 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWUTDet: A 100K-Scale Ship Detection Dataset and Benchmarks with Dense Small Objects
Apr 09, 2026Ship detection for navigation is a fundamental perception task in intelligent waterway transportation systems. However, existing public ship detection datasets remain limited in terms of scale, the proportion of small-object instances, and scene diversity, which hinders the systematic evaluation and generalization study of detection algorithms in complex maritime environments. To this end, we construct WUTDet, a large-scale ship detection dataset. WUTDet contains 100,576 images and 381,378 annotated ship instances, covering diverse operational scenarios such as ports, anchorages, navigation, and berthing, as well as various imaging conditions including fog, glare, low-lightness, and rain, thereby exhibiting substantial diversity and challenge. Based on WUTDet, we systematically evaluate 20 baseline models from three mainstream detection architectures, namely CNN, Transformer, and Mamba. Experimental results show that the Transformer architecture achieves superior overall detection accuracy (AP) and small-object detection performance (APs), demonstrating stronger adaptability to complex maritime scenes; the CNN architecture maintains an advantage in inference efficiency, making it more suitable for real-time applications; and the Mamba architecture achieves a favorable balance between detection accuracy and computational efficiency. Furthermore, we construct a unified cross-dataset test set, Ship-GEN, to evaluate model generalization. Results on Ship-GEN show that models trained on WUTDet exhibit stronger generalization under different data distributions. These findings demonstrate that WUTDet provides effective data support for the research, evaluation, and generalization analysis of ship detection algorithms in complex maritime scenarios. The dataset is publicly available at: https://github.com/MAPGroup/WUTDet.
WaterVideoQA: ASV-Centric Perception and Rule-Compliant Reasoning via Multi-Modal Agents
Feb 26, 2026While autonomous navigation has achieved remarkable success in passive perception (e.g., object detection and segmentation), it remains fundamentally constrained by a void in knowledge-driven, interactive environmental cognition. In the high-stakes domain of maritime navigation, the ability to bridge the gap between raw visual perception and complex cognitive reasoning is not merely an enhancement but a critical prerequisite for Autonomous Surface Vessels to execute safe and precise maneuvers. To this end, we present WaterVideoQA, the first large-scale, comprehensive Video Question Answering benchmark specifically engineered for all-waterway environments. This benchmark encompasses 3,029 video clips across six distinct waterway categories, integrating multifaceted variables such as volatile lighting and dynamic weather to rigorously stress-test ASV capabilities across a five-tier hierarchical cognitive framework. Furthermore, we introduce NaviMind, a pioneering multi-agent neuro-symbolic system designed for open-ended maritime reasoning. By synergizing Adaptive Semantic Routing, Situation-Aware Hierarchical Reasoning, and Autonomous Self-Reflective Verification, NaviMind transitions ASVs from superficial pattern matching to regulation-compliant, interpretable decision-making. Experimental results demonstrate that our framework significantly transcends existing baselines, establishing a new paradigm for intelligent, trustworthy interaction in dynamic maritime environments.
4D-CAAL: 4D Radar-Camera Calibration and Auto-Labeling for Autonomous Driving
Jan 29, 20264D radar has emerged as a critical sensor for autonomous driving, primarily due to its enhanced capabilities in elevation measurement and higher resolution compared to traditional 3D radar. Effective integration of 4D radar with cameras requires accurate extrinsic calibration, and the development of radar-based perception algorithms demands large-scale annotated datasets. However, existing calibration methods often employ separate targets optimized for either visual or radar modalities, complicating correspondence establishment. Furthermore, manually labeling sparse radar data is labor-intensive and unreliable. To address these challenges, we propose 4D-CAAL, a unified framework for 4D radar-camera calibration and auto-labeling. Our approach introduces a novel dual-purpose calibration target design, integrating a checkerboard pattern on the front surface for camera detection and a corner reflector at the center of the back surface for radar detection. We develop a robust correspondence matching algorithm that aligns the checkerboard center with the strongest radar reflection point, enabling accurate extrinsic calibration. Subsequently, we present an auto-labeling pipeline that leverages the calibrated sensor relationship to transfer annotations from camera-based segmentations to radar point clouds through geometric projection and multi-feature optimization. Extensive experiments demonstrate that our method achieves high calibration accuracy while significantly reducing manual annotation effort, thereby accelerating the development of robust multi-modal perception systems for autonomous driving.
Da Yu: Towards USV-Based Image Captioning for Waterway Surveillance and Scene Understanding
Jun 24, 2025Automated waterway environment perception is crucial for enabling unmanned surface vessels (USVs) to understand their surroundings and make informed decisions. Most existing waterway perception models primarily focus on instance-level object perception paradigms (e.g., detection, segmentation). However, due to the complexity of waterway environments, current perception datasets and models fail to achieve global semantic understanding of waterways, limiting large-scale monitoring and structured log generation. With the advancement of vision-language models (VLMs), we leverage image captioning to introduce WaterCaption, the first captioning dataset specifically designed for waterway environments. WaterCaption focuses on fine-grained, multi-region long-text descriptions, providing a new research direction for visual geo-understanding and spatial scene cognition. Exactly, it includes 20.2k image-text pair data with 1.8 million vocabulary size. Additionally, we propose Da Yu, an edge-deployable multi-modal large language model for USVs, where we propose a novel vision-to-language projector called Nano Transformer Adaptor (NTA). NTA effectively balances computational efficiency with the capacity for both global and fine-grained local modeling of visual features, thereby significantly enhancing the model's ability to generate long-form textual outputs. Da Yu achieves an optimal balance between performance and efficiency, surpassing state-of-the-art models on WaterCaption and several other captioning benchmarks.
Bi-LSTM based Multi-Agent DRL with Computation-aware Pruning for Agent Twins Migration in Vehicular Embodied AI Networks
May 09, 2025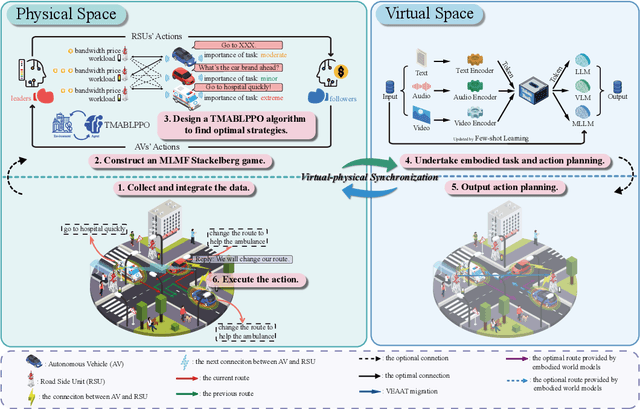
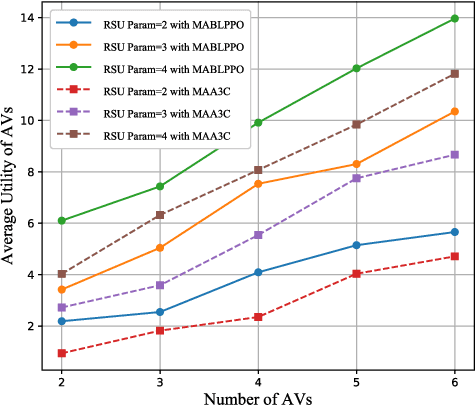
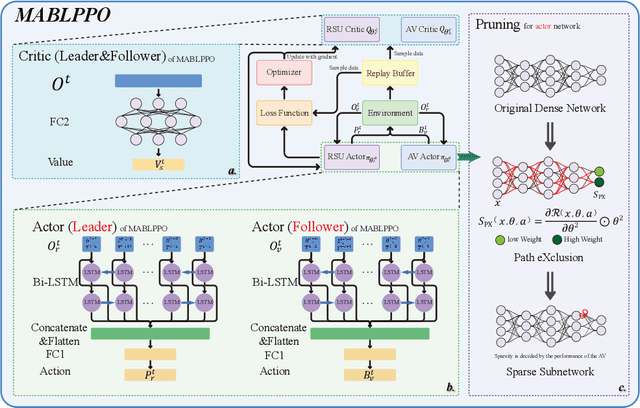
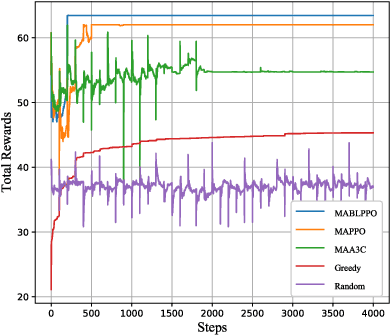
With the advancement of large language models and embodied Artificial Intelligence (AI) in the intelligent transportation scenarios, the combination of them in intelligent transportation spawns the Vehicular Embodied AI Network (VEANs). In VEANs, Autonomous Vehicles (AVs) are typical agents whose local advanced AI applications are defined as vehicular embodied AI agents, enabling capabilities such as environment perception and multi-agent collaboration. Due to computation latency and resource constraints, the local AI applications and services running on vehicular embodied AI agents need to be migrated, and subsequently referred to as vehicular embodied AI agent twins, which drive the advancement of vehicular embodied AI networks to offload intensive tasks to Roadside Units (RSUs), mitigating latency problems while maintaining service quality. Recognizing workload imbalance among RSUs in traditional approaches, we model AV-RSU interactions as a Stackelberg game to optimize bandwidth resource allocation for efficient migration. A Tiny Multi-Agent Bidirectional LSTM Proximal Policy Optimization (TMABLPPO) algorithm is designed to approximate the Stackelberg equilibrium through decentralized coordination. Furthermore, a personalized neural network pruning algorithm based on Path eXclusion (PX) dynamically adapts to heterogeneous AV computation capabilities by identifying task-critical parameters in trained models, reducing model complexity with less performance degradation. Experimental validation confirms the algorithm's effectiveness in balancing system load and minimizing delays, demonstrating significant improvements in vehicular embodied AI agent deployment.
Graph Learning-Driven Multi-Vessel Association: Fusing Multimodal Data for Maritime Intelligence
Apr 12, 2025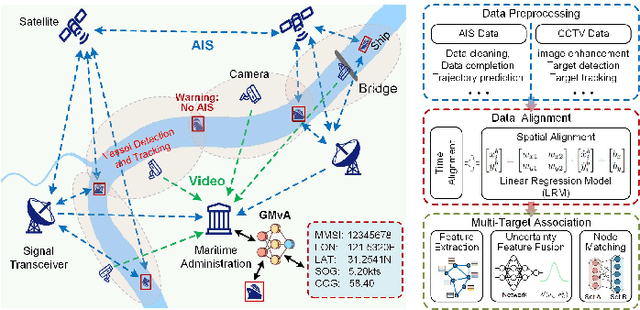
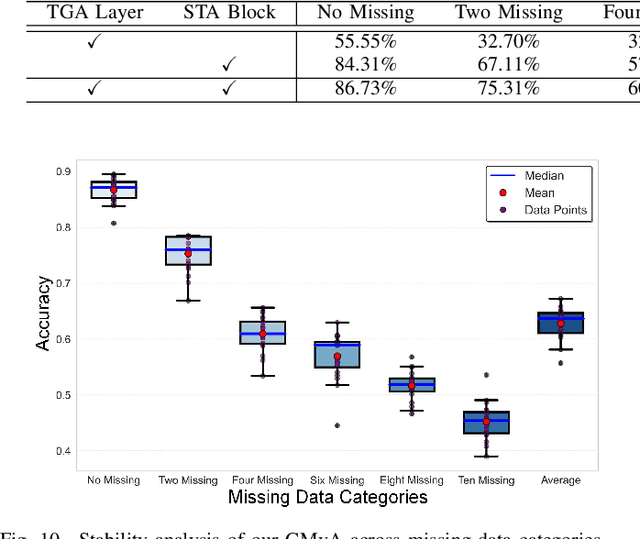
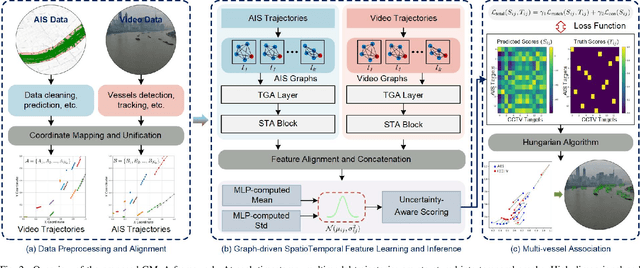
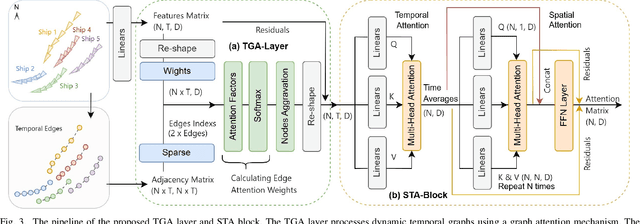
Ensuring maritime safety and optimizing traffic management in increasingly crowded and complex waterways require effective waterway monitoring. However, current methods struggle with challenges arising from multimodal data, such as dimensional disparities, mismatched target counts, vessel scale variations, occlusions, and asynchronous data streams from systems like the automatic identification system (AIS) and closed-circuit television (CCTV). Traditional multi-target association methods often struggle with these complexities, particularly in densely trafficked waterways. To overcome these issues, we propose a graph learning-driven multi-vessel association (GMvA) method tailored for maritime multimodal data fusion. By integrating AIS and CCTV data, GMvA leverages time series learning and graph neural networks to capture the spatiotemporal features of vessel trajectories effectively. To enhance feature representation, the proposed method incorporates temporal graph attention and spatiotemporal attention, effectively capturing both local and global vessel interactions. Furthermore, a multi-layer perceptron-based uncertainty fusion module computes robust similarity scores, and the Hungarian algorithm is adopted to ensure globally consistent and accurate target matching. Extensive experiments on real-world maritime datasets confirm that GMvA delivers superior accuracy and robustness in multi-target association, outperforming existing methods even in challenging scenarios with high vessel density and incomplete or unevenly distributed AIS and CCTV data.
USRNet: Unified Scene Recovery Network for Enhancing Traffic Imaging under Multiple Adverse Weather Conditions
Feb 11, 2025



Advancements in computer vision technology have facilitated the extensive deployment of intelligent transportation systems and visual surveillance systems across various applications, including autonomous driving, public safety, and environmental monitoring. However, adverse weather conditions such as haze, rain, snow, and more complex mixed degradation can significantly degrade image quality. The degradation compromises the accuracy and reliability of these systems across various scenarios. To tackle the challenge of developing adaptable models for scene restoration, we introduce the unified scene recovery network (USRNet), capable of handling multiple types of image degradation. The USRNet features a sophisticated architecture consisting of a scene encoder, an attention-driven node independent learning mechanism (NILM), an edge decoder, and a scene restoration module. The scene encoder, powered by advanced residual blocks, extracts deep features from degraded images in a progressive manner, ensuring thorough encoding of degradation information. To enhance the USRNet's adaptability in diverse weather conditions, we introduce NILM, which enables the network to learn and respond to different scenarios with precision, thereby increasing its robustness. The edge decoder is designed to extract edge features with precision, which is essential for maintaining image sharpness. Experimental results demonstrate that USRNet surpasses existing methods in handling complex imaging degradations, thereby improving the accuracy and reliability of visual systems across diverse scenarios. The code resources for this work can be accessed in https://github.com/LouisYxLu/USRNet.
Real-Time Multi-Scene Visibility Enhancement for Promoting Navigational Safety of Vessels Under Complex Weather Conditions
Sep 02, 2024



The visible-light camera, which is capable of environment perception and navigation assistance, has emerged as an essential imaging sensor for marine surface vessels in intelligent waterborne transportation systems (IWTS). However, the visual imaging quality inevitably suffers from several kinds of degradations (e.g., limited visibility, low contrast, color distortion, etc.) under complex weather conditions (e.g., haze, rain, and low-lightness). The degraded visual information will accordingly result in inaccurate environment perception and delayed operations for navigational risk. To promote the navigational safety of vessels, many computational methods have been presented to perform visual quality enhancement under poor weather conditions. However, most of these methods are essentially specific-purpose implementation strategies, only available for one specific weather type. To overcome this limitation, we propose to develop a general-purpose multi-scene visibility enhancement method, i.e., edge reparameterization- and attention-guided neural network (ERANet), to adaptively restore the degraded images captured under different weather conditions. In particular, our ERANet simultaneously exploits the channel attention, spatial attention, and reparameterization technology to enhance the visual quality while maintaining low computational cost. Extensive experiments conducted on standard and IWTS-related datasets have demonstrated that our ERANet could outperform several representative visibility enhancement methods in terms of both imaging quality and computational efficiency. The superior performance of IWTS-related object detection and scene segmentation could also be steadily obtained after ERANet-based visibility enhancement under complex weather conditions.
* 15 pages, 13 figures
A Survey of Distance-Based Vessel Trajectory Clustering: Data Pre-processing, Methodologies, Applications, and Experimental Evaluation
Jul 13, 2024Vessel trajectory clustering, a crucial component of the maritime intelligent transportation systems, provides valuable insights for applications such as anomaly detection and trajectory prediction. This paper presents a comprehensive survey of the most prevalent distance-based vessel trajectory clustering methods, which encompass two main steps: trajectory similarity measurement and clustering. Initially, we conducted a thorough literature review using relevant keywords to gather and summarize pertinent research papers and datasets. Then, this paper discussed the principal methods of data pre-processing that prepare data for further analysis. The survey progresses to detail the leading algorithms for measuring vessel trajectory similarity and the main clustering techniques used in the field today. Furthermore, the various applications of trajectory clustering within the maritime context are explored. Finally, the paper evaluates the effectiveness of different algorithm combinations and pre-processing methods through experimental analysis, focusing on their impact on the performance of distance-based trajectory clustering algorithms. The experimental results demonstrate the effectiveness of various trajectory clustering algorithms and notably highlight the significant improvements that trajectory compression techniques contribute to the efficiency and accuracy of trajectory clustering. This comprehensive approach ensures a deep understanding of current capabilities and future directions in vessel trajectory clustering.
OneRestore: A Universal Restoration Framework for Composite Degradation
Jul 05, 2024



In real-world scenarios, image impairments often manifest as composite degradations, presenting a complex interplay of elements such as low light, haze, rain, and snow. Despite this reality, existing restoration methods typically target isolated degradation types, thereby falling short in environments where multiple degrading factors coexist. To bridge this gap, our study proposes a versatile imaging model that consolidates four physical corruption paradigms to accurately represent complex, composite degradation scenarios. In this context, we propose OneRestore, a novel transformer-based framework designed for adaptive, controllable scene restoration. The proposed framework leverages a unique cross-attention mechanism, merging degraded scene descriptors with image features, allowing for nuanced restoration. Our model allows versatile input scene descriptors, ranging from manual text embeddings to automatic extractions based on visual attributes. Our methodology is further enhanced through a composite degradation restoration loss, using extra degraded images as negative samples to fortify model constraints. Comparative results on synthetic and real-world datasets demonstrate OneRestore as a superior solution, significantly advancing the state-of-the-art in addressing complex, composite degradations.