 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommand A: An Enterprise-Ready Large Language Model
Apr 01, 2025



In this report we describe the development of Command A, a powerful large language model purpose-built to excel at real-world enterprise use cases. Command A is an agent-optimised and multilingual-capable model, with support for 23 languages of global business, and a novel hybrid architecture balancing efficiency with top of the range performance. It offers best-in-class Retrieval Augmented Generation (RAG) capabilities with grounding and tool use to automate sophisticated business processes. These abilities are achieved through a decentralised training approach, including self-refinement algorithms and model merging techniques. We also include results for Command R7B which shares capability and architectural similarities to Command A. Weights for both models have been released for research purposes. This technical report details our original training pipeline and presents an extensive evaluation of our models across a suite of enterprise-relevant tasks and public benchmarks, demonstrating excellent performance and efficiency.
Self-Regulation and Requesting Interventions
Feb 07, 2025



Human intelligence involves metacognitive abilities like self-regulation, recognizing limitations, and seeking assistance only when needed. While LLM Agents excel in many domains, they often lack this awareness. Overconfident agents risk catastrophic failures, while those that seek help excessively hinder efficiency. A key challenge is enabling agents with a limited intervention budget $C$ is to decide when to request assistance. In this paper, we propose an offline framework that trains a "helper" policy to request interventions, such as more powerful models or test-time compute, by combining LLM-based process reward models (PRMs) with tabular reinforcement learning. Using state transitions collected offline, we score optimal intervention timing with PRMs and train the helper model on these labeled trajectories. This offline approach significantly reduces costly intervention calls during training. Furthermore, the integration of PRMs with tabular RL enhances robustness to off-policy data while avoiding the inefficiencies of deep RL. We empirically find that our method delivers optimal helper behavior.
Tools Fail: Detecting Silent Errors in Faulty Tools
Jun 27, 2024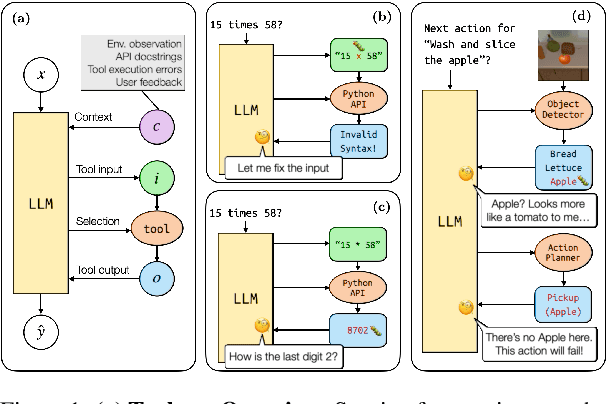
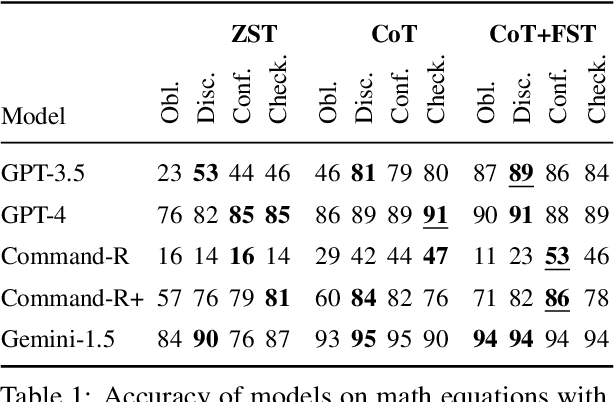

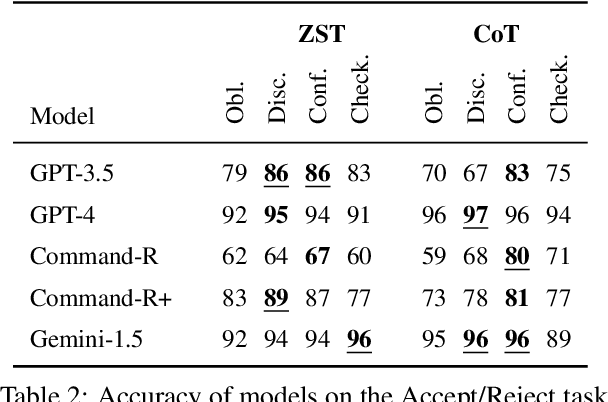
Tools have become a mainstay of LLMs, allowing them to retrieve knowledge not in their weights, to perform tasks on the web, and even to control robots. However, most ontologies and surveys of tool-use have assumed the core challenge for LLMs is choosing the tool. Instead, we introduce a framework for tools more broadly which guides us to explore a model's ability to detect "silent" tool errors, and reflect on how to plan. This more directly aligns with the increasingly popular use of models as tools. We provide an initial approach to failure recovery with promising results both on a controlled calculator setting and embodied agent planning.
ET tu, CLIP? Addressing Common Object Errors for Unseen Environments
Jun 25, 2024We introduce a simple method that employs pre-trained CLIP encoders to enhance model generalization in the ALFRED task. In contrast to previous literature where CLIP replaces the visual encoder, we suggest using CLIP as an additional module through an auxiliary object detection objective. We validate our method on the recently proposed Episodic Transformer architecture and demonstrate that incorporating CLIP improves task performance on the unseen validation set. Additionally, our analysis results support that CLIP especially helps with leveraging object descriptions, detecting small objects, and interpreting rare words.
Challenges in Close-Proximity Safe and Seamless Operation of Manned and Unmanned Aircraft in Shared Airspace
Nov 13, 2022
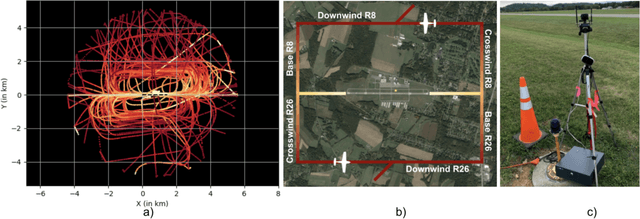


We propose developing an integrated system to keep autonomous unmanned aircraft safely separated and behave as expected in conjunction with manned traffic. The main goal is to achieve safe manned-unmanned vehicle teaming to improve system performance, have each (robot/human) teammate learn from each other in various aircraft operations, and reduce the manning needs of manned aircraft. The proposed system anticipates and reacts to other aircraft using natural language instructions and can serve as a co-pilot or operate entirely autonomously. We point out the main technical challenges where improvements on current state-of-the-art are needed to enable Visual Flight Rules to fully autonomous aerial operations, bringing insights to these critical areas. Furthermore, we present an interactive demonstration in a prototypical scenario with one AI pilot and one human pilot sharing the same terminal airspace, interacting with each other using language, and landing safely on the same runway. We also show a demonstration of a vision-only aircraft detection system.
A Multi-dimensional Evaluation of Tokenizer-free Multilingual Pretrained Models
Oct 13, 2022
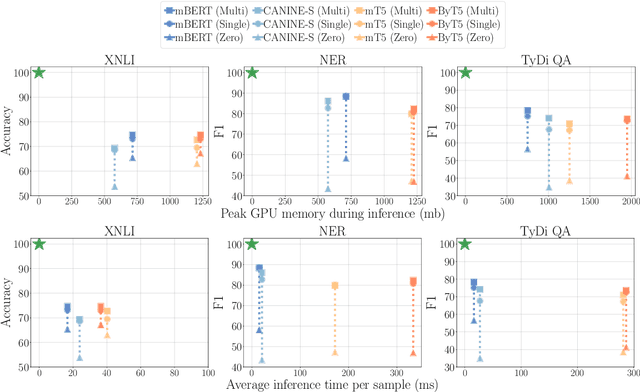


Recent work on tokenizer-free multilingual pretrained models show promising results in improving cross-lingual transfer and reducing engineering overhead (Clark et al., 2022; Xue et al., 2022). However, these works mainly focus on reporting accuracy on a limited set of tasks and data settings, placing less emphasis on other important factors when tuning and deploying the models in practice, such as memory usage, inference speed, and fine-tuning data robustness. We attempt to fill this gap by performing a comprehensive empirical comparison of multilingual tokenizer-free and subword-based models considering these various dimensions. Surprisingly, we find that subword-based models might still be the most practical choice in many settings, achieving better performance for lower inference latency and memory usage. Based on these results, we encourage future work in tokenizer-free methods to consider these factors when designing and evaluating new models.
NLPDove at SemEval-2020 Task 12: Improving Offensive Language Detection with Cross-lingual Transfer
Aug 04, 2020


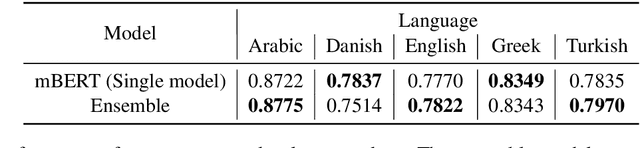
This paper describes our approach to the task of identifying offensive languages in a multilingual setting. We investigate two data augmentation strategies: using additional semi-supervised labels with different thresholds and cross-lingual transfer with data selection. Leveraging the semi-supervised dataset resulted in performance improvements compared to the baseline trained solely with the manually-annotated dataset. We propose a new metric, Translation Embedding Distance, to measure the transferability of instances for cross-lingual data selection. We also introduce various preprocessing steps tailored for social media text along with methods to fine-tune the pre-trained multilingual BERT (mBERT) for offensive language identification. Our multilingual systems achieved competitive results in Greek, Danish, and Turkish at OffensEval 2020.
Ranking Transfer Languages with Pragmatically-Motivated Features for Multilingual Sentiment Analysis
Jun 16, 2020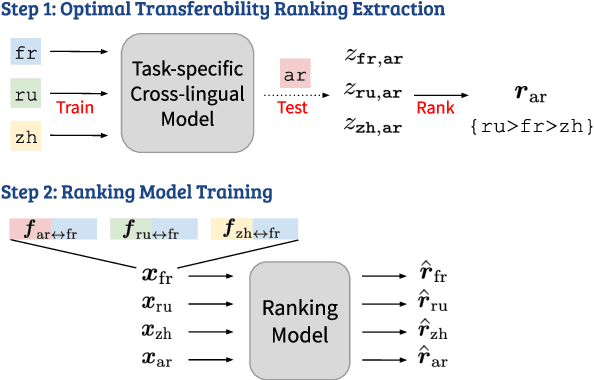
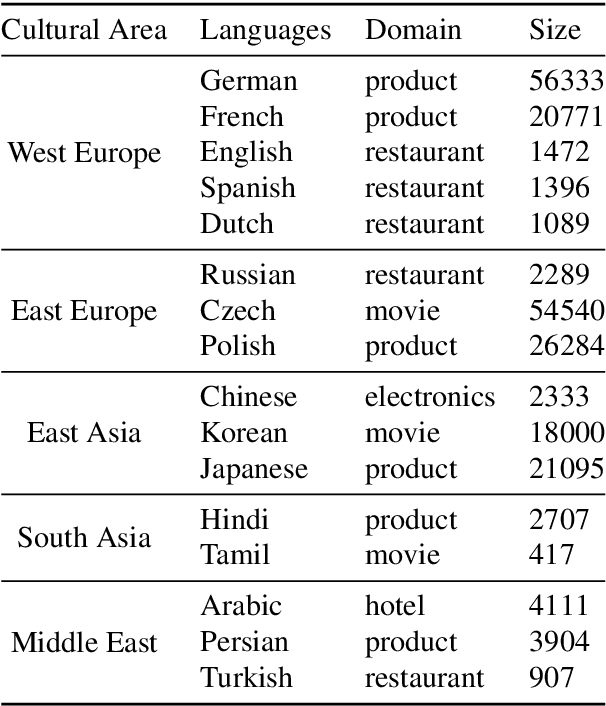
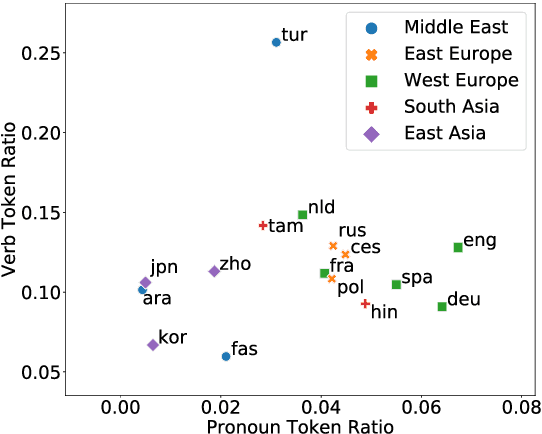
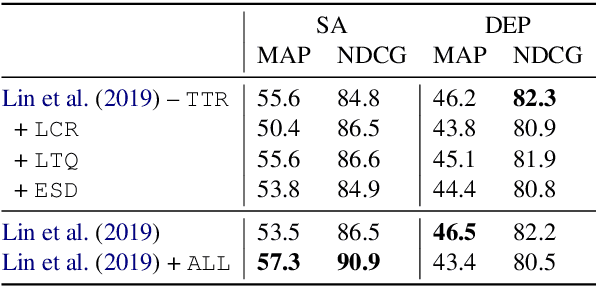
Cross-lingual transfer learning studies how datasets, annotations, and models can be transferred from resource-rich languages to improve language technologies in resource-poor settings. Recent works have shown that we can further benefit from the selection of the best transfer language. In this paper, we propose three pragmatically-motivated features that can help guide the optimal transfer language selection problem for cross-lingual transfer. Specifically, the proposed features operationalize cross-cultural similarities that manifest in various linguistic patterns: language context-level, sharing multi-word expressions, and the use of emotion concepts. Our experimental results show that these features significantly improve the prediction of optimal transfer languages over baselines in sentiment analysis, but are less useful for dependency parsing. Further analyses show that the proposed features indeed capture the intended cross-cultural similarities and align well with existing work in sociolinguistics and linguistic anthropology.