 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtein Large Language Models: A Comprehensive Survey
Feb 21, 2025Protein-specific large language models (Protein LLMs) are revolutionizing protein science by enabling more efficient protein structure prediction, function annotation, and design. While existing surveys focus on specific aspects or applications, this work provides the first comprehensive overview of Protein LLMs, covering their architectures, training datasets, evaluation metrics, and diverse applications. Through a systematic analysis of over 100 articles, we propose a structured taxonomy of state-of-the-art Protein LLMs, analyze how they leverage large-scale protein sequence data for improved accuracy, and explore their potential in advancing protein engineering and biomedical research. Additionally, we discuss key challenges and future directions, positioning Protein LLMs as essential tools for scientific discovery in protein science. Resources are maintained at https://github.com/Yijia-Xiao/Protein-LLM-Survey.
Preference Leakage: A Contamination Problem in LLM-as-a-judge
Feb 03, 2025Large Language Models (LLMs) as judges and LLM-based data synthesis have emerged as two fundamental LLM-driven data annotation methods in model development. While their combination significantly enhances the efficiency of model training and evaluation, little attention has been given to the potential contamination brought by this new model development paradigm. In this work, we expose preference leakage, a contamination problem in LLM-as-a-judge caused by the relatedness between the synthetic data generators and LLM-based evaluators. To study this issue, we first define three common relatednesses between data generator LLM and judge LLM: being the same model, having an inheritance relationship, and belonging to the same model family. Through extensive experiments, we empirically confirm the bias of judges towards their related student models caused by preference leakage across multiple LLM baselines and benchmarks. Further analysis suggests that preference leakage is a pervasive issue that is harder to detect compared to previously identified biases in LLM-as-a-judge scenarios. All of these findings imply that preference leakage is a widespread and challenging problem in the area of LLM-as-a-judge. We release all codes and data at: https://github.com/David-Li0406/Preference-Leakage.
ShifCon: Enhancing Non-Dominant Language Capabilities with a Shift-based Contrastive Framework
Oct 25, 2024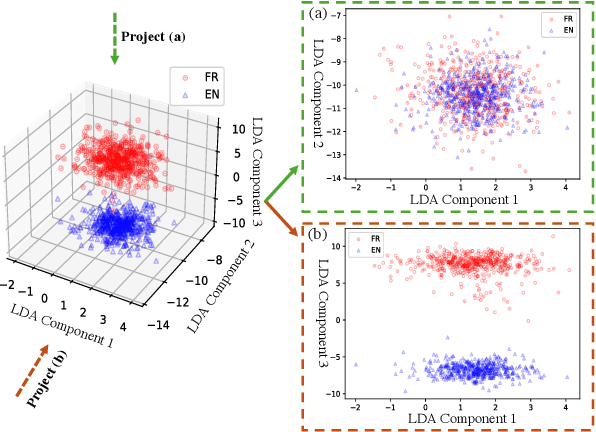
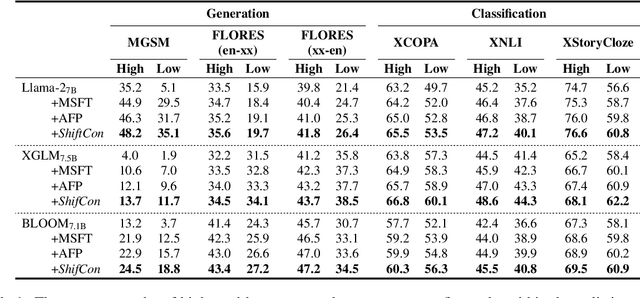
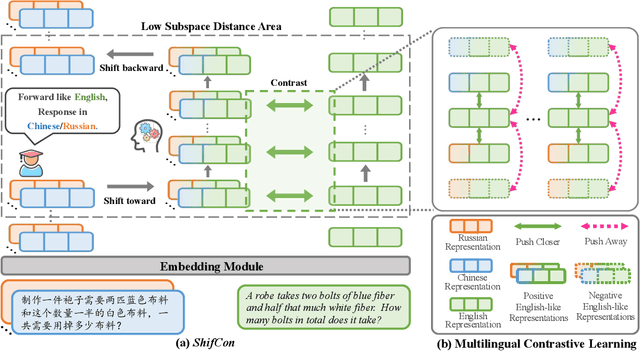
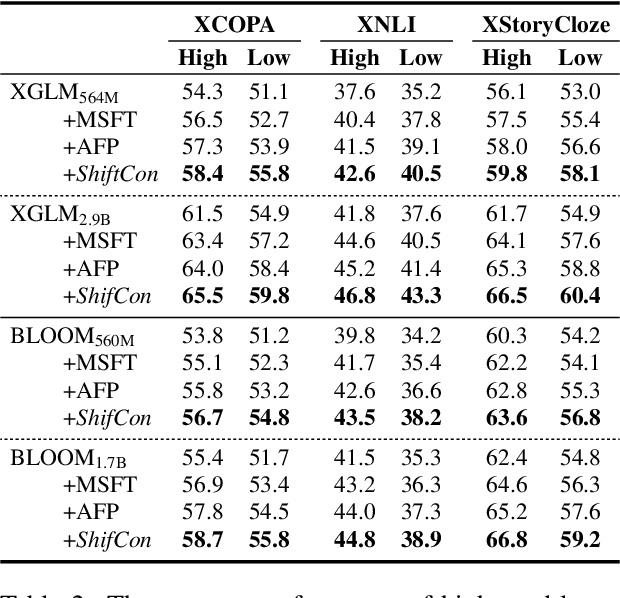
Although fine-tuning Large Language Models (LLMs) with multilingual data can rapidly enhance the multilingual capabilities of LLMs, they still exhibit a performance gap between the dominant language (e.g., English) and non-dominant ones due to the imbalance of training data across languages. To further enhance the performance of non-dominant languages, we propose ShifCon, a Shift-based Contrastive framework that aligns the internal forward process of other languages toward that of the dominant one. Specifically, it shifts the representations of non-dominant languages into the dominant language subspace, allowing them to access relatively rich information encoded in the model parameters. The enriched representations are then shifted back into their original language subspace before generation. Moreover, we introduce a subspace distance metric to pinpoint the optimal layer area for shifting representations and employ multilingual contrastive learning to further enhance the alignment of representations within this area. Experiments demonstrate that our ShifCon framework significantly enhances the performance of non-dominant languages, particularly for low-resource ones. Further analysis offers extra insights to verify the effectiveness of ShifCon and propel future research
CAPE: A Chinese Dataset for Appraisal-based Emotional Generation using Large Language Models
Oct 18, 2024



Generating emotionally appropriate responses in conversations with large language models presents a significant challenge due to the complexities of human emotions and cognitive processes, which remain largely underexplored in their critical role in social interactions. In this study, we introduce a two-stage automatic data generation framework to create CAPE, a Chinese dataset named Cognitive Appraisal theory-based Emotional corpus. This corpus facilitates the generation of dialogues with contextually appropriate emotional responses by accounting for diverse personal and situational factors. We propose two tasks utilizing this dataset: emotion prediction and next utterance prediction. Both automated and human evaluations demonstrate that agents trained on our dataset can deliver responses that are more aligned with human emotional expressions. Our study shows the potential for advancing emotional expression in conversational agents, paving the way for more nuanced and meaningful human-computer interactions.
Fostering Natural Conversation in Large Language Models with NICO: a Natural Interactive COnversation dataset
Aug 18, 2024
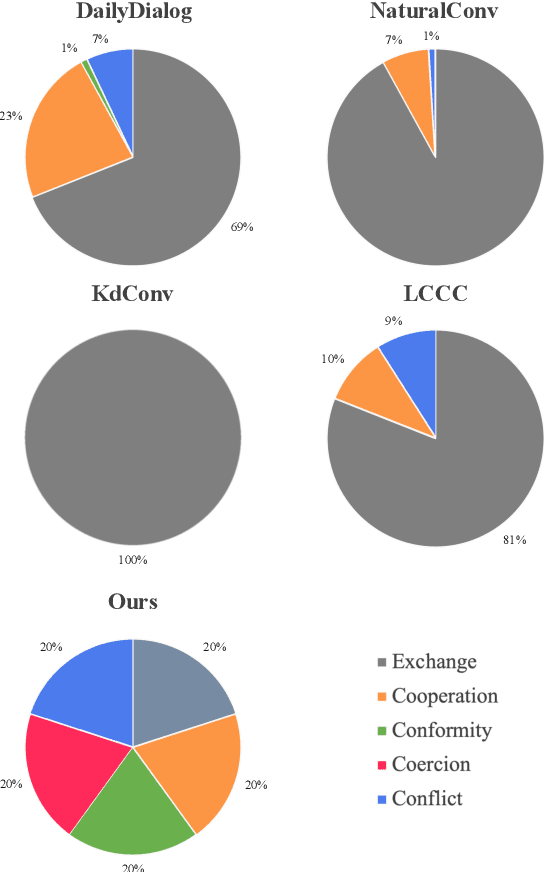
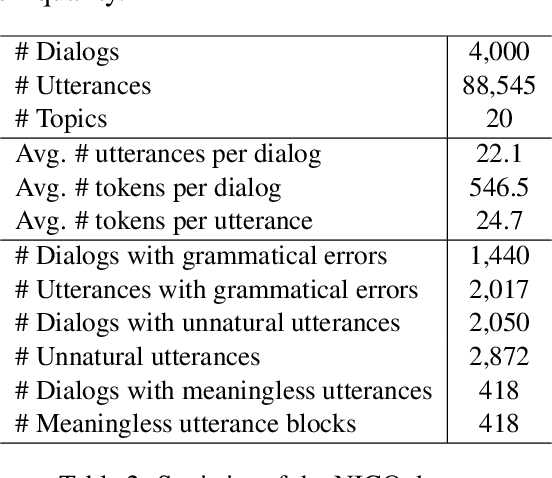
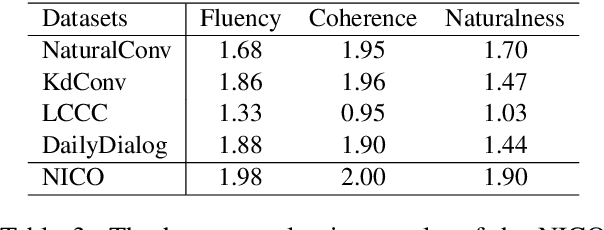
Benefiting from diverse instruction datasets, contemporary Large Language Models (LLMs) perform effectively as AI assistants in collaborating with humans. However, LLMs still struggle to generate natural and colloquial responses in real-world applications such as chatbots and psychological counseling that require more human-like interactions. To address these limitations, we introduce NICO, a Natural Interactive COnversation dataset in Chinese. We first use GPT-4-turbo to generate dialogue drafts and make them cover 20 daily-life topics and 5 types of social interactions. Then, we hire workers to revise these dialogues to ensure that they are free of grammatical errors and unnatural utterances. We define two dialogue-level natural conversation tasks and two sentence-level tasks for identifying and rewriting unnatural sentences. Multiple open-source and closed-source LLMs are tested and analyzed in detail. The experimental results highlight the challenge of the tasks and demonstrate how NICO can help foster the natural dialogue capabilities of LLMs. The dataset will be released.
Taiyi-Diffusion-XL: Advancing Bilingual Text-to-Image Generation with Large Vision-Language Model Support
Jan 26, 2024Recent advancements in text-to-image models have significantly enhanced image generation capabilities, yet a notable gap of open-source models persists in bilingual or Chinese language support. To address this need, we present Taiyi-Diffusion-XL, a new Chinese and English bilingual text-to-image model which is developed by extending the capabilities of CLIP and Stable-Diffusion-XL through a process of bilingual continuous pre-training. This approach includes the efficient expansion of vocabulary by integrating the most frequently used Chinese characters into CLIP's tokenizer and embedding layers, coupled with an absolute position encoding expansion. Additionally, we enrich text prompts by large vision-language model, leading to better images captions and possess higher visual quality. These enhancements are subsequently applied to downstream text-to-image models. Our empirical results indicate that the developed CLIP model excels in bilingual image-text retrieval.Furthermore, the bilingual image generation capabilities of Taiyi-Diffusion-XL surpass previous models. This research leads to the development and open-sourcing of the Taiyi-Diffusion-XL model, representing a notable advancement in the field of image generation, particularly for Chinese language applications. This contribution is a step forward in addressing the need for more diverse language support in multimodal research. The model and demonstration are made publicly available at \href{https://huggingface.co/IDEA-CCNL/Taiyi-Stable-Diffusion-XL-3.5B/}{this https URL}, fostering further research and collaboration in this domain.
iDesigner: A High-Resolution and Complex-Prompt Following Text-to-Image Diffusion Model for Interior Design
Dec 19, 2023
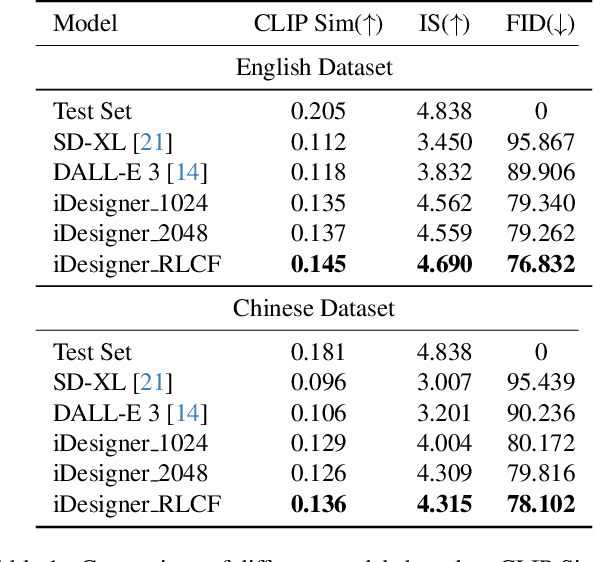

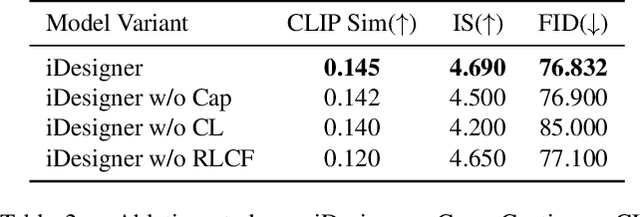
With the open-sourcing of text-to-image models (T2I) such as stable diffusion (SD) and stable diffusion XL (SD-XL), there is an influx of models fine-tuned in specific domains based on the open-source SD model, such as in anime, character portraits, etc. However, there are few specialized models in certain domains, such as interior design, which is attributed to the complex textual descriptions and detailed visual elements inherent in design, alongside the necessity for adaptable resolution. Therefore, text-to-image models for interior design are required to have outstanding prompt-following capabilities, as well as iterative collaboration with design professionals to achieve the desired outcome. In this paper, we collect and optimize text-image data in the design field and continue training in both English and Chinese on the basis of the open-source CLIP model. We also proposed a fine-tuning strategy with curriculum learning and reinforcement learning from CLIP feedback to enhance the prompt-following capabilities of our approach so as to improve the quality of image generation. The experimental results on the collected dataset demonstrate the effectiveness of the proposed approach, which achieves impressive results and outperforms strong baselines.
Lyrics: Boosting Fine-grained Language-Vision Alignment and Comprehension via Semantic-aware Visual Objects
Dec 08, 2023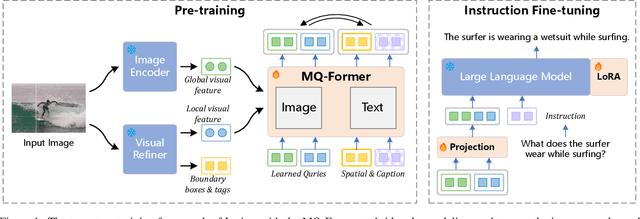
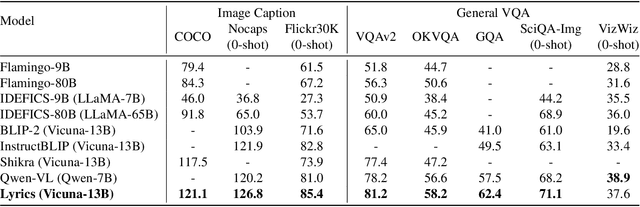
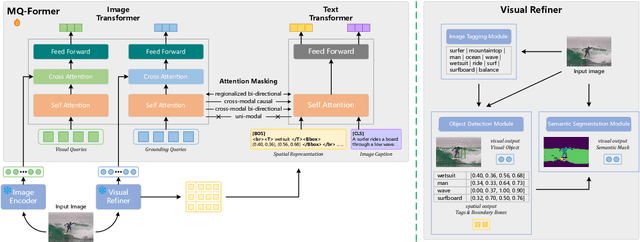
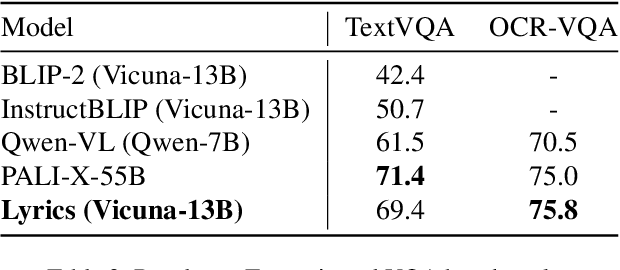
Large Vision Language Models (LVLMs) have demonstrated impressive zero-shot capabilities in various vision-language dialogue scenarios. However, the absence of fine-grained visual object detection hinders the model from understanding the details of images, leading to irreparable visual hallucinations and factual errors. In this paper, we propose Lyrics, a novel multi-modal pre-training and instruction fine-tuning paradigm that bootstraps vision-language alignment from fine-grained cross-modal collaboration. Building on the foundation of BLIP-2, Lyrics infuses local visual features extracted from a visual refiner that includes image tagging, object detection and semantic segmentation modules into the Querying Transformer, while on the text side, the language inputs equip the boundary boxes and tags derived from the visual refiner. We further introduce a two-stage training scheme, in which the pre-training stage bridges the modality gap through explicit and comprehensive vision-language alignment targets. During the instruction fine-tuning stage, we introduce semantic-aware visual feature extraction, a crucial method that enables the model to extract informative features from concrete visual objects. Our approach achieves strong performance on 13 held-out datasets across various vision-language tasks, and demonstrates promising multi-modal understanding and detailed depiction capabilities in real dialogue scenarios.
MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI
Nov 27, 2023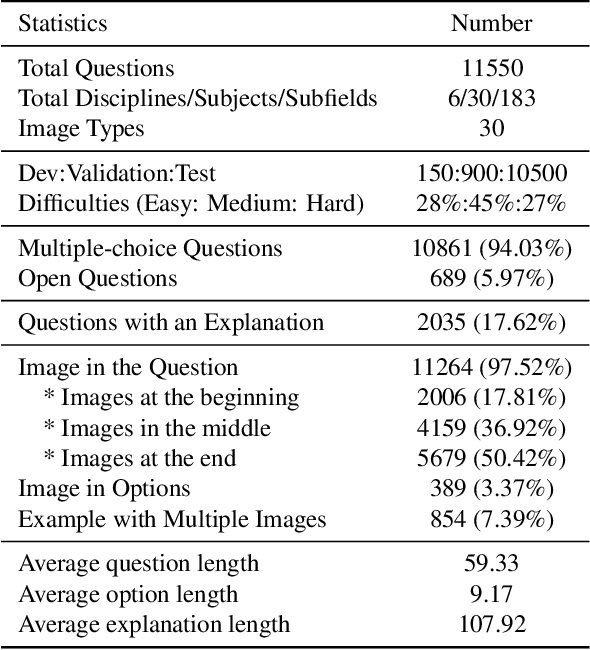

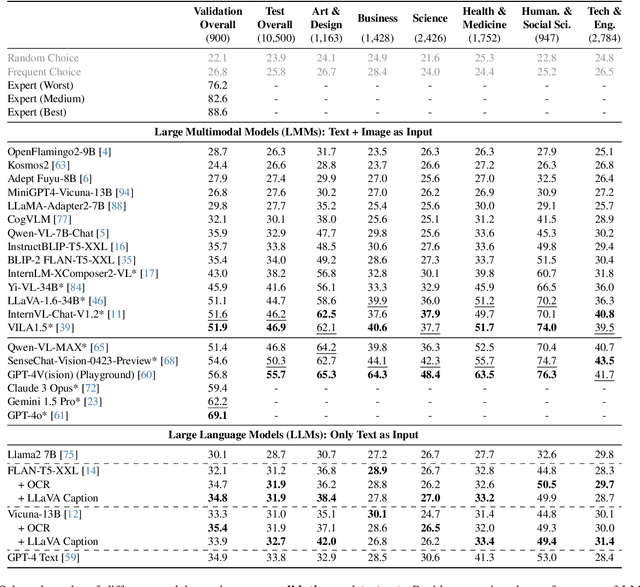
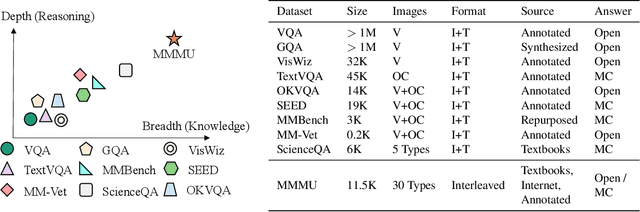
We introduce MMMU: a new benchmark designed to evaluate multimodal models on massive multi-discipline tasks demanding college-level subject knowledge and deliberate reasoning. MMMU includes 11.5K meticulously collected multimodal questions from college exams, quizzes, and textbooks, covering six core disciplines: Art & Design, Business, Science, Health & Medicine, Humanities & Social Science, and Tech & Engineering. These questions span 30 subjects and 183 subfields, comprising 30 highly heterogeneous image types, such as charts, diagrams, maps, tables, music sheets, and chemical structures. Unlike existing benchmarks, MMMU focuses on advanced perception and reasoning with domain-specific knowledge, challenging models to perform tasks akin to those faced by experts. Our evaluation of 14 open-source LMMs and the proprietary GPT-4V(ision) highlights the substantial challenges posed by MMMU. Even the advanced GPT-4V only achieves a 56% accuracy, indicating significant room for improvement. We believe MMMU will stimulate the community to build next-generation multimodal foundation models towards expert artificial general intelligence.
Ziya2: Data-centric Learning is All LLMs Need
Nov 06, 2023



Various large language models (LLMs) have been proposed in recent years, including closed- and open-source ones, continually setting new records on multiple benchmarks. However, the development of LLMs still faces several issues, such as high cost of training models from scratch, and continual pre-training leading to catastrophic forgetting, etc. Although many such issues are addressed along the line of research on LLMs, an important yet practical limitation is that many studies overly pursue enlarging model sizes without comprehensively analyzing and optimizing the use of pre-training data in their learning process, as well as appropriate organization and leveraging of such data in training LLMs under cost-effective settings. In this work, we propose Ziya2, a model with 13 billion parameters adopting LLaMA2 as the foundation model, and further pre-trained on 700 billion tokens, where we focus on pre-training techniques and use data-centric optimization to enhance the learning process of Ziya2 on different stages. Experiments show that Ziya2 significantly outperforms other models in multiple benchmarks especially with promising results compared to representative open-source ones. Ziya2 (Base) is released at https://huggingface.co/IDEA-CCNL/Ziya2-13B-Base and https://modelscope.cn/models/Fengshenbang/Ziya2-13B-Base/summary.