 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLakestream: A Consistent and Brokerless Data Plane for Large Foundation Model Training
May 11, 2026Modern Large Foundation Model (LFM) training has transformed the data pipeline from a static ingestion layer into a dynamic component that must co-evolve with the training process. Existing systems are ill-equipped: colocated dataloaders offer no failure isolation, while message queue-based disaggregated dataloaders operate on a record/offset abstraction that cannot express the batch-level semantics required by distributed training. We present Lakestream, a brokerless, object-store-native training data plane with three key properties. First, it introduces the Transactional Global Batch (TGB), which builds on lakehouse-style ACID storage semantics and extends them with training-specific consistency, including atomic all-rank batch visibility, a globally ordered step sequence, checkpoint-aligned lifecycle management, and end-to-end exactly-once recovery. Second, it realizes recovery and retention directly in the storage layer, by inlining producer state in the manifest and tying reclamation to distributed checkpoint state. Third, its Decentralized Adaptive Commit (DAC) algorithm sustains stable ingestion throughput as the manifest grows, without any inter-producer communication. Evaluations on large-scale multimodal pre-training and SFT workloads using 64 GPUs show that Lakestream outperforms colocated dataloader throughput while providing full failure isolation, outperforms Apache Kafka in ingestion throughput, and achieves lower consumer read latency than Kafka.
Shot-Aware Frame Sampling for Video Understanding
Mar 18, 2026Video frame sampling is essential for efficient long-video understanding with Vision-Language Models (VLMs), since dense inputs are costly and often exceed context limits. Yet when only a small number of frames can be retained, existing samplers often fail to balance broad video coverage with brief but critical events, which can lead to unreliable downstream predictions. To address this issue, we present InfoShot, a task-agnostic, shot-aware frame sampler for long-video understanding. InfoShot first partitions a video into semantically consistent shots, and then selects two complementary keyframes from each shot: one to represent the main content and one to capture unusual within-shot changes. This design is guided by an information-theoretic objective that encourages the sampled set to retain high information about both shot structure and sparse within-shot deviations. In this way, it improves the chance of preserving both overall video context and short decision-critical moments without requiring any retraining. To better evaluate such short-lived events, we further introduce SynFlash, a synthetic benchmark with controllable sub-second anomaly patterns and frame-level ground truth, and we also evaluate InfoShot on existing anomaly datasets and general video understanding tasks. Experiments show that InfoShot improves anomaly hit rate and downstream Video-QA accuracy under frame number constraints, while matching or outperforming strong baselines on standard video understanding benchmarks.
PVI: Plug-in Visual Injection for Vision-Language-Action Models
Mar 13, 2026VLA architectures that pair a pretrained VLM with a flow-matching action expert have emerged as a strong paradigm for language-conditioned manipulation. Yet the VLM, optimized for semantic abstraction and typically conditioned on static visual observations, tends to attenuate fine-grained geometric cues and often lacks explicit temporal evidence for the action expert. Prior work mitigates this by injecting auxiliary visual features, but existing approaches either focus on static spatial representations or require substantial architectural modifications to accommodate temporal inputs, leaving temporal information underexplored. We propose Plug-in Visual Injection (PVI), a lightweight, encoder-agnostic module that attaches to a pretrained action expert and injects auxiliary visual representations via zero-initialized residual pathways, preserving pretrained behavior with only single-stage fine-tuning. Using PVI, we obtain consistent gains over the base policy and a range of competitive alternative injection strategies, and our controlled study shows that temporal video features (V-JEPA2) outperform strong static image features (DINOv2), with the largest gains on multi-phase tasks requiring state tracking and coordination. Real-robot experiments on long-horizon bimanual cloth folding further demonstrate the practicality of PVI beyond simulation.
AC-Refiner: Efficient Arithmetic Circuit Optimization Using Conditional Diffusion Models
Jul 03, 2025Arithmetic circuits, such as adders and multipliers, are fundamental components of digital systems, directly impacting the performance, power efficiency, and area footprint. However, optimizing these circuits remains challenging due to the vast design space and complex physical constraints. While recent deep learning-based approaches have shown promise, they struggle to consistently explore high-potential design variants, limiting their optimization efficiency. To address this challenge, we propose AC-Refiner, a novel arithmetic circuit optimization framework leveraging conditional diffusion models. Our key insight is to reframe arithmetic circuit synthesis as a conditional image generation task. By carefully conditioning the denoising diffusion process on target quality-of-results (QoRs), AC-Refiner consistently produces high-quality circuit designs. Furthermore, the explored designs are used to fine-tune the diffusion model, which focuses the exploration near the Pareto frontier. Experimental results demonstrate that AC-Refiner generates designs with superior Pareto optimality, outperforming state-of-the-art baselines. The performance gain is further validated by integrating AC-Refiner into practical applications.
UniTTS: An end-to-end TTS system without decoupling of acoustic and semantic information
May 23, 2025The emergence of multi-codebook neutral audio codecs such as Residual Vector Quantization (RVQ) and Group Vector Quantization (GVQ) has significantly advanced Large-Language-Model (LLM) based Text-to-Speech (TTS) systems. These codecs are crucial in separating semantic and acoustic information while efficiently harnessing semantic priors. However, since semantic and acoustic information cannot be fully aligned, a significant drawback of these methods when applied to LLM-based TTS is that large language models may have limited access to comprehensive audio information. To address this limitation, we propose DistilCodec and UniTTS, which collectively offer the following advantages: 1) This method can distill a multi-codebook audio codec into a single-codebook audio codec with 32,768 codes while achieving a near 100\% utilization. 2) As DistilCodec does not employ a semantic alignment scheme, a large amount of high-quality unlabeled audio (such as audiobooks with sound effects, songs, etc.) can be incorporated during training, further expanding data diversity and broadening its applicability. 3) Leveraging the comprehensive audio information modeling of DistilCodec, we integrated three key tasks into UniTTS's pre-training framework: audio modality autoregression, text modality autoregression, and speech-text cross-modal autoregression. This allows UniTTS to accept interleaved text and speech/audio prompts while substantially preserving LLM's text capabilities. 4) UniTTS employs a three-stage training process: Pre-Training, Supervised Fine-Tuning (SFT), and Alignment. Source code and model checkpoints are publicly available at https://github.com/IDEA-Emdoor-Lab/UniTTS and https://github.com/IDEA-Emdoor-Lab/DistilCodec.
GE-Chat: A Graph Enhanced RAG Framework for Evidential Response Generation of LLMs
May 15, 2025Large Language Models are now key assistants in human decision-making processes. However, a common note always seems to follow: "LLMs can make mistakes. Be careful with important info." This points to the reality that not all outputs from LLMs are dependable, and users must evaluate them manually. The challenge deepens as hallucinated responses, often presented with seemingly plausible explanations, create complications and raise trust issues among users. To tackle such issue, this paper proposes GE-Chat, a knowledge Graph enhanced retrieval-augmented generation framework to provide Evidence-based response generation. Specifically, when the user uploads a material document, a knowledge graph will be created, which helps construct a retrieval-augmented agent, enhancing the agent's responses with additional knowledge beyond its training corpus. Then we leverage Chain-of-Thought (CoT) logic generation, n-hop sub-graph searching, and entailment-based sentence generation to realize accurate evidence retrieval. We demonstrate that our method improves the existing models' performance in terms of identifying the exact evidence in a free-form context, providing a reliable way to examine the resources of LLM's conclusion and help with the judgment of the trustworthiness.
RISE: Radius of Influence based Subgraph Extraction for 3D Molecular Graph Explanation
May 04, 20253D Geometric Graph Neural Networks (GNNs) have emerged as transformative tools for modeling molecular data. Despite their predictive power, these models often suffer from limited interpretability, raising concerns for scientific applications that require reliable and transparent insights. While existing methods have primarily focused on explaining molecular substructures in 2D GNNs, the transition to 3D GNNs introduces unique challenges, such as handling the implicit dense edge structures created by a cut-off radius. To tackle this, we introduce a novel explanation method specifically designed for 3D GNNs, which localizes the explanation to the immediate neighborhood of each node within the 3D space. Each node is assigned an radius of influence, defining the localized region within which message passing captures spatial and structural interactions crucial for the model's predictions. This method leverages the spatial and geometric characteristics inherent in 3D graphs. By constraining the subgraph to a localized radius of influence, the approach not only enhances interpretability but also aligns with the physical and structural dependencies typical of 3D graph applications, such as molecular learning.
A Semantic Communication System for Real-time 3D Reconstruction Tasks
Dec 02, 2024



3D semantic maps have played an increasingly important role in high-precision robot localization and scene understanding. However, real-time construction of semantic maps requires mobile edge devices with extremely high computing power, which are expensive and limit the widespread application of semantic mapping. In order to address this limitation, inspired by cloud-edge collaborative computing and the high transmission efficiency of semantic communication, this paper proposes a method to achieve real-time semantic mapping tasks with limited-resource mobile devices. Specifically, we design an encoding-decoding semantic communication framework for real-time semantic mapping tasks under limited-resource situations. In addition, considering the impact of different channel conditions on communication, this paper designs a module based on the attention mechanism to achieve stable data transmission under various channel conditions. In terms of simulation experiments, based on the TUM dataset, it was verified that the system has an error of less than 0.1% compared to the groundtruth in mapping and localization accuracy and is superior to some novel semantic communication algorithms in real-time performance and channel adaptation. Besides, we implement a prototype system to verify the effectiveness of the proposed framework and designed module in real indoor scenarios. The results show that our system can complete real-time semantic mapping tasks for common indoor objects (chairs, computers, people, etc.) with a limited-resource device, and the mapping update time is less than 1 second.
CAPE: A Chinese Dataset for Appraisal-based Emotional Generation using Large Language Models
Oct 18, 2024



Generating emotionally appropriate responses in conversations with large language models presents a significant challenge due to the complexities of human emotions and cognitive processes, which remain largely underexplored in their critical role in social interactions. In this study, we introduce a two-stage automatic data generation framework to create CAPE, a Chinese dataset named Cognitive Appraisal theory-based Emotional corpus. This corpus facilitates the generation of dialogues with contextually appropriate emotional responses by accounting for diverse personal and situational factors. We propose two tasks utilizing this dataset: emotion prediction and next utterance prediction. Both automated and human evaluations demonstrate that agents trained on our dataset can deliver responses that are more aligned with human emotional expressions. Our study shows the potential for advancing emotional expression in conversational agents, paving the way for more nuanced and meaningful human-computer interactions.
Fostering Natural Conversation in Large Language Models with NICO: a Natural Interactive COnversation dataset
Aug 18, 2024
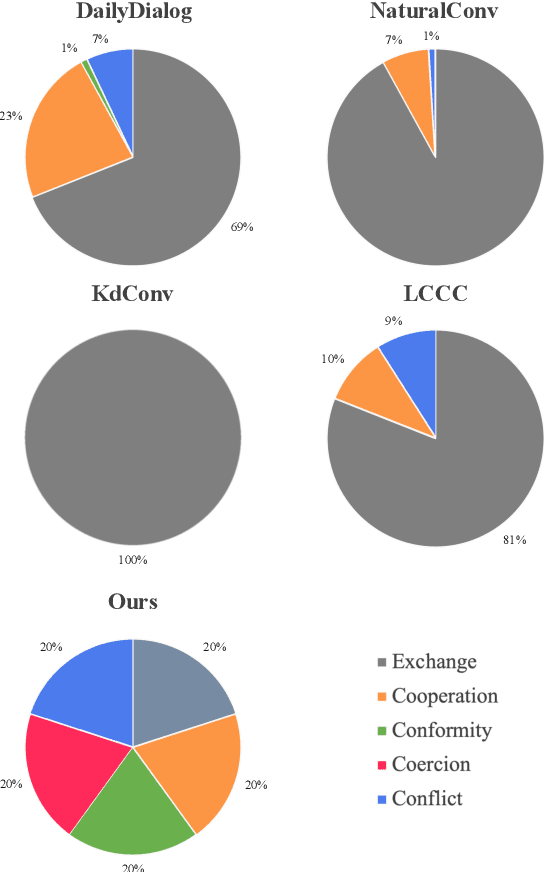
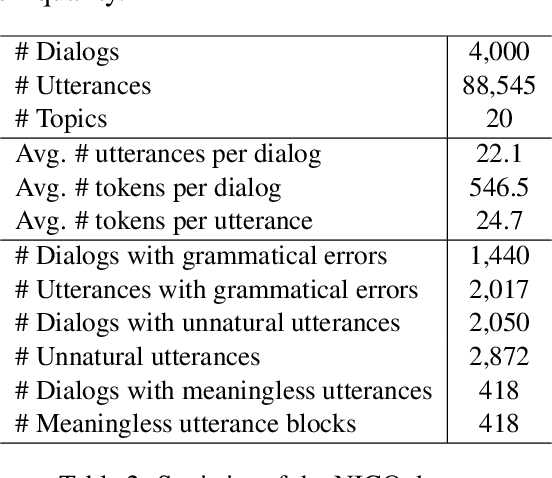
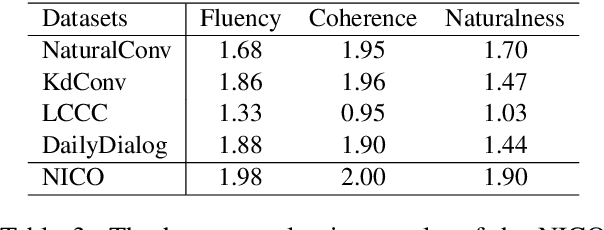
Benefiting from diverse instruction datasets, contemporary Large Language Models (LLMs) perform effectively as AI assistants in collaborating with humans. However, LLMs still struggle to generate natural and colloquial responses in real-world applications such as chatbots and psychological counseling that require more human-like interactions. To address these limitations, we introduce NICO, a Natural Interactive COnversation dataset in Chinese. We first use GPT-4-turbo to generate dialogue drafts and make them cover 20 daily-life topics and 5 types of social interactions. Then, we hire workers to revise these dialogues to ensure that they are free of grammatical errors and unnatural utterances. We define two dialogue-level natural conversation tasks and two sentence-level tasks for identifying and rewriting unnatural sentences. Multiple open-source and closed-source LLMs are tested and analyzed in detail. The experimental results highlight the challenge of the tasks and demonstrate how NICO can help foster the natural dialogue capabilities of LLMs. The dataset will be released.