilities during training. Models trained with TARS exhibit adaptive behaviors by spending more compute on ambiguous queries, leading to better safety-refusal trade-offs. They also internally learn to better distinguish between safe and unsafe prompts and attain greater robustness to both white-box (e.g., GCG) and black-box attacks (e.g., PAIR). Overall, our work provides an effective, open recipe for training LLMs against jailbreaks and harmful requests by reasoning per prompt.
Accelerating Diffusion Models in Offline RL via Reward-Aware Consistency Trajectory Distillation
Jun 09, 2025Although diffusion models have achieved strong results in decision-making tasks, their slow inference speed remains a key limitation. While the consistency model offers a potential solution, its applications to decision-making often struggle with suboptimal demonstrations or rely on complex concurrent training of multiple networks. In this work, we propose a novel approach to consistency distillation for offline reinforcement learning that directly incorporates reward optimization into the distillation process. Our method enables single-step generation while maintaining higher performance and simpler training. Empirical evaluations on the Gym MuJoCo benchmarks and long horizon planning demonstrate that our approach can achieve an 8.7% improvement over previous state-of-the-art while offering up to 142x speedup over diffusion counterparts in inference time.
Can Large Reasoning Models Self-Train?
May 27, 2025



Scaling the performance of large language models (LLMs) increasingly depends on methods that reduce reliance on human supervision. Reinforcement learning from automated verification offers an alternative, but it incurs scalability limitations due to dependency upon human-designed verifiers. Self-training, where the model's own judgment provides the supervisory signal, presents a compelling direction. We propose an online self-training reinforcement learning algorithm that leverages the model's self-consistency to infer correctness signals and train without any ground-truth supervision. We apply the algorithm to challenging mathematical reasoning tasks and show that it quickly reaches performance levels rivaling reinforcement-learning methods trained explicitly on gold-standard answers. Additionally, we analyze inherent limitations of the algorithm, highlighting how the self-generated proxy reward initially correlated with correctness can incentivize reward hacking, where confidently incorrect outputs are favored. Our results illustrate how self-supervised improvement can achieve significant performance gains without external labels, while also revealing its fundamental challenges.
Training a Generally Curious Agent
Feb 24, 2025



Efficient exploration is essential for intelligent systems interacting with their environment, but existing language models often fall short in scenarios that require strategic information gathering. In this paper, we present PAPRIKA, a fine-tuning approach that enables language models to develop general decision-making capabilities that are not confined to particular environments. By training on synthetic interaction data from different tasks that require diverse strategies, PAPRIKA teaches models to explore and adapt their behavior on a new task based on environment feedback in-context without more gradient updates. Experimental results show that models fine-tuned with PAPRIKA can effectively transfer their learned decision-making capabilities to entirely unseen tasks without additional training. Unlike traditional training, our approach's primary bottleneck lies in sampling useful interaction data instead of model updates. To improve sample efficiency, we propose a curriculum learning strategy that prioritizes sampling trajectories from tasks with high learning potential. These results suggest a promising path towards AI systems that can autonomously solve novel sequential decision-making problems that require interactions with the external world.
Self-Regulation and Requesting Interventions
Feb 07, 2025



Human intelligence involves metacognitive abilities like self-regulation, recognizing limitations, and seeking assistance only when needed. While LLM Agents excel in many domains, they often lack this awareness. Overconfident agents risk catastrophic failures, while those that seek help excessively hinder efficiency. A key challenge is enabling agents with a limited intervention budget $C$ is to decide when to request assistance. In this paper, we propose an offline framework that trains a "helper" policy to request interventions, such as more powerful models or test-time compute, by combining LLM-based process reward models (PRMs) with tabular reinforcement learning. Using state transitions collected offline, we score optimal intervention timing with PRMs and train the helper model on these labeled trajectories. This offline approach significantly reduces costly intervention calls during training. Furthermore, the integration of PRMs with tabular RL enhances robustness to off-policy data while avoiding the inefficiencies of deep RL. We empirically find that our method delivers optimal helper behavior.
Preference Fine-Tuning of LLMs Should Leverage Suboptimal, On-Policy Data
Apr 23, 2024



Learning from preference labels plays a crucial role in fine-tuning large language models. There are several distinct approaches for preference fine-tuning, including supervised learning, on-policy reinforcement learning (RL), and contrastive learning. Different methods come with different implementation tradeoffs and performance differences, and existing empirical findings present different conclusions, for instance, some results show that online RL is quite important to attain good fine-tuning results, while others find (offline) contrastive or even purely supervised methods sufficient. This raises a natural question: what kind of approaches are important for fine-tuning with preference data and why? In this paper, we answer this question by performing a rigorous analysis of a number of fine-tuning techniques on didactic and full-scale LLM problems. Our main finding is that, in general, approaches that use on-policy sampling or attempt to push down the likelihood on certain responses (i.e., employ a "negative gradient") outperform offline and maximum likelihood objectives. We conceptualize our insights and unify methods that use on-policy sampling or negative gradient under a notion of mode-seeking objectives for categorical distributions. Mode-seeking objectives are able to alter probability mass on specific bins of a categorical distribution at a fast rate compared to maximum likelihood, allowing them to relocate masses across bins more effectively. Our analysis prescribes actionable insights for preference fine-tuning of LLMs and informs how data should be collected for maximal improvement.
Offline Retraining for Online RL: Decoupled Policy Learning to Mitigate Exploration Bias
Oct 12, 2023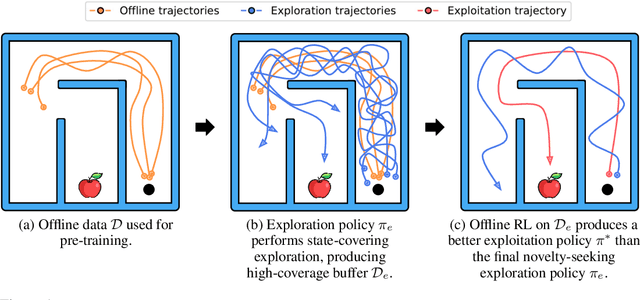
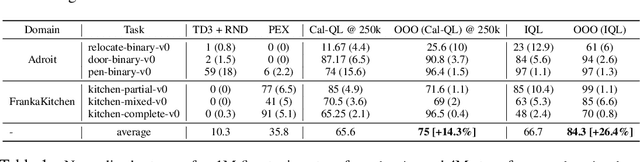
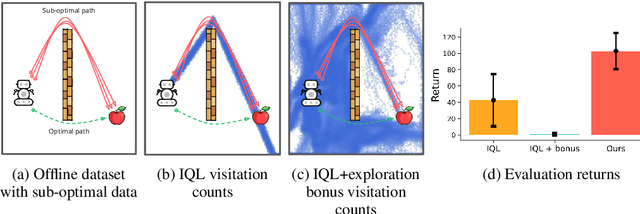

It is desirable for policies to optimistically explore new states and behaviors during online reinforcement learning (RL) or fine-tuning, especially when prior offline data does not provide enough state coverage. However, exploration bonuses can bias the learned policy, and our experiments find that naive, yet standard use of such bonuses can fail to recover a performant policy. Concurrently, pessimistic training in offline RL has enabled recovery of performant policies from static datasets. Can we leverage offline RL to recover better policies from online interaction? We make a simple observation that a policy can be trained from scratch on all interaction data with pessimistic objectives, thereby decoupling the policies used for data collection and for evaluation. Specifically, we propose offline retraining, a policy extraction step at the end of online fine-tuning in our Offline-to-Online-to-Offline (OOO) framework for reinforcement learning (RL). An optimistic (exploration) policy is used to interact with the environment, and a separate pessimistic (exploitation) policy is trained on all the observed data for evaluation. Such decoupling can reduce any bias from online interaction (intrinsic rewards, primacy bias) in the evaluation policy, and can allow more exploratory behaviors during online interaction which in turn can generate better data for exploitation. OOO is complementary to several offline-to-online RL and online RL methods, and improves their average performance by 14% to 26% in our fine-tuning experiments, achieves state-of-the-art performance on several environments in the D4RL benchmarks, and improves online RL performance by 165% on two OpenAI gym environments. Further, OOO can enable fine-tuning from incomplete offline datasets where prior methods can fail to recover a performant policy. Implementation: https://github.com/MaxSobolMark/OOO