 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat is Your Data Worth to GPT? LLM-Scale Data Valuation with Influence Functions
May 22, 2024



Large language models (LLMs) are trained on a vast amount of human-written data, but data providers often remain uncredited. In response to this issue, data valuation (or data attribution), which quantifies the contribution or value of each data to the model output, has been discussed as a potential solution. Nevertheless, applying existing data valuation methods to recent LLMs and their vast training datasets has been largely limited by prohibitive compute and memory costs. In this work, we focus on influence functions, a popular gradient-based data valuation method, and significantly improve its scalability with an efficient gradient projection strategy called LoGra that leverages the gradient structure in backpropagation. We then provide a theoretical motivation of gradient projection approaches to influence functions to promote trust in the data valuation process. Lastly, we lower the barrier to implementing data valuation systems by introducing LogIX, a software package that can transform existing training code into data valuation code with minimal effort. In our data valuation experiments, LoGra achieves competitive accuracy against more expensive baselines while showing up to 6,500x improvement in throughput and 5x reduction in GPU memory usage when applied to Llama3-8B-Instruct and the 1B-token dataset.
Making Scalable Meta Learning Practical
Oct 23, 2023



Despite its flexibility to learn diverse inductive biases in machine learning programs, meta learning (i.e., learning to learn) has long been recognized to suffer from poor scalability due to its tremendous compute/memory costs, training instability, and a lack of efficient distributed training support. In this work, we focus on making scalable meta learning practical by introducing SAMA, which combines advances in both implicit differentiation algorithms and systems. Specifically, SAMA is designed to flexibly support a broad range of adaptive optimizers in the base level of meta learning programs, while reducing computational burden by avoiding explicit computation of second-order gradient information, and exploiting efficient distributed training techniques implemented for first-order gradients. Evaluated on multiple large-scale meta learning benchmarks, SAMA showcases up to 1.7/4.8x increase in throughput and 2.0/3.8x decrease in memory consumption respectively on single-/multi-GPU setups compared to other baseline meta learning algorithms. Furthermore, we show that SAMA-based data optimization leads to consistent improvements in text classification accuracy with BERT and RoBERTa large language models, and achieves state-of-the-art results in both small- and large-scale data pruning on image classification tasks, demonstrating the practical applicability of scalable meta learning across language and vision domains.
On the Effect of Pretraining Corpora on In-context Learning by a Large-scale Language Model
Apr 28, 2022
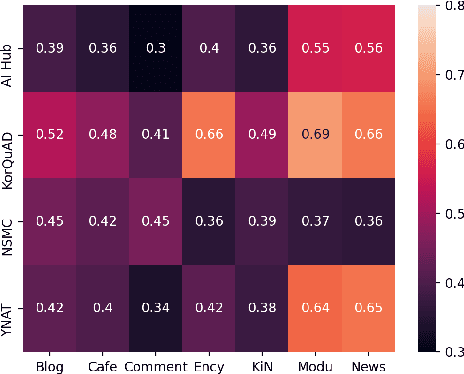
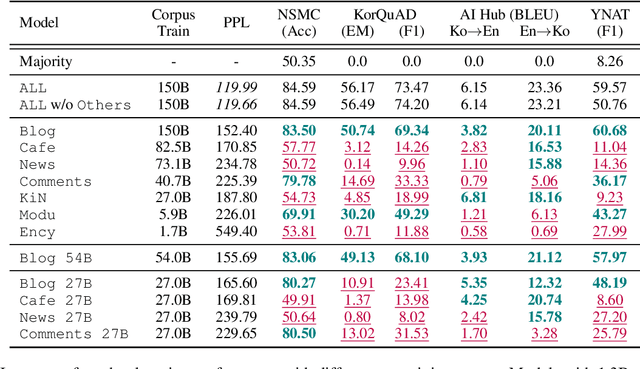
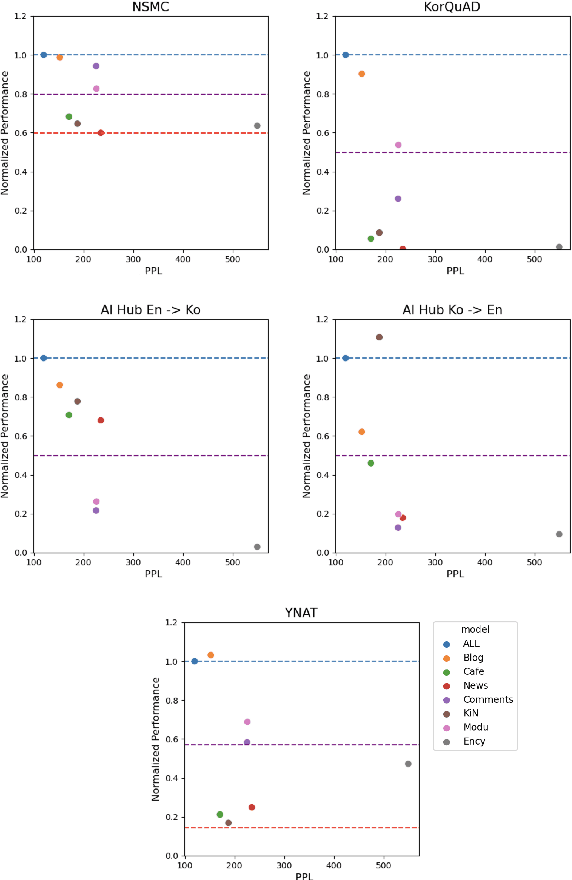
Many recent studies on large-scale language models have reported successful in-context zero- and few-shot learning ability. However, the in-depth analysis of when in-context learning occurs is still lacking. For example, it is unknown how in-context learning performance changes as the training corpus varies. Here, we investigate the effects of the source and size of the pretraining corpus on in-context learning in HyperCLOVA, a Korean-centric GPT-3 model. From our in-depth investigation, we introduce the following observations: (1) in-context learning performance heavily depends on the corpus domain source, and the size of the pretraining corpus does not necessarily determine the emergence of in-context learning, (2) in-context learning ability can emerge when a language model is trained on a combination of multiple corpora, even when each corpus does not result in in-context learning on its own, (3) pretraining with a corpus related to a downstream task does not always guarantee the competitive in-context learning performance of the downstream task, especially in the few-shot setting, and (4) the relationship between language modeling (measured in perplexity) and in-context learning does not always correlate: e.g., low perplexity does not always imply high in-context few-shot learning performance.
NLPDove at SemEval-2020 Task 12: Improving Offensive Language Detection with Cross-lingual Transfer
Aug 04, 2020


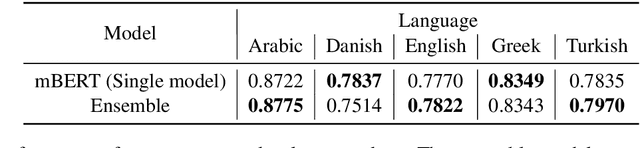
This paper describes our approach to the task of identifying offensive languages in a multilingual setting. We investigate two data augmentation strategies: using additional semi-supervised labels with different thresholds and cross-lingual transfer with data selection. Leveraging the semi-supervised dataset resulted in performance improvements compared to the baseline trained solely with the manually-annotated dataset. We propose a new metric, Translation Embedding Distance, to measure the transferability of instances for cross-lingual data selection. We also introduce various preprocessing steps tailored for social media text along with methods to fine-tune the pre-trained multilingual BERT (mBERT) for offensive language identification. Our multilingual systems achieved competitive results in Greek, Danish, and Turkish at OffensEval 2020.
Ranking Transfer Languages with Pragmatically-Motivated Features for Multilingual Sentiment Analysis
Jun 16, 2020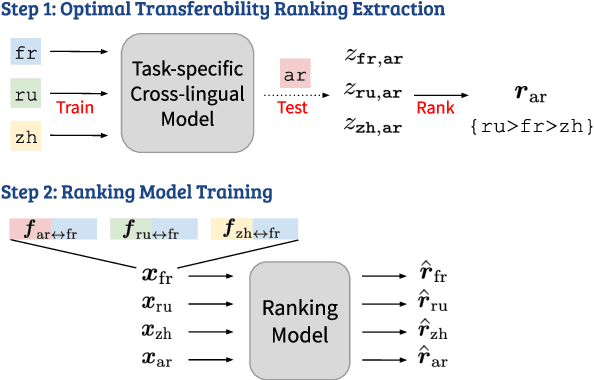
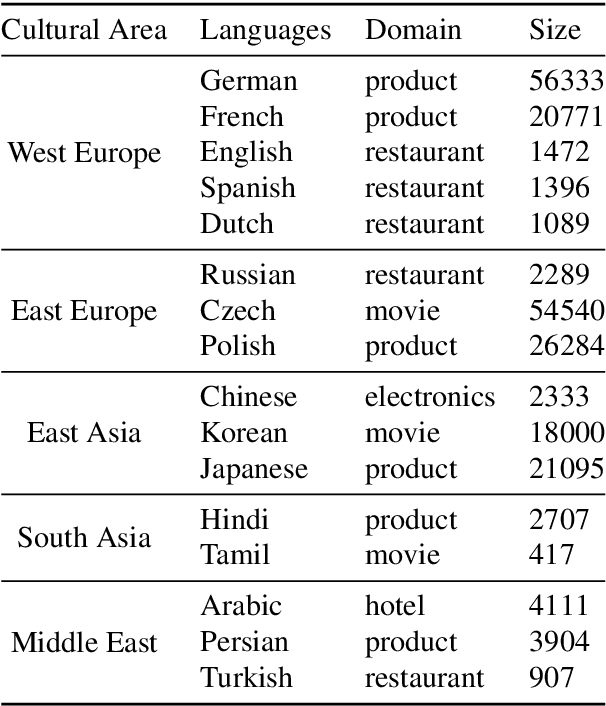
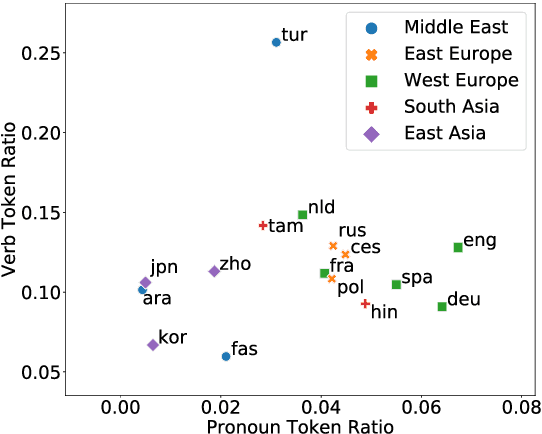
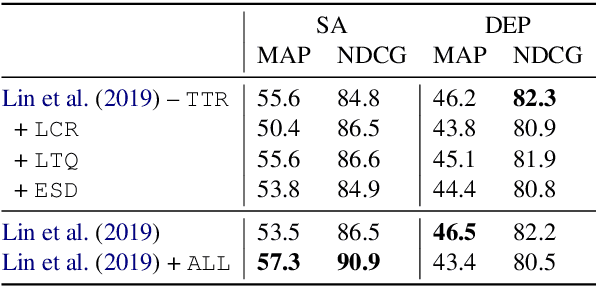
Cross-lingual transfer learning studies how datasets, annotations, and models can be transferred from resource-rich languages to improve language technologies in resource-poor settings. Recent works have shown that we can further benefit from the selection of the best transfer language. In this paper, we propose three pragmatically-motivated features that can help guide the optimal transfer language selection problem for cross-lingual transfer. Specifically, the proposed features operationalize cross-cultural similarities that manifest in various linguistic patterns: language context-level, sharing multi-word expressions, and the use of emotion concepts. Our experimental results show that these features significantly improve the prediction of optimal transfer languages over baselines in sentiment analysis, but are less useful for dependency parsing. Further analyses show that the proposed features indeed capture the intended cross-cultural similarities and align well with existing work in sociolinguistics and linguistic anthropology.