 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligned, Orthogonal or In-conflict: When can we safely optimize Chain-of-Thought?
Mar 31, 2026Chain-of-Thought (CoT) monitoring, in which automated systems monitor the CoT of an LLM, is a promising approach for effectively overseeing AI systems. However, the extent to which a model's CoT helps us oversee the model - the monitorability of the CoT - can be affected by training, for instance by the model learning to hide important features of its reasoning. We propose and empirically validate a conceptual framework for predicting when and why this occurs. We model LLM post-training as an RL environment where the reward decomposes into two terms: one term depending on final outputs and another term depending on the CoT. Our framework allows us to classify these two terms as "aligned", "orthogonal", or "in-conflict" before training. We predict that training with in-conflict terms will reduce monitorability, orthogonal terms will not affect it, and aligned terms will improve it. To validate our framework, we use it to classify a set of RL environments, train LLMs within those environments, and evaluate how training affects CoT monitorability. We find that (1) training with "in-conflict" reward terms reduces CoT monitorability and (2) optimizing in-conflict reward terms is difficult.
Self-Regulation and Requesting Interventions
Feb 07, 2025



Human intelligence involves metacognitive abilities like self-regulation, recognizing limitations, and seeking assistance only when needed. While LLM Agents excel in many domains, they often lack this awareness. Overconfident agents risk catastrophic failures, while those that seek help excessively hinder efficiency. A key challenge is enabling agents with a limited intervention budget $C$ is to decide when to request assistance. In this paper, we propose an offline framework that trains a "helper" policy to request interventions, such as more powerful models or test-time compute, by combining LLM-based process reward models (PRMs) with tabular reinforcement learning. Using state transitions collected offline, we score optimal intervention timing with PRMs and train the helper model on these labeled trajectories. This offline approach significantly reduces costly intervention calls during training. Furthermore, the integration of PRMs with tabular RL enhances robustness to off-policy data while avoiding the inefficiencies of deep RL. We empirically find that our method delivers optimal helper behavior.
Visibility into AI Agents
Feb 04, 2024

Increased delegation of commercial, scientific, governmental, and personal activities to AI agents -- systems capable of pursuing complex goals with limited supervision -- may exacerbate existing societal risks and introduce new risks. Understanding and mitigating these risks involves critically evaluating existing governance structures, revising and adapting these structures where needed, and ensuring accountability of key stakeholders. Information about where, why, how, and by whom certain AI agents are used, which we refer to as visibility, is critical to these objectives. In this paper, we assess three categories of measures to increase visibility into AI agents: agent identifiers, real-time monitoring, and activity logging. For each, we outline potential implementations that vary in intrusiveness and informativeness. We analyze how the measures apply across a spectrum of centralized through decentralized deployment contexts, accounting for various actors in the supply chain including hardware and software service providers. Finally, we discuss the implications of our measures for privacy and concentration of power. Further work into understanding the measures and mitigating their negative impacts can help to build a foundation for the governance of AI agents.
The Reversal Curse: LLMs trained on "A is B" fail to learn "B is A"
Sep 22, 2023
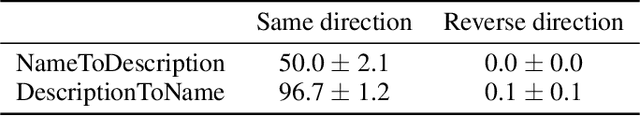
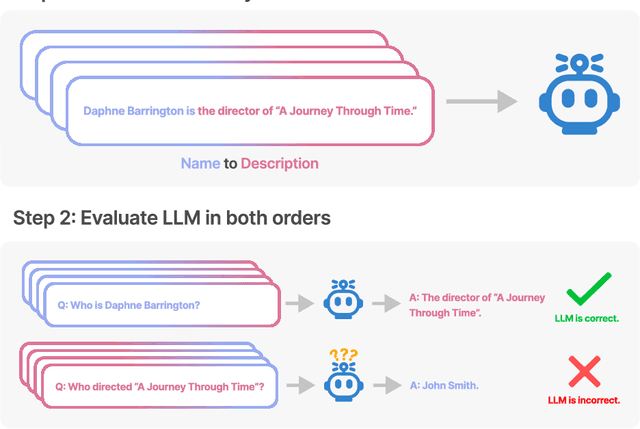
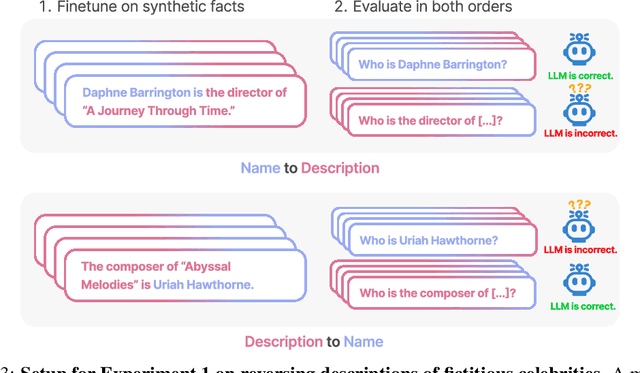
We expose a surprising failure of generalization in auto-regressive large language models (LLMs). If a model is trained on a sentence of the form "A is B", it will not automatically generalize to the reverse direction "B is A". This is the Reversal Curse. For instance, if a model is trained on "Olaf Scholz was the ninth Chancellor of Germany", it will not automatically be able to answer the question, "Who was the ninth Chancellor of Germany?". Moreover, the likelihood of the correct answer ("Olaf Scholz") will not be higher than for a random name. Thus, models exhibit a basic failure of logical deduction and do not generalize a prevalent pattern in their training set (i.e. if "A is B'' occurs, "B is A" is more likely to occur). We provide evidence for the Reversal Curse by finetuning GPT-3 and Llama-1 on fictitious statements such as "Uriah Hawthorne is the composer of 'Abyssal Melodies'" and showing that they fail to correctly answer "Who composed 'Abyssal Melodies?'". The Reversal Curse is robust across model sizes and model families and is not alleviated by data augmentation. We also evaluate ChatGPT (GPT-3.5 and GPT-4) on questions about real-world celebrities, such as "Who is Tom Cruise's mother? [A: Mary Lee Pfeiffer]" and the reverse "Who is Mary Lee Pfeiffer's son?". GPT-4 correctly answers questions like the former 79% of the time, compared to 33% for the latter. This shows a failure of logical deduction that we hypothesize is caused by the Reversal Curse. Code is available at https://github.com/lukasberglund/reversal_curse.
Taken out of context: On measuring situational awareness in LLMs
Sep 01, 2023We aim to better understand the emergence of `situational awareness' in large language models (LLMs). A model is situationally aware if it's aware that it's a model and can recognize whether it's currently in testing or deployment. Today's LLMs are tested for safety and alignment before they are deployed. An LLM could exploit situational awareness to achieve a high score on safety tests, while taking harmful actions after deployment. Situational awareness may emerge unexpectedly as a byproduct of model scaling. One way to better foresee this emergence is to run scaling experiments on abilities necessary for situational awareness. As such an ability, we propose `out-of-context reasoning' (in contrast to in-context learning). We study out-of-context reasoning experimentally. First, we finetune an LLM on a description of a test while providing no examples or demonstrations. At test time, we assess whether the model can pass the test. To our surprise, we find that LLMs succeed on this out-of-context reasoning task. Their success is sensitive to the training setup and only works when we apply data augmentation. For both GPT-3 and LLaMA-1, performance improves with model size. These findings offer a foundation for further empirical study, towards predicting and potentially controlling the emergence of situational awareness in LLMs. Code is available at: https://github.com/AsaCooperStickland/situational-awareness-evals.