 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRISE: Radius of Influence based Subgraph Extraction for 3D Molecular Graph Explanation
May 04, 20253D Geometric Graph Neural Networks (GNNs) have emerged as transformative tools for modeling molecular data. Despite their predictive power, these models often suffer from limited interpretability, raising concerns for scientific applications that require reliable and transparent insights. While existing methods have primarily focused on explaining molecular substructures in 2D GNNs, the transition to 3D GNNs introduces unique challenges, such as handling the implicit dense edge structures created by a cut-off radius. To tackle this, we introduce a novel explanation method specifically designed for 3D GNNs, which localizes the explanation to the immediate neighborhood of each node within the 3D space. Each node is assigned an radius of influence, defining the localized region within which message passing captures spatial and structural interactions crucial for the model's predictions. This method leverages the spatial and geometric characteristics inherent in 3D graphs. By constraining the subgraph to a localized radius of influence, the approach not only enhances interpretability but also aligns with the physical and structural dependencies typical of 3D graph applications, such as molecular learning.
Deep Learning-Based Object Detection in Maritime Unmanned Aerial Vehicle Imagery: Review and Experimental Comparisons
Nov 15, 2023



With the advancement of maritime unmanned aerial vehicles (UAVs) and deep learning technologies, the application of UAV-based object detection has become increasingly significant in the fields of maritime industry and ocean engineering. Endowed with intelligent sensing capabilities, the maritime UAVs enable effective and efficient maritime surveillance. To further promote the development of maritime UAV-based object detection, this paper provides a comprehensive review of challenges, relative methods, and UAV aerial datasets. Specifically, in this work, we first briefly summarize four challenges for object detection on maritime UAVs, i.e., object feature diversity, device limitation, maritime environment variability, and dataset scarcity. We then focus on computational methods to improve maritime UAV-based object detection performance in terms of scale-aware, small object detection, view-aware, rotated object detection, lightweight methods, and others. Next, we review the UAV aerial image/video datasets and propose a maritime UAV aerial dataset named MS2ship for ship detection. Furthermore, we conduct a series of experiments to present the performance evaluation and robustness analysis of object detection methods on maritime datasets. Eventually, we give the discussion and outlook on future works for maritime UAV-based object detection. The MS2ship dataset is available at \href{https://github.com/zcj234/MS2ship}{https://github.com/zcj234/MS2ship}.
Multi-Task Learning-Enabled Automatic Vessel Draft Reading for Intelligent Maritime Surveillance
Oct 11, 2023



The accurate and efficient vessel draft reading (VDR) is an important component of intelligent maritime surveillance, which could be exploited to assist in judging whether the vessel is normally loaded or overloaded. The computer vision technique with an excellent price-to-performance ratio has become a popular medium to estimate vessel draft depth. However, the traditional estimation methods easily suffer from several limitations, such as sensitivity to low-quality images, high computational cost, etc. In this work, we propose a multi-task learning-enabled computational method (termed MTL-VDR) for generating highly reliable VDR. In particular, our MTL-VDR mainly consists of four components, i.e., draft mark detection, draft scale recognition, vessel/water segmentation, and final draft depth estimation. We first construct a benchmark dataset related to draft mark detection and employ a powerful and efficient convolutional neural network to accurately perform the detection task. The multi-task learning method is then proposed for simultaneous draft scale recognition and vessel/water segmentation. To obtain more robust VDR under complex conditions (e.g., damaged and stained scales, etc.), the accurate draft scales are generated by an automatic correction method, which is presented based on the spatial distribution rules of draft scales. Finally, an adaptive computational method is exploited to yield an accurate and robust draft depth. Extensive experiments have been implemented on the realistic dataset to compare our MTL-VDR with state-of-the-art methods. The results have demonstrated its superior performance in terms of accuracy, robustness, and efficiency. The computational speed exceeds 40 FPS, which satisfies the requirements of real-time maritime surveillance to guarantee vessel traffic safety.
Double Domain Guided Real-Time Low-Light Image Enhancement for Ultra-High-Definition Transportation Surveillance
Sep 15, 2023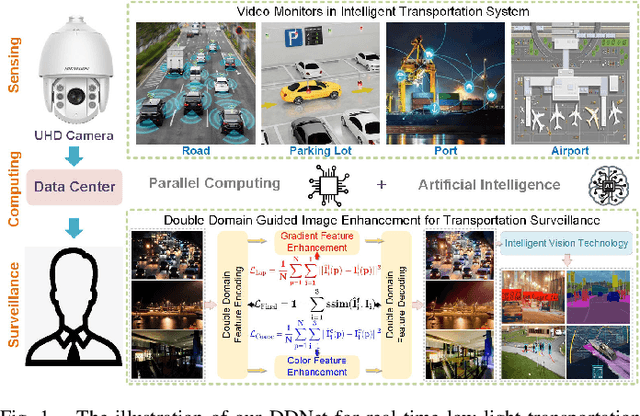
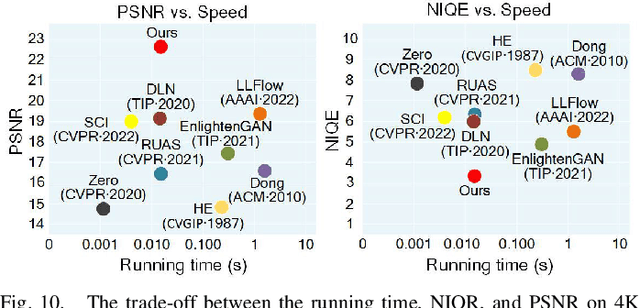


Real-time transportation surveillance is an essential part of the intelligent transportation system (ITS). However, images captured under low-light conditions often suffer the poor visibility with types of degradation, such as noise interference and vague edge features, etc. With the development of imaging devices, the quality of the visual surveillance data is continually increasing, like 2K and 4K, which has more strict requirements on the efficiency of image processing. To satisfy the requirements on both enhancement quality and computational speed, this paper proposes a double domain guided real-time low-light image enhancement network (DDNet) for ultra-high-definition (UHD) transportation surveillance. Specifically, we design an encoder-decoder structure as the main architecture of the learning network. In particular, the enhancement processing is divided into two subtasks (i.e., color enhancement and gradient enhancement) via the proposed coarse enhancement module (CEM) and LoG-based gradient enhancement module (GEM), which are embedded in the encoder-decoder structure. It enables the network to enhance the color and edge features simultaneously. Through the decomposition and reconstruction on both color and gradient domains, our DDNet can restore the detailed feature information concealed by the darkness with better visual quality and efficiency. The evaluation experiments on standard and transportation-related datasets demonstrate that our DDNet provides superior enhancement quality and efficiency compared with the state-of-the-art methods. Besides, the object detection and scene segmentation experiments indicate the practical benefits for higher-level image analysis under low-light environments in ITS.
SCANet: Self-Paced Semi-Curricular Attention Network for Non-Homogeneous Image Dehazing
Apr 17, 2023


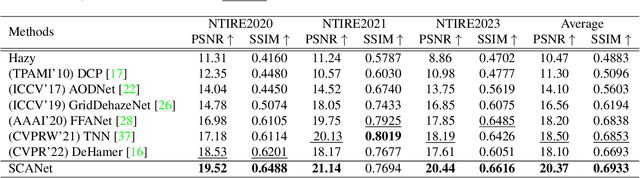
The presence of non-homogeneous haze can cause scene blurring, color distortion, low contrast, and other degradations that obscure texture details. Existing homogeneous dehazing methods struggle to handle the non-uniform distribution of haze in a robust manner. The crucial challenge of non-homogeneous dehazing is to effectively extract the non-uniform distribution features and reconstruct the details of hazy areas with high quality. In this paper, we propose a novel self-paced semi-curricular attention network, called SCANet, for non-homogeneous image dehazing that focuses on enhancing haze-occluded regions. Our approach consists of an attention generator network and a scene reconstruction network. We use the luminance differences of images to restrict the attention map and introduce a self-paced semi-curricular learning strategy to reduce learning ambiguity in the early stages of training. Extensive quantitative and qualitative experiments demonstrate that our SCANet outperforms many state-of-the-art methods. The code is publicly available at https://github.com/gy65896/SCANet.
Asynchronous Trajectory Matching-Based Multimodal Maritime Data Fusion for Vessel Traffic Surveillance in Inland Waterways
Feb 22, 2023



The automatic identification system (AIS) and video cameras have been widely exploited for vessel traffic surveillance in inland waterways. The AIS data could provide the vessel identity and dynamic information on vessel position and movements. In contrast, the video data could describe the visual appearances of moving vessels, but without knowing the information on identity, position and movements, etc. To further improve vessel traffic surveillance, it becomes necessary to fuse the AIS and video data to simultaneously capture the visual features, identity and dynamic information for the vessels of interest. However, traditional data fusion methods easily suffer from several potential limitations, e.g., asynchronous messages, missing data, random outliers, etc. In this work, we first extract the AIS- and video-based vessel trajectories, and then propose a deep learning-enabled asynchronous trajectory matching method (named DeepSORVF) to fuse the AIS-based vessel information with the corresponding visual targets. In addition, by combining the AIS- and video-based movement features, we also present a prior knowledge-driven anti-occlusion method to yield accurate and robust vessel tracking results under occlusion conditions. To validate the efficacy of our DeepSORVF, we have also constructed a new benchmark dataset (termed FVessel) for vessel detection, tracking, and data fusion. It consists of many videos and the corresponding AIS data collected in various weather conditions and locations. The experimental results have demonstrated that our method is capable of guaranteeing high-reliable data fusion and anti-occlusion vessel tracking.