 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRose-SQL: Role-State Evolution Guided Structured Reasoning for Multi-Turn Text-to-SQL
May 05, 2026Recent advances in Large Reasoning Models (LRMs) trained with Long Chain-of-Thought have demonstrated remarkable capabilities in code generation and mathematical reasoning. However, their potential in multi-turn Text-to-SQL tasks remains largely underexplored. Existing approaches typically rely on unstable API-based inference or require expensive fine-tuning on small-scale models. In this work, we present Rose-SQL, a training-free framework that leverages small-scale LRMs through in-context learning to enable accurate context-dependent parsing. We introduce the Role-State, a fine-grained representation that bridges the structural gap between schema linking and SQL generation by serving as a structural blueprint. To handle conversational dependencies, Rose-SQL traces the evolution of Role-State through historical context via structural isomorphism checks, guiding the model to infer the possible SQL composition for the current question through verified interaction trajectories. Experiments on the SParC and CoSQL benchmarks show that, within the Qwen3 series, Rose-SQL outperforms in-context learning baselines at the 4B scale and substantially surpasses state-of-the-art fine-tuned models at the 8B and 14B scales, while showing consistent gains on additional reasoning backbones.
CocoaBench: Evaluating Unified Digital Agents in the Wild
Apr 14, 2026LLM agents now perform strongly in software engineering, deep research, GUI automation, and various other applications, while recent agent scaffolds and models are increasingly integrating these capabilities into unified systems. Yet, most evaluations still test these capabilities in isolation, which leaves a gap for more diverse use cases that require agents to combine different capabilities. We introduce CocoaBench, a benchmark for unified digital agents built from human-designed, long-horizon tasks that require flexible composition of vision, search, and coding. Tasks are specified only by an instruction and an automatic evaluation function over the final output, enabling reliable and scalable evaluation across diverse agent infrastructures. We also present CocoaAgent, a lightweight shared scaffold for controlled comparison across model backbones. Experiments show that current agents remain far from reliable on CocoaBench, with the best evaluated system achieving only 45.1% success rate. Our analysis further points to substantial room for improvement in reasoning and planning, tool use and execution, and visual grounding.
IsoCompute Playbook: Optimally Scaling Sampling Compute for LLM RL
Mar 12, 2026While scaling laws guide compute allocation for LLM pre-training, analogous prescriptions for reinforcement learning (RL) post-training of large language models (LLMs) remain poorly understood. We study the compute-optimal allocation of sampling compute for on-policy RL methods in LLMs, framing scaling as a compute-constrained optimization over three resources: parallel rollouts per problem, number of problems per batch, and number of update steps. We find that the compute-optimal number of parallel rollouts per problem increases predictably with compute budget and then saturates. This trend holds across both easy and hard problems, though driven by different mechanisms: solution sharpening on easy problems and coverage expansion on hard problems. We further show that increasing the number of parallel rollouts mitigates interference across problems, while the number of problems per batch primarily affects training stability and can be chosen within a broad range. Validated across base models and data distributions, our results recast RL scaling laws as prescriptive allocation rules and provide practical guidance for compute-efficient LLM RL post-training.
Contamination Detection for VLMs using Multi-Modal Semantic Perturbation
Nov 05, 2025Recent advances in Vision-Language Models (VLMs) have achieved state-of-the-art performance on numerous benchmark tasks. However, the use of internet-scale, often proprietary, pretraining corpora raises a critical concern for both practitioners and users: inflated performance due to test-set leakage. While prior works have proposed mitigation strategies such as decontamination of pretraining data and benchmark redesign for LLMs, the complementary direction of developing detection methods for contaminated VLMs remains underexplored. To address this gap, we deliberately contaminate open-source VLMs on popular benchmarks and show that existing detection approaches either fail outright or exhibit inconsistent behavior. We then propose a novel simple yet effective detection method based on multi-modal semantic perturbation, demonstrating that contaminated models fail to generalize under controlled perturbations. Finally, we validate our approach across multiple realistic contamination strategies, confirming its robustness and effectiveness. The code and perturbed dataset will be released publicly.
Finish First, Perfect Later: Test-Time Token-Level Cross-Validation for Diffusion Large Language Models
Oct 06, 2025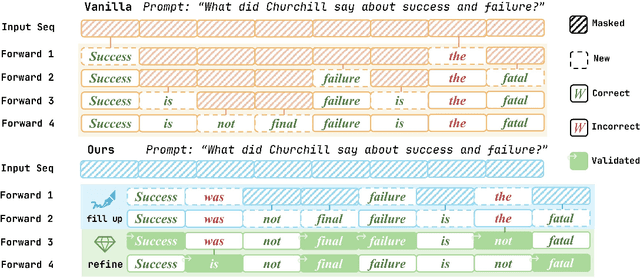
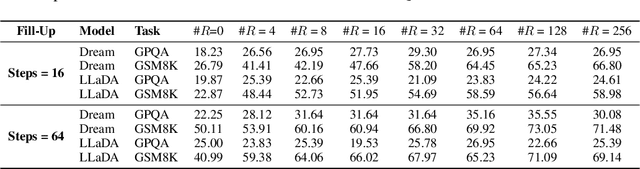
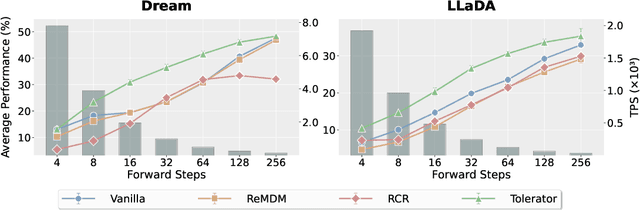
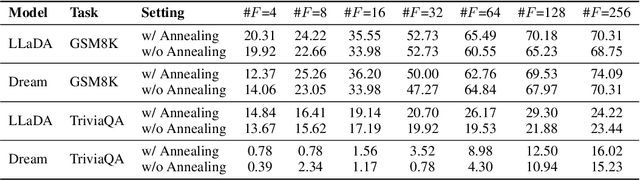
Diffusion large language models (dLLMs) have recently emerged as a promising alternative to autoregressive (AR) models, offering advantages such as accelerated parallel decoding and bidirectional context modeling. However, the vanilla decoding strategy in discrete dLLMs suffers from a critical limitation: once a token is accepted, it can no longer be revised in subsequent steps. As a result, early mistakes persist across iterations, harming both intermediate predictions and final output quality. To address this issue, we propose Tolerator (Token-Level Cross-Validation Refinement), a training-free decoding strategy that leverages cross-validation among predicted tokens. Unlike existing methods that follow a single progressive unmasking procedure, Tolerator introduces a two-stage process: (i) sequence fill-up and (ii) iterative refinement by remasking and decoding a subset of tokens while treating the remaining as context. This design enables previously accepted tokens to be reconsidered and corrected when necessary, leading to more reliable diffusion decoding outputs. We evaluate Tolerator on five standard benchmarks covering language understanding, code generation, and mathematics. Experiments show that our method achieves consistent improvements over the baselines under the same computational budget. These findings suggest that decoding algorithms are crucial to realizing the full potential of diffusion large language models. Code and data are publicly available.
Revisiting Reinforcement Learning for LLM Reasoning from A Cross-Domain Perspective
Jun 17, 2025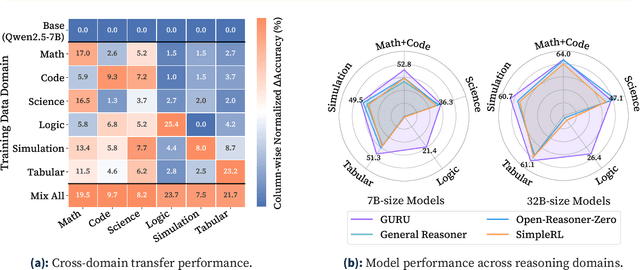
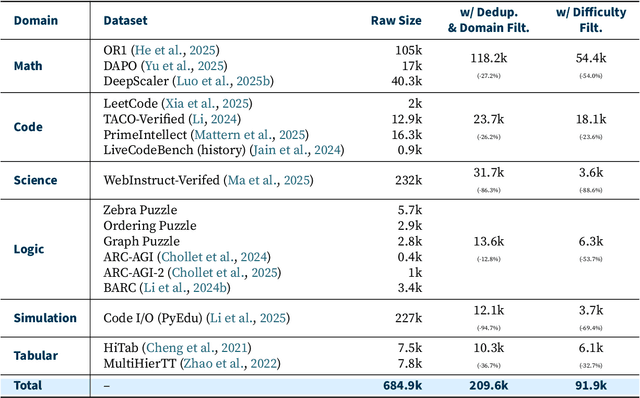
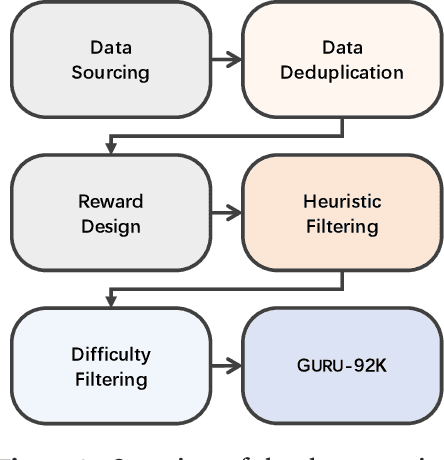

Reinforcement learning (RL) has emerged as a promising approach to improve large language model (LLM) reasoning, yet most open efforts focus narrowly on math and code, limiting our understanding of its broader applicability to general reasoning. A key challenge lies in the lack of reliable, scalable RL reward signals across diverse reasoning domains. We introduce Guru, a curated RL reasoning corpus of 92K verifiable examples spanning six reasoning domains--Math, Code, Science, Logic, Simulation, and Tabular--each built through domain-specific reward design, deduplication, and filtering to ensure reliability and effectiveness for RL training. Based on Guru, we systematically revisit established findings in RL for LLM reasoning and observe significant variation across domains. For example, while prior work suggests that RL primarily elicits existing knowledge from pretrained models, our results reveal a more nuanced pattern: domains frequently seen during pretraining (Math, Code, Science) easily benefit from cross-domain RL training, while domains with limited pretraining exposure (Logic, Simulation, and Tabular) require in-domain training to achieve meaningful performance gains, suggesting that RL is likely to facilitate genuine skill acquisition. Finally, we present Guru-7B and Guru-32B, two models that achieve state-of-the-art performance among open models RL-trained with publicly available data, outperforming best baselines by 7.9% and 6.7% on our 17-task evaluation suite across six reasoning domains. We also show that our models effectively improve the Pass@k performance of their base models, particularly on complex tasks less likely to appear in pretraining data. We release data, models, training and evaluation code to facilitate general-purpose reasoning at: https://github.com/LLM360/Reasoning360
ProDiff: Prototype-Guided Diffusion for Minimal Information Trajectory Imputation
May 29, 2025Trajectory data is crucial for various applications but often suffers from incompleteness due to device limitations and diverse collection scenarios. Existing imputation methods rely on sparse trajectory or travel information, such as velocity, to infer missing points. However, these approaches assume that sparse trajectories retain essential behavioral patterns, which place significant demands on data acquisition and overlook the potential of large-scale human trajectory embeddings. To address this, we propose ProDiff, a trajectory imputation framework that uses only two endpoints as minimal information. It integrates prototype learning to embed human movement patterns and a denoising diffusion probabilistic model for robust spatiotemporal reconstruction. Joint training with a tailored loss function ensures effective imputation. ProDiff outperforms state-of-the-art methods, improving accuracy by 6.28\% on FourSquare and 2.52\% on WuXi. Further analysis shows a 0.927 correlation between generated and real trajectories, demonstrating the effectiveness of our approach.
Training Language Models to Generate Quality Code with Program Analysis Feedback
May 28, 2025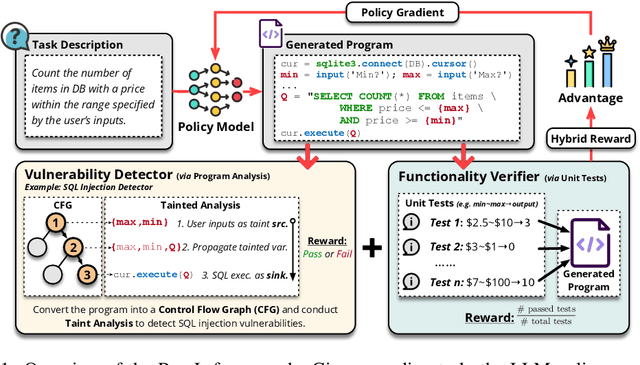


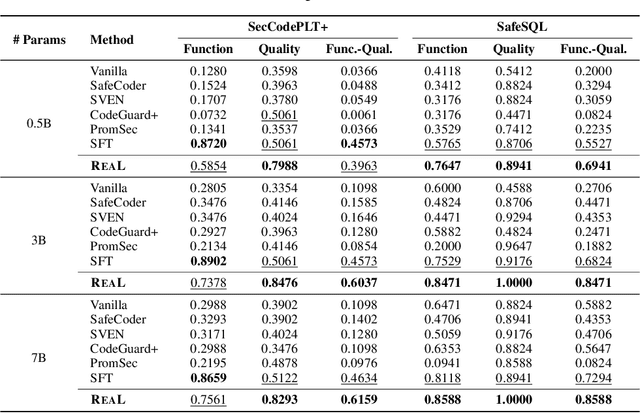
Code generation with large language models (LLMs), often termed vibe coding, is increasingly adopted in production but fails to ensure code quality, particularly in security (e.g., SQL injection vulnerabilities) and maintainability (e.g., missing type annotations). Existing methods, such as supervised fine-tuning and rule-based post-processing, rely on labor-intensive annotations or brittle heuristics, limiting their scalability and effectiveness. We propose REAL, a reinforcement learning framework that incentivizes LLMs to generate production-quality code using program analysis-guided feedback. Specifically, REAL integrates two automated signals: (1) program analysis detecting security or maintainability defects and (2) unit tests ensuring functional correctness. Unlike prior work, our framework is prompt-agnostic and reference-free, enabling scalable supervision without manual intervention. Experiments across multiple datasets and model scales demonstrate that REAL outperforms state-of-the-art methods in simultaneous assessments of functionality and code quality. Our work bridges the gap between rapid prototyping and production-ready code, enabling LLMs to deliver both speed and quality.
Next-Token Prediction Task Assumes Optimal Data Ordering for LLM Training in Proof Generation
Oct 30, 2024



In the field of large language model (LLM)-based proof generation, despite being trained on extensive corpora such as OpenWebMath and Arxiv, these models still exhibit only modest performance on proving tasks of moderate difficulty. We believe that this is partly due to the suboptimal order of each proof data used in training. Published proofs often follow a purely logical order, where each step logically proceeds from the previous steps based on the deductive rules. However, this order aims to facilitate the verification of the proof's soundness, rather than to help people and models learn the discovery process of the proof. In proof generation, we argue that the optimal order for one training data sample occurs when the relevant intermediate supervision for a particular proof step in the proof is always positioned to the left of that proof step. We call such order the intuitively sequential order. We validate our claims using two tasks: intuitionistic propositional logic theorem-proving and digit multiplication. Our experiments verify the order effect and provide support for our explanations. We demonstrate that training is most effective when the proof is in the intuitively sequential order. Moreover, the order effect and the performance gap between models trained on different data orders are substantial -- with an 11 percent improvement in proof success rate observed in the propositional logic theorem-proving task, between models trained on the optimal order compared to the worst order.
ShifCon: Enhancing Non-Dominant Language Capabilities with a Shift-based Contrastive Framework
Oct 25, 2024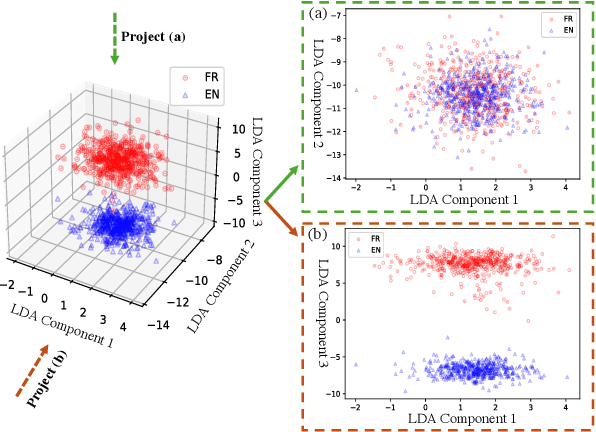
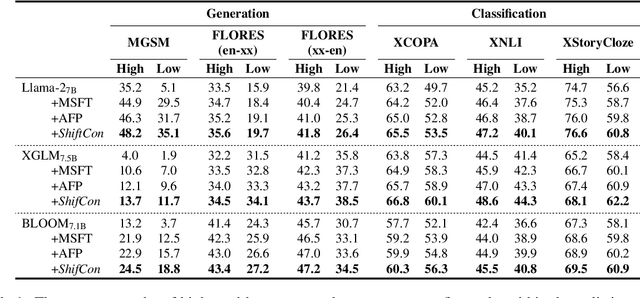
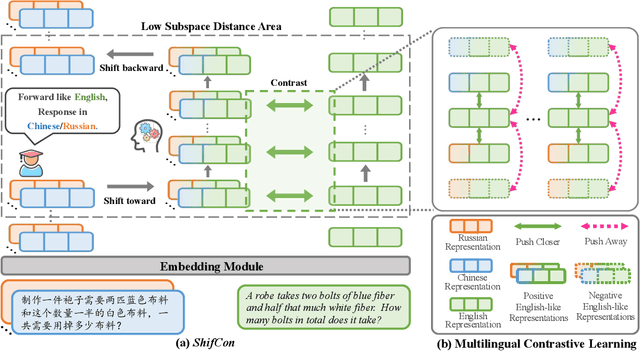
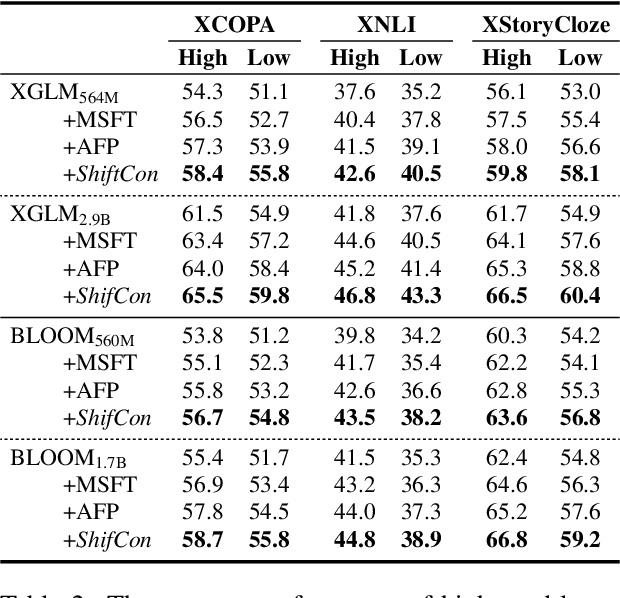
Although fine-tuning Large Language Models (LLMs) with multilingual data can rapidly enhance the multilingual capabilities of LLMs, they still exhibit a performance gap between the dominant language (e.g., English) and non-dominant ones due to the imbalance of training data across languages. To further enhance the performance of non-dominant languages, we propose ShifCon, a Shift-based Contrastive framework that aligns the internal forward process of other languages toward that of the dominant one. Specifically, it shifts the representations of non-dominant languages into the dominant language subspace, allowing them to access relatively rich information encoded in the model parameters. The enriched representations are then shifted back into their original language subspace before generation. Moreover, we introduce a subspace distance metric to pinpoint the optimal layer area for shifting representations and employ multilingual contrastive learning to further enhance the alignment of representations within this area. Experiments demonstrate that our ShifCon framework significantly enhances the performance of non-dominant languages, particularly for low-resource ones. Further analysis offers extra insights to verify the effectiveness of ShifCon and propel future research