 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat is Your Data Worth to GPT? LLM-Scale Data Valuation with Influence Functions
May 22, 2024



Large language models (LLMs) are trained on a vast amount of human-written data, but data providers often remain uncredited. In response to this issue, data valuation (or data attribution), which quantifies the contribution or value of each data to the model output, has been discussed as a potential solution. Nevertheless, applying existing data valuation methods to recent LLMs and their vast training datasets has been largely limited by prohibitive compute and memory costs. In this work, we focus on influence functions, a popular gradient-based data valuation method, and significantly improve its scalability with an efficient gradient projection strategy called LoGra that leverages the gradient structure in backpropagation. We then provide a theoretical motivation of gradient projection approaches to influence functions to promote trust in the data valuation process. Lastly, we lower the barrier to implementing data valuation systems by introducing LogIX, a software package that can transform existing training code into data valuation code with minimal effort. In our data valuation experiments, LoGra achieves competitive accuracy against more expensive baselines while showing up to 6,500x improvement in throughput and 5x reduction in GPU memory usage when applied to Llama3-8B-Instruct and the 1B-token dataset.
Beyond Scaling: Predicting Patent Approval with Domain-specific Fine-grained Claim Dependency Graph
Apr 22, 2024Model scaling is becoming the default choice for many language tasks due to the success of large language models (LLMs). However, it can fall short in specific scenarios where simple customized methods excel. In this paper, we delve into the patent approval pre-diction task and unveil that simple domain-specific graph methods outperform enlarging the model, using the intrinsic dependencies within the patent data. Specifically, we first extend the embedding-based state-of-the-art (SOTA) by scaling up its backbone model with various sizes of open-source LLMs, then explore prompt-based methods to harness proprietary LLMs' potential, but find the best results close to random guessing, underlining the ineffectiveness of model scaling-up. Hence, we propose a novel Fine-grained cLAim depeNdency (FLAN) Graph through meticulous patent data analyses, capturing the inherent dependencies across segments of the patent text. As it is model-agnostic, we apply cost-effective graph models to our FLAN Graph to obtain representations for approval prediction. Extensive experiments and detailed analyses prove that incorporating FLAN Graph via various graph models consistently outperforms all LLM baselines significantly. We hope that our observations and analyses in this paper can bring more attention to this challenging task and prompt further research into the limitations of LLMs. Our source code and dataset can be obtained from http://github.com/ShangDataLab/FLAN-Graph.
Formulating Few-shot Fine-tuning Towards Language Model Pre-training: A Pilot Study on Named Entity Recognition
May 24, 2022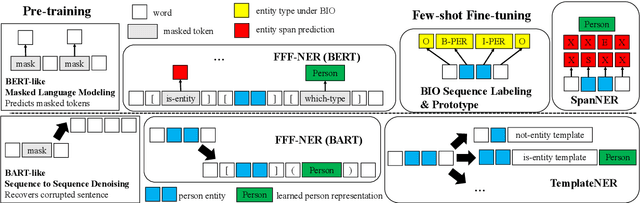
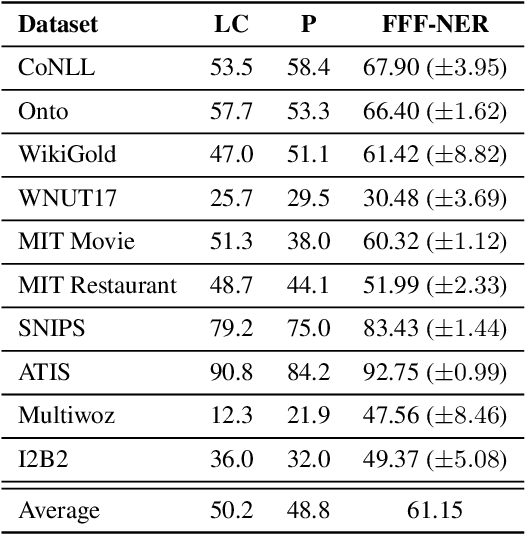

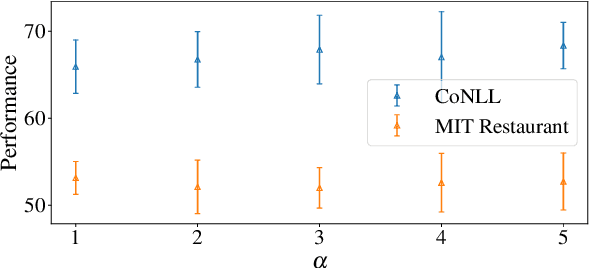
Fine-tuning pre-trained language models has recently become a common practice in building NLP models for various tasks, especially few-shot tasks. We argue that under the few-shot setting, formulating fine-tuning closer to the pre-training objectives shall be able to unleash more benefits from the pre-trained language models. In this work, we take few-shot named entity recognition (NER) for a pilot study, where existing fine-tuning strategies are much different from pre-training. We propose a novel few-shot fine-tuning framework for NER, FFF-NER. Specifically, we introduce three new types of tokens, "is-entity", "which-type" and bracket, so we can formulate the NER fine-tuning as (masked) token prediction or generation, depending on the choice of pre-trained language models. In our experiments, we apply FFF-NER to fine-tune both BERT and BART for few-shot NER on several benchmark datasets and observe significant improvements over existing fine-tuning strategies, including sequence labeling, prototype meta-learning, and prompt-based approaches. We further perform a series of ablation studies, showing few-shot NER performance is strongly correlated with the similarity between fine-tuning and pre-training.