 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysVideo: Physically Plausible Video Generation with Cross-View Geometry Guidance
Mar 19, 2026Recent progress in video generation has led to substantial improvements in visual fidelity, yet ensuring physically consistent motion remains a fundamental challenge. Intuitively, this limitation can be attributed to the fact that real-world object motion unfolds in three-dimensional space, while video observations provide only partial, view-dependent projections of such dynamics. To address these issues, we propose PhysVideo, a two-stage framework that first generates physics-aware orthogonal foreground videos and then synthesizes full videos with background. In the first stage, Phys4View leverages physics-aware attention to capture the influence of physical attributes on motion dynamics, and enhances spatio-temporal consistency by incorporating geometry-enhanced cross-view attention and temporal attention. In the second stage, VideoSyn uses the generated foreground videos as guidance and learns the interactions between foreground dynamics and background context for controllable video synthesis. To support training, we construct PhysMV, a dataset containing 40K scenes, each consisting of four orthogonal viewpoints, resulting in a total of 160K video sequences. Extensive experiments demonstrate that PhysVideo significantly improves physical realism and spatial-temporal coherence over existing video generation methods. Home page: https://anonymous.4open.science/w/Phys4D/.
A Comprehensive Survey on Underwater Acoustic Target Positioning and Tracking: Progress, Challenges, and Perspectives
Jun 17, 2025Underwater target tracking technology plays a pivotal role in marine resource exploration, environmental monitoring, and national defense security. Given that acoustic waves represent an effective medium for long-distance transmission in aquatic environments, underwater acoustic target tracking has become a prominent research area of underwater communications and networking. Existing literature reviews often offer a narrow perspective or inadequately address the paradigm shifts driven by emerging technologies like deep learning and reinforcement learning. To address these gaps, this work presents a systematic survey of this field and introduces an innovative multidimensional taxonomy framework based on target scale, sensor perception modes, and sensor collaboration patterns. Within this framework, we comprehensively survey the literature (more than 180 publications) over the period 2016-2025, spanning from the theoretical foundations to diverse algorithmic approaches in underwater acoustic target tracking. Particularly, we emphasize the transformative potential and recent advancements of machine learning techniques, including deep learning and reinforcement learning, in enhancing the performance and adaptability of underwater tracking systems. Finally, this survey concludes by identifying key challenges in the field and proposing future avenues based on emerging technologies such as federated learning, blockchain, embodied intelligence, and large models.
Breaking Bad Molecules: Are MLLMs Ready for Structure-Level Molecular Detoxification?
Jun 12, 2025Toxicity remains a leading cause of early-stage drug development failure. Despite advances in molecular design and property prediction, the task of molecular toxicity repair - generating structurally valid molecular alternatives with reduced toxicity - has not yet been systematically defined or benchmarked. To fill this gap, we introduce ToxiMol, the first benchmark task for general-purpose Multimodal Large Language Models (MLLMs) focused on molecular toxicity repair. We construct a standardized dataset covering 11 primary tasks and 560 representative toxic molecules spanning diverse mechanisms and granularities. We design a prompt annotation pipeline with mechanism-aware and task-adaptive capabilities, informed by expert toxicological knowledge. In parallel, we propose an automated evaluation framework, ToxiEval, which integrates toxicity endpoint prediction, synthetic accessibility, drug-likeness, and structural similarity into a high-throughput evaluation chain for repair success. We systematically assess nearly 30 mainstream general-purpose MLLMs and design multiple ablation studies to analyze key factors such as evaluation criteria, candidate diversity, and failure attribution. Experimental results show that although current MLLMs still face significant challenges on this task, they begin to demonstrate promising capabilities in toxicity understanding, semantic constraint adherence, and structure-aware molecule editing.
Context-Aware Probabilistic Modeling with LLM for Multimodal Time Series Forecasting
May 16, 2025Time series forecasting is important for applications spanning energy markets, climate analysis, and traffic management. However, existing methods struggle to effectively integrate exogenous texts and align them with the probabilistic nature of large language models (LLMs). Current approaches either employ shallow text-time series fusion via basic prompts or rely on deterministic numerical decoding that conflict with LLMs' token-generation paradigm, which limits contextual awareness and distribution modeling. To address these limitations, we propose CAPTime, a context-aware probabilistic multimodal time series forecasting method that leverages text-informed abstraction and autoregressive LLM decoding. Our method first encodes temporal patterns using a pretrained time series encoder, then aligns them with textual contexts via learnable interactions to produce joint multimodal representations. By combining a mixture of distribution experts with frozen LLMs, we enable context-aware probabilistic forecasting while preserving LLMs' inherent distribution modeling capabilities. Experiments on diverse time series forecasting tasks demonstrate the superior accuracy and generalization of CAPTime, particularly in multimodal scenarios. Additional analysis highlights its robustness in data-scarce scenarios through hybrid probabilistic decoding.
LogisticsVLN: Vision-Language Navigation For Low-Altitude Terminal Delivery Based on Agentic UAVs
May 06, 2025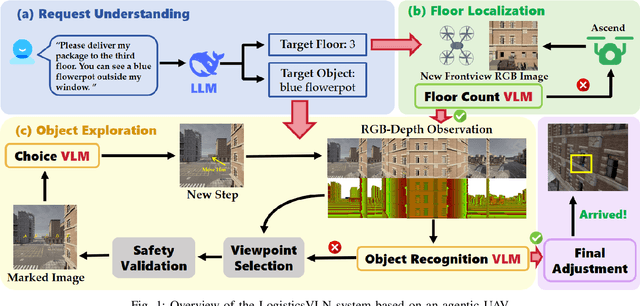
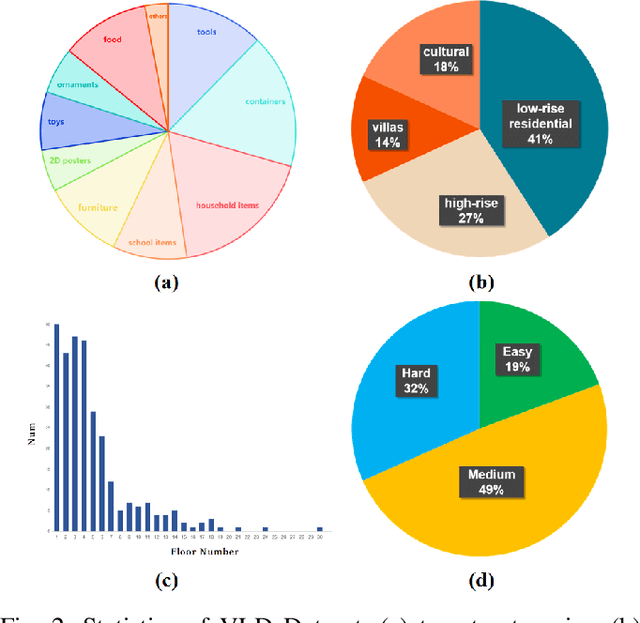

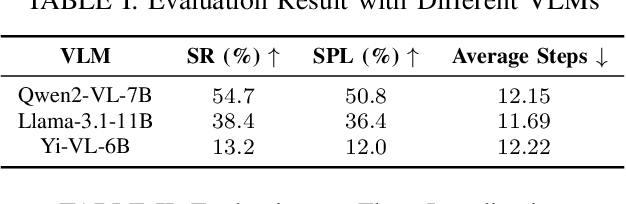
The growing demand for intelligent logistics, particularly fine-grained terminal delivery, underscores the need for autonomous UAV (Unmanned Aerial Vehicle)-based delivery systems. However, most existing last-mile delivery studies rely on ground robots, while current UAV-based Vision-Language Navigation (VLN) tasks primarily focus on coarse-grained, long-range goals, making them unsuitable for precise terminal delivery. To bridge this gap, we propose LogisticsVLN, a scalable aerial delivery system built on multimodal large language models (MLLMs) for autonomous terminal delivery. LogisticsVLN integrates lightweight Large Language Models (LLMs) and Visual-Language Models (VLMs) in a modular pipeline for request understanding, floor localization, object detection, and action-decision making. To support research and evaluation in this new setting, we construct the Vision-Language Delivery (VLD) dataset within the CARLA simulator. Experimental results on the VLD dataset showcase the feasibility of the LogisticsVLN system. In addition, we conduct subtask-level evaluations of each module of our system, offering valuable insights for improving the robustness and real-world deployment of foundation model-based vision-language delivery systems.
CoordField: Coordination Field for Agentic UAV Task Allocation In Low-altitude Urban Scenarios
Apr 30, 2025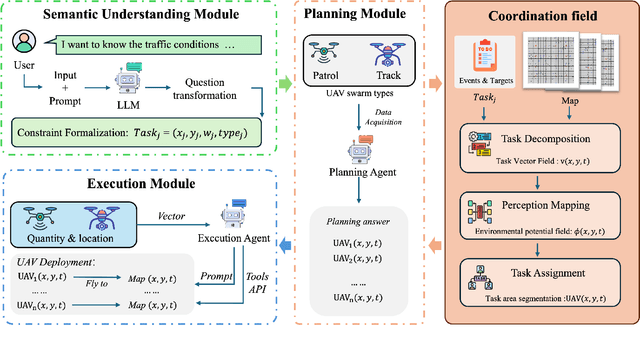
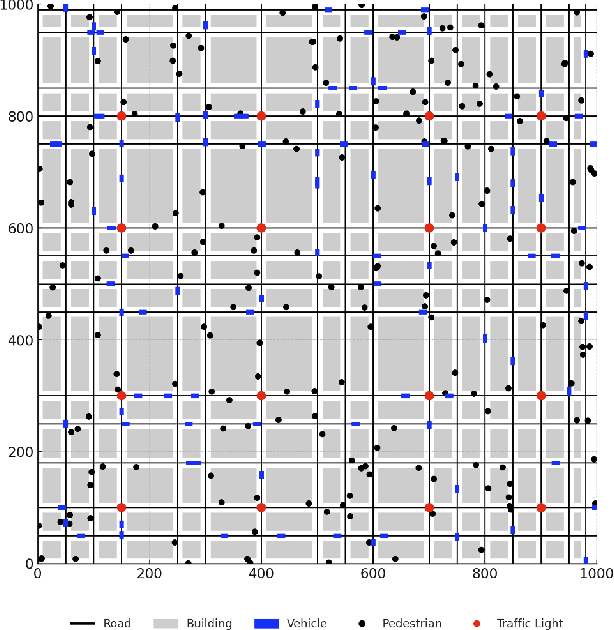
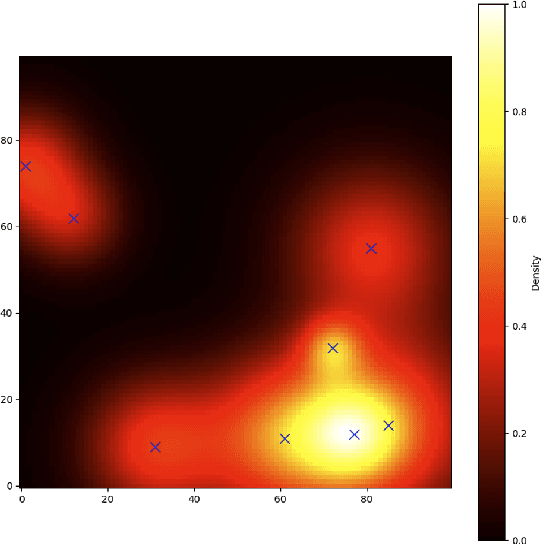
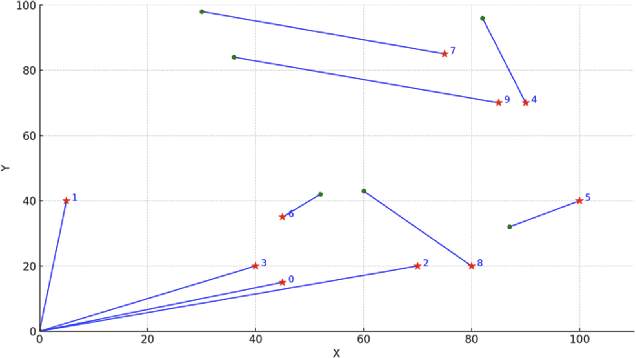
With the increasing demand for heterogeneous Unmanned Aerial Vehicle (UAV) swarms to perform complex tasks in urban environments, system design now faces major challenges, including efficient semantic understanding, flexible task planning, and the ability to dynamically adjust coordination strategies in response to evolving environmental conditions and continuously changing task requirements. To address the limitations of existing approaches, this paper proposes coordination field agentic system for coordinating heterogeneous UAV swarms in complex urban scenarios. In this system, large language models (LLMs) is responsible for interpreting high-level human instructions and converting them into executable commands for the UAV swarms, such as patrol and target tracking. Subsequently, a Coordination field mechanism is proposed to guide UAV motion and task selection, enabling decentralized and adaptive allocation of emergent tasks. A total of 50 rounds of comparative testing were conducted across different models in a 2D simulation space to evaluate their performance. Experimental results demonstrate that the proposed system achieves superior performance in terms of task coverage, response time, and adaptability to dynamic changes.
Stop Summation: Min-Form Credit Assignment Is All Process Reward Model Needs for Reasoning
Apr 21, 2025



Process reward models (PRMs) have proven effective for test-time scaling of Large Language Models (LLMs) on challenging reasoning tasks. However, reward hacking issues with PRMs limit their successful application in reinforcement fine-tuning. In this paper, we identify the main cause of PRM-induced reward hacking: the canonical summation-form credit assignment in reinforcement learning (RL), which defines the value as cumulative gamma-decayed future rewards, easily induces LLMs to hack steps with high rewards. To address this, we propose PURE: Process sUpervised Reinforcement lEarning. The key innovation of PURE is a min-form credit assignment that formulates the value function as the minimum of future rewards. This method significantly alleviates reward hacking by limiting the value function range and distributing advantages more reasonably. Through extensive experiments on 3 base models, we show that PRM-based approaches enabling min-form credit assignment achieve comparable reasoning performance to verifiable reward-based methods within only 30% steps. In contrast, the canonical sum-form credit assignment collapses training even at the beginning! Additionally, when we supplement PRM-based fine-tuning with just 10% verifiable rewards, we further alleviate reward hacking and produce the best fine-tuned model based on Qwen2.5-Math-7B in our experiments, achieving 82.5% accuracy on AMC23 and 53.3% average accuracy across 5 benchmarks. Moreover, we summarize the observed reward hacking cases and analyze the causes of training collapse. Code and models are available at https://github.com/CJReinforce/PURE.
AirVista-II: An Agentic System for Embodied UAVs Toward Dynamic Scene Semantic Understanding
Apr 13, 2025Unmanned Aerial Vehicles (UAVs) are increasingly important in dynamic environments such as logistics transportation and disaster response. However, current tasks often rely on human operators to monitor aerial videos and make operational decisions. This mode of human-machine collaboration suffers from significant limitations in efficiency and adaptability. In this paper, we present AirVista-II -- an end-to-end agentic system for embodied UAVs, designed to enable general-purpose semantic understanding and reasoning in dynamic scenes. The system integrates agent-based task identification and scheduling, multimodal perception mechanisms, and differentiated keyframe extraction strategies tailored for various temporal scenarios, enabling the efficient capture of critical scene information. Experimental results demonstrate that the proposed system achieves high-quality semantic understanding across diverse UAV-based dynamic scenarios under a zero-shot setting.
UAVs Meet LLMs: Overviews and Perspectives Toward Agentic Low-Altitude Mobility
Jan 04, 2025Low-altitude mobility, exemplified by unmanned aerial vehicles (UAVs), has introduced transformative advancements across various domains, like transportation, logistics, and agriculture. Leveraging flexible perspectives and rapid maneuverability, UAVs extend traditional systems' perception and action capabilities, garnering widespread attention from academia and industry. However, current UAV operations primarily depend on human control, with only limited autonomy in simple scenarios, and lack the intelligence and adaptability needed for more complex environments and tasks. The emergence of large language models (LLMs) demonstrates remarkable problem-solving and generalization capabilities, offering a promising pathway for advancing UAV intelligence. This paper explores the integration of LLMs and UAVs, beginning with an overview of UAV systems' fundamental components and functionalities, followed by an overview of the state-of-the-art in LLM technology. Subsequently, it systematically highlights the multimodal data resources available for UAVs, which provide critical support for training and evaluation. Furthermore, it categorizes and analyzes key tasks and application scenarios where UAVs and LLMs converge. Finally, a reference roadmap towards agentic UAVs is proposed, aiming to enable UAVs to achieve agentic intelligence through autonomous perception, memory, reasoning, and tool utilization. Related resources are available at https://github.com/Hub-Tian/UAVs_Meet_LLMs.
Heterogeneous Graph Reinforcement Learning for Dependency-aware Multi-task Allocation in Spatial Crowdsourcing
Oct 20, 2024Spatial Crowdsourcing (SC) is gaining traction in both academia and industry, with tasks on SC platforms becoming increasingly complex and requiring collaboration among workers with diverse skills. Recent research works address complex tasks by dividing them into subtasks with dependencies and assigning them to suitable workers. However, the dependencies among subtasks and their heterogeneous skill requirements, as well as the need for efficient utilization of workers' limited work time in the multi-task allocation mode, pose challenges in achieving an optimal task allocation scheme. Therefore, this paper formally investigates the problem of Dependency-aware Multi-task Allocation (DMA) and presents a well-designed framework to solve it, known as Heterogeneous Graph Reinforcement Learning-based Task Allocation (HGRL-TA). To address the challenges associated with representing and embedding diverse problem instances to ensure robust generalization, we propose a multi-relation graph model and a Compound-path-based Heterogeneous Graph Attention Network (CHANet) for effectively representing and capturing intricate relations among tasks and workers, as well as providing embedding of problem state. The task allocation decision is determined sequentially by a policy network, which undergoes simultaneous training with CHANet using the proximal policy optimization algorithm. Extensive experiment results demonstrate the effectiveness and generality of the proposed HGRL-TA in solving the DMA problem, leading to average profits that is 21.78% higher than those achieved using the metaheuristic methods.