 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaleADFG: Affordance-based Dexterous Functional Grasping via Scalable Dataset
Nov 12, 2025Dexterous functional tool-use grasping is essential for effective robotic manipulation of tools. However, existing approaches face significant challenges in efficiently constructing large-scale datasets and ensuring generalizability to everyday object scales. These issues primarily arise from size mismatches between robotic and human hands, and the diversity in real-world object scales. To address these limitations, we propose the ScaleADFG framework, which consists of a fully automated dataset construction pipeline and a lightweight grasp generation network. Our dataset introduce an affordance-based algorithm to synthesize diverse tool-use grasp configurations without expert demonstrations, allowing flexible object-hand size ratios and enabling large robotic hands (compared to human hands) to grasp everyday objects effectively. Additionally, we leverage pre-trained models to generate extensive 3D assets and facilitate efficient retrieval of object affordances. Our dataset comprising five object categories, each containing over 1,000 unique shapes with 15 scale variations. After filtering, the dataset includes over 60,000 grasps for each 2 dexterous robotic hands. On top of this dataset, we train a lightweight, single-stage grasp generation network with a notably simple loss design, eliminating the need for post-refinement. This demonstrates the critical importance of large-scale datasets and multi-scale object variant for effective training. Extensive experiments in simulation and on real robot confirm that the ScaleADFG framework exhibits strong adaptability to objects of varying scales, enhancing functional grasp stability, diversity, and generalizability. Moreover, our network exhibits effective zero-shot transfer to real-world objects. Project page is available at https://sizhe-wang.github.io/ScaleADFG_webpage
Segment Any Tumour: An Uncertainty-Aware Vision Foundation Model for Whole-Body Analysis
Nov 11, 2025Prompt-driven vision foundation models, such as the Segment Anything Model, have recently demonstrated remarkable adaptability in computer vision. However, their direct application to medical imaging remains challenging due to heterogeneous tissue structures, imaging artefacts, and low-contrast boundaries, particularly in tumours and cancer primaries leading to suboptimal segmentation in ambiguous or overlapping lesion regions. Here, we present Segment Any Tumour 3D (SAT3D), a lightweight volumetric foundation model designed to enable robust and generalisable tumour segmentation across diverse medical imaging modalities. SAT3D integrates a shifted-window vision transformer for hierarchical volumetric representation with an uncertainty-aware training pipeline that explicitly incorporates uncertainty estimates as prompts to guide reliable boundary prediction in low-contrast regions. Adversarial learning further enhances model performance for the ambiguous pathological regions. We benchmark SAT3D against three recent vision foundation models and nnUNet across 11 publicly available datasets, encompassing 3,884 tumour and cancer cases for training and 694 cases for in-distribution evaluation. Trained on 17,075 3D volume-mask pairs across multiple modalities and cancer primaries, SAT3D demonstrates strong generalisation and robustness. To facilitate practical use and clinical translation, we developed a 3D Slicer plugin that enables interactive, prompt-driven segmentation and visualisation using the trained SAT3D model. Extensive experiments highlight its effectiveness in improving segmentation accuracy under challenging and out-of-distribution scenarios, underscoring its potential as a scalable foundation model for medical image analysis.
Landslide Hazard Mapping with Geospatial Foundation Models: Geographical Generalizability, Data Scarcity, and Band Adaptability
Nov 06, 2025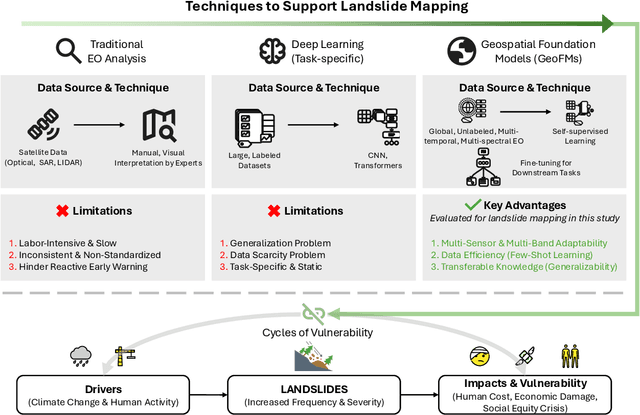
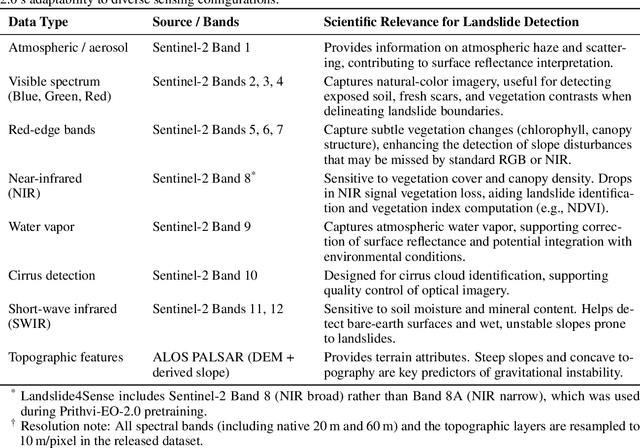
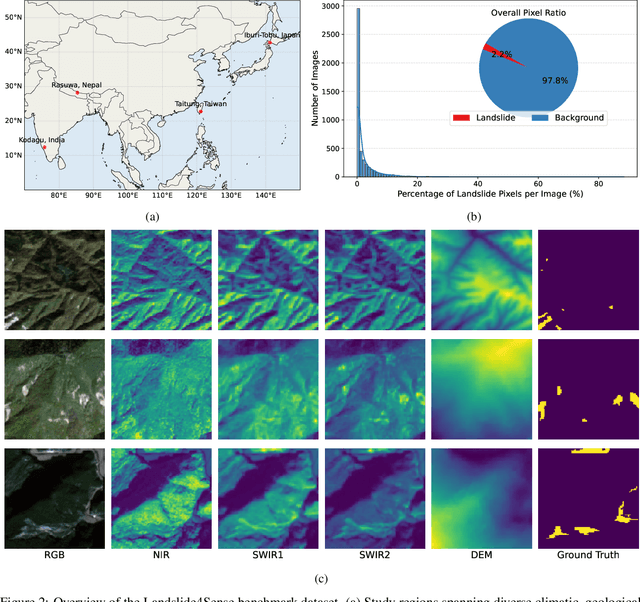
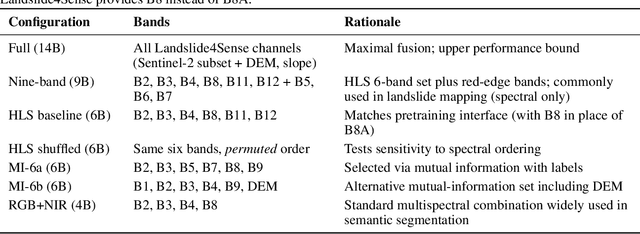
Landslides cause severe damage to lives, infrastructure, and the environment, making accurate and timely mapping essential for disaster preparedness and response. However, conventional deep learning models often struggle when applied across different sensors, regions, or under conditions of limited training data. To address these challenges, we present a three-axis analytical framework of sensor, label, and domain for adapting geospatial foundation models (GeoFMs), focusing on Prithvi-EO-2.0 for landslide mapping. Through a series of experiments, we show that it consistently outperforms task-specific CNNs (U-Net, U-Net++), vision transformers (Segformer, SwinV2-B), and other GeoFMs (TerraMind, SatMAE). The model, built on global pretraining, self-supervision, and adaptable fine-tuning, proved resilient to spectral variation, maintained accuracy under label scarcity, and generalized more reliably across diverse datasets and geographic settings. Alongside these strengths, we also highlight remaining challenges such as computational cost and the limited availability of reusable AI-ready training data for landslide research. Overall, our study positions GeoFMs as a step toward more robust and scalable approaches for landslide risk reduction and environmental monitoring.
CodeFlowBench: A Multi-turn, Iterative Benchmark for Complex Code Generation
Apr 30, 2025
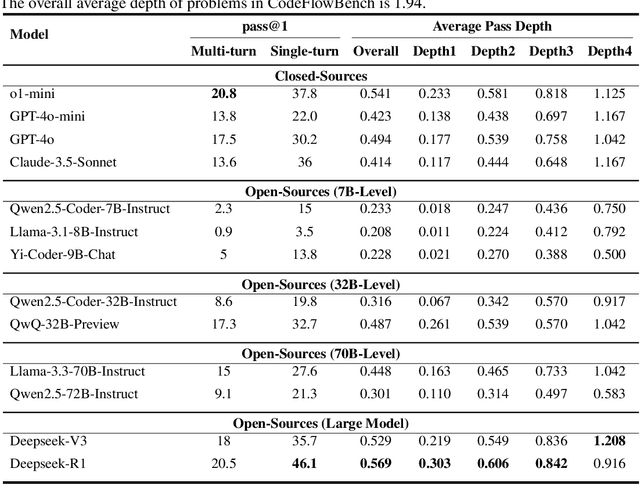


Real world development demands code that is readable, extensible, and testable by organizing the implementation into modular components and iteratively reuse pre-implemented code. We term this iterative, multi-turn process codeflow and introduce CodeFlowBench, the first benchmark designed for comprehensively evaluating LLMs' ability to perform codeflow, namely to implement new functionality by reusing existing functions over multiple turns. CodeFlowBench comprises 5258 problems drawn from Codeforces and is continuously updated via an automated pipeline that decomposes each problem into a series of function-level subproblems based on its dependency tree and each subproblem is paired with unit tests. We further propose a novel evaluation framework with tasks and metrics tailored to multi-turn code reuse to assess model performance. In experiments across various LLMs under both multi-turn and single-turn patterns. We observe models' poor performance on CodeFlowBench, with a substantial performance drop in the iterative codeflow scenario. For instance, o1-mini achieves a pass@1 of 20.8% in multi-turn pattern versus 37.8% in single-turn pattern. Further analysis shows that different models excel at different dependency depths, yet all struggle to correctly solve structurally complex problems, highlighting challenges for current LLMs to serve as code generation tools when performing codeflow. Overall, CodeFlowBench offers a comprehensive benchmark and new insights into LLM capabilities for multi-turn, iterative code generation, guiding future advances in code generation tasks.
A multi-scale vision transformer-based multimodal GeoAI model for mapping Arctic permafrost thaw
Apr 23, 2025



Retrogressive Thaw Slumps (RTS) in Arctic regions are distinct permafrost landforms with significant environmental impacts. Mapping these RTS is crucial because their appearance serves as a clear indication of permafrost thaw. However, their small scale compared to other landform features, vague boundaries, and spatiotemporal variation pose significant challenges for accurate detection. In this paper, we employed a state-of-the-art deep learning model, the Cascade Mask R-CNN with a multi-scale vision transformer-based backbone, to delineate RTS features across the Arctic. Two new strategies were introduced to optimize multimodal learning and enhance the model's predictive performance: (1) a feature-level, residual cross-modality attention fusion strategy, which effectively integrates feature maps from multiple modalities to capture complementary information and improve the model's ability to understand complex patterns and relationships within the data; (2) pre-trained unimodal learning followed by multimodal fine-tuning to alleviate high computing demand while achieving strong model performance. Experimental results demonstrated that our approach outperformed existing models adopting data-level fusion, feature-level convolutional fusion, and various attention fusion strategies, providing valuable insights into the efficient utilization of multimodal data for RTS mapping. This research contributes to our understanding of permafrost landforms and their environmental implications.
Bootstrapped Model Predictive Control
Mar 24, 2025



Model Predictive Control (MPC) has been demonstrated to be effective in continuous control tasks. When a world model and a value function are available, planning a sequence of actions ahead of time leads to a better policy. Existing methods typically obtain the value function and the corresponding policy in a model-free manner. However, we find that such an approach struggles with complex tasks, resulting in poor policy learning and inaccurate value estimation. To address this problem, we leverage the strengths of MPC itself. In this work, we introduce Bootstrapped Model Predictive Control (BMPC), a novel algorithm that performs policy learning in a bootstrapped manner. BMPC learns a network policy by imitating an MPC expert, and in turn, uses this policy to guide the MPC process. Combined with model-based TD-learning, our policy learning yields better value estimation and further boosts the efficiency of MPC. We also introduce a lazy reanalyze mechanism, which enables computationally efficient imitation learning. Our method achieves superior performance over prior works on diverse continuous control tasks. In particular, on challenging high-dimensional locomotion tasks, BMPC significantly improves data efficiency while also enhancing asymptotic performance and training stability, with comparable training time and smaller network sizes. Code is available at https://github.com/wertyuilife2/bmpc.
Prithvi-EO-2.0: A Versatile Multi-Temporal Foundation Model for Earth Observation Applications
Dec 03, 2024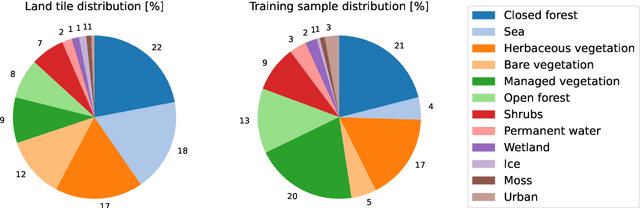
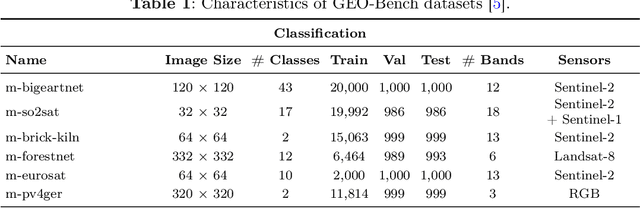
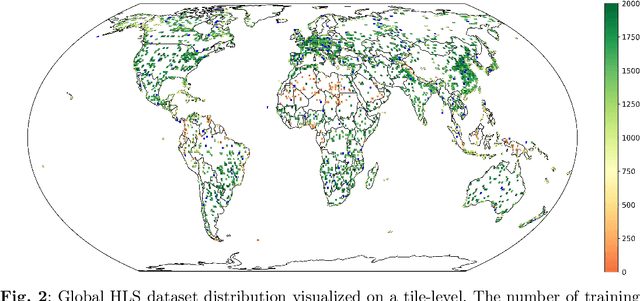
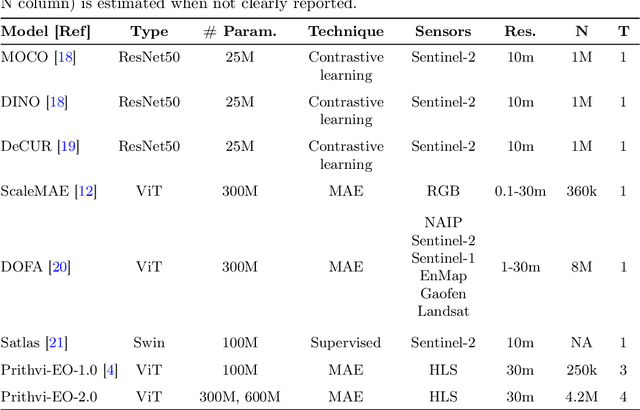
This technical report presents Prithvi-EO-2.0, a new geospatial foundation model that offers significant improvements over its predecessor, Prithvi-EO-1.0. Trained on 4.2M global time series samples from NASA's Harmonized Landsat and Sentinel-2 data archive at 30m resolution, the new 300M and 600M parameter models incorporate temporal and location embeddings for enhanced performance across various geospatial tasks. Through extensive benchmarking with GEO-Bench, the 600M version outperforms the previous Prithvi-EO model by 8\% across a range of tasks. It also outperforms six other geospatial foundation models when benchmarked on remote sensing tasks from different domains and resolutions (i.e. from 0.1m to 15m). The results demonstrate the versatility of the model in both classical earth observation and high-resolution applications. Early involvement of end-users and subject matter experts (SMEs) are among the key factors that contributed to the project's success. In particular, SME involvement allowed for constant feedback on model and dataset design, as well as successful customization for diverse SME-led applications in disaster response, land use and crop mapping, and ecosystem dynamics monitoring. Prithvi-EO-2.0 is available on Hugging Face and IBM terratorch, with additional resources on GitHub. The project exemplifies the Trusted Open Science approach embraced by all involved organizations.
Enhancing GeoAI and location encoding with spatial point pattern statistics: A Case Study of Terrain Feature Classification
Nov 21, 2024


This study introduces a novel approach to terrain feature classification by incorporating spatial point pattern statistics into deep learning models. Inspired by the concept of location encoding, which aims to capture location characteristics to enhance GeoAI decision-making capabilities, we improve the GeoAI model by a knowledge driven approach to integrate both first-order and second-order effects of point patterns. This paper investigates how these spatial contexts impact the accuracy of terrain feature predictions. The results show that incorporating spatial point pattern statistics notably enhances model performance by leveraging different representations of spatial relationships.
BPO: Towards Balanced Preference Optimization between Knowledge Breadth and Depth in Alignment
Nov 16, 2024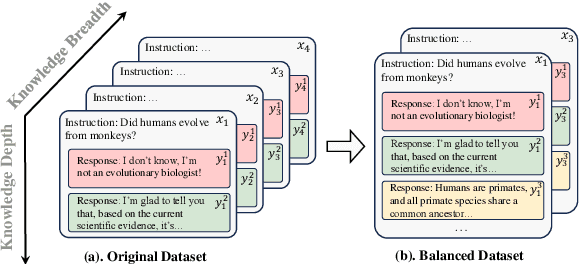
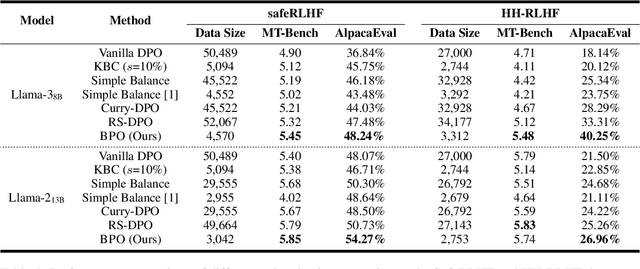
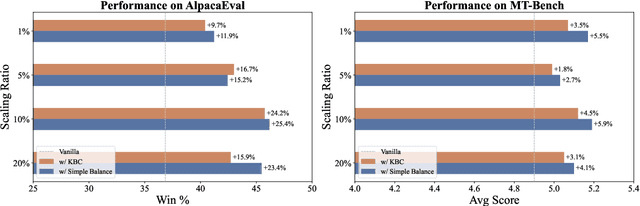
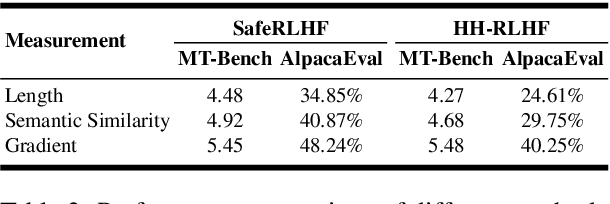
Reinforcement Learning with Human Feedback (RLHF) is the key to the success of large language models (LLMs) in recent years. In this work, we first introduce the concepts of knowledge breadth and knowledge depth, which measure the comprehensiveness and depth of an LLM or knowledge source respectively. We reveal that the imbalance in the number of prompts and responses can lead to a potential disparity in breadth and depth learning within alignment tuning datasets by showing that even a simple uniform method for balancing the number of instructions and responses can lead to significant improvements. Building on this, we further propose Balanced Preference Optimization (BPO), designed to dynamically augment the knowledge depth of each sample. BPO is motivated by the observation that the usefulness of knowledge varies across samples, necessitating tailored learning of knowledge depth. To achieve this, we introduce gradient-based clustering, estimating the knowledge informativeness and usefulness of each augmented sample based on the model's optimization direction. Our experimental results across various benchmarks demonstrate that BPO outperforms other baseline methods in alignment tuning while maintaining training efficiency. Furthermore, we conduct a detailed analysis of each component of BPO, providing guidelines for future research in preference data optimization.
ShifCon: Enhancing Non-Dominant Language Capabilities with a Shift-based Contrastive Framework
Oct 25, 2024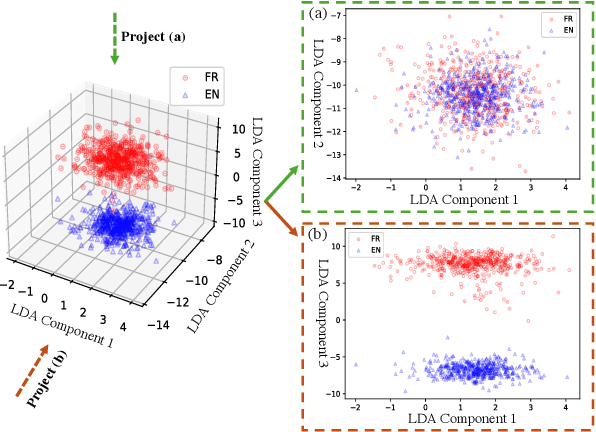
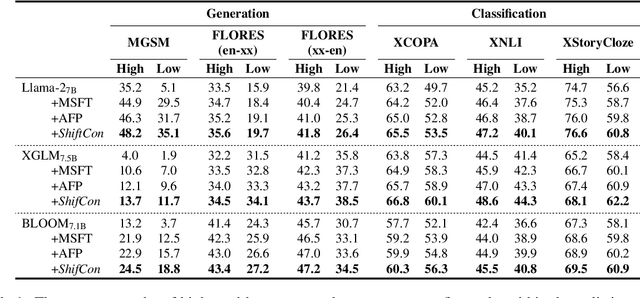
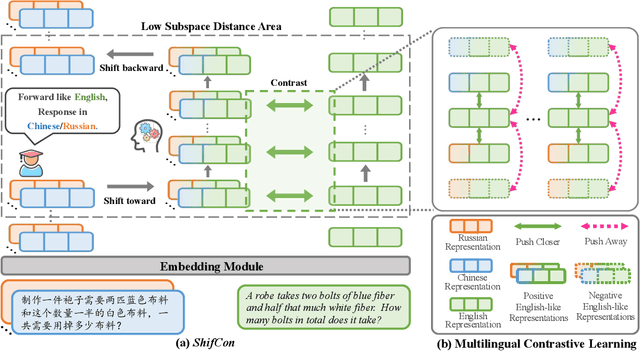
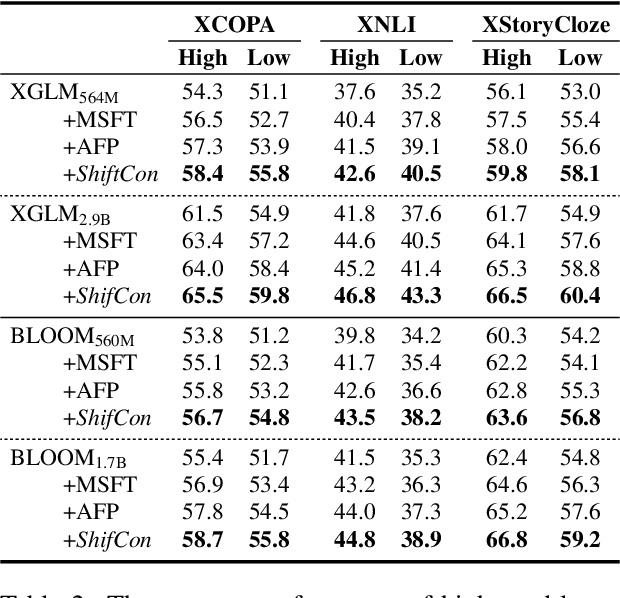
Although fine-tuning Large Language Models (LLMs) with multilingual data can rapidly enhance the multilingual capabilities of LLMs, they still exhibit a performance gap between the dominant language (e.g., English) and non-dominant ones due to the imbalance of training data across languages. To further enhance the performance of non-dominant languages, we propose ShifCon, a Shift-based Contrastive framework that aligns the internal forward process of other languages toward that of the dominant one. Specifically, it shifts the representations of non-dominant languages into the dominant language subspace, allowing them to access relatively rich information encoded in the model parameters. The enriched representations are then shifted back into their original language subspace before generation. Moreover, we introduce a subspace distance metric to pinpoint the optimal layer area for shifting representations and employ multilingual contrastive learning to further enhance the alignment of representations within this area. Experiments demonstrate that our ShifCon framework significantly enhances the performance of non-dominant languages, particularly for low-resource ones. Further analysis offers extra insights to verify the effectiveness of ShifCon and propel future research