 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken-Level Policy Optimization: Linking Group-Level Rewards to Token-Level Aggregation via Markov Likelihood
Oct 10, 2025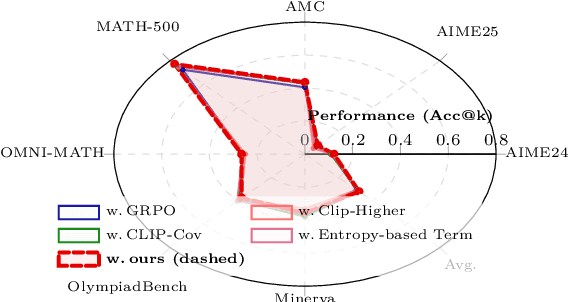
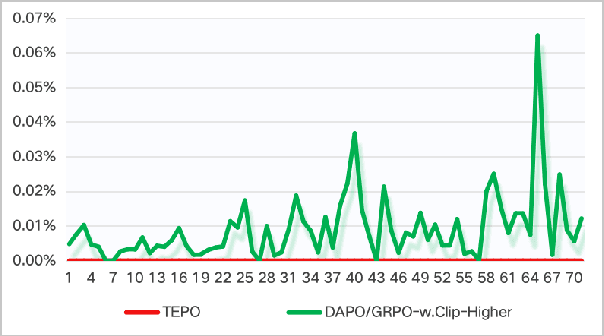
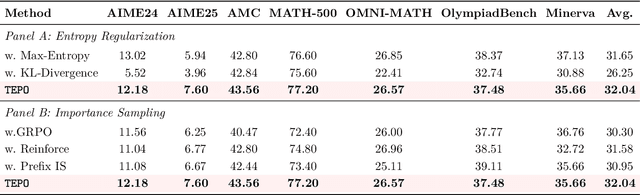
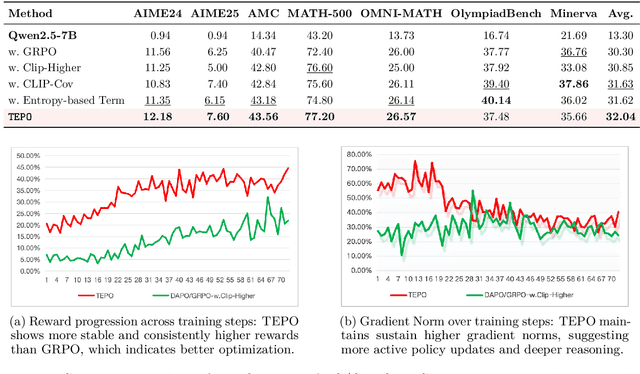
Group Relative Policy Optimization (GRPO) has significantly advanced the reasoning ability of large language models (LLMs), particularly by boosting their mathematical performance. However, GRPO and related entropy-regularization methods still face challenges rooted in the sparse token rewards inherent to chain-of-thought (CoT). Current approaches often rely on undifferentiated token-level entropy adjustments, which frequently lead to entropy collapse or model collapse. In this work, we propose TEPO, a novel token-level framework that incorporates Markov Likelihood (sequence likelihood) links group-level rewards with tokens via token-level aggregation. Experiments show that TEPO consistently outperforms existing baselines across key metrics (including @k and accuracy). It not only sets a new state of the art on mathematical reasoning tasks but also significantly enhances training stability.
Symbolic Foundation Regressor on Complex Networks
May 28, 2025In science, we are interested not only in forecasting but also in understanding how predictions are made, specifically what the interpretable underlying model looks like. Data-driven machine learning technology can significantly streamline the complex and time-consuming traditional manual process of discovering scientific laws, helping us gain insights into fundamental issues in modern science. In this work, we introduce a pre-trained symbolic foundation regressor that can effectively compress complex data with numerous interacting variables while producing interpretable physical representations. Our model has been rigorously tested on non-network symbolic regression, symbolic regression on complex networks, and the inference of network dynamics across various domains, including physics, biochemistry, ecology, and epidemiology. The results indicate a remarkable improvement in equation inference efficiency, being three times more effective than baseline approaches while maintaining accurate predictions. Furthermore, we apply our model to uncover more intuitive laws of interaction transmission from global epidemic outbreak data, achieving optimal data fitting. This model extends the application boundary of pre-trained symbolic regression models to complex networks, and we believe it provides a foundational solution for revealing the hidden mechanisms behind changes in complex phenomena, enhancing interpretability, and inspiring further scientific discoveries.
Heterogeneous Graph Reinforcement Learning for Dependency-aware Multi-task Allocation in Spatial Crowdsourcing
Oct 20, 2024Spatial Crowdsourcing (SC) is gaining traction in both academia and industry, with tasks on SC platforms becoming increasingly complex and requiring collaboration among workers with diverse skills. Recent research works address complex tasks by dividing them into subtasks with dependencies and assigning them to suitable workers. However, the dependencies among subtasks and their heterogeneous skill requirements, as well as the need for efficient utilization of workers' limited work time in the multi-task allocation mode, pose challenges in achieving an optimal task allocation scheme. Therefore, this paper formally investigates the problem of Dependency-aware Multi-task Allocation (DMA) and presents a well-designed framework to solve it, known as Heterogeneous Graph Reinforcement Learning-based Task Allocation (HGRL-TA). To address the challenges associated with representing and embedding diverse problem instances to ensure robust generalization, we propose a multi-relation graph model and a Compound-path-based Heterogeneous Graph Attention Network (CHANet) for effectively representing and capturing intricate relations among tasks and workers, as well as providing embedding of problem state. The task allocation decision is determined sequentially by a policy network, which undergoes simultaneous training with CHANet using the proximal policy optimization algorithm. Extensive experiment results demonstrate the effectiveness and generality of the proposed HGRL-TA in solving the DMA problem, leading to average profits that is 21.78% higher than those achieved using the metaheuristic methods.
From Incomplete Coarse-Grained to Complete Fine-Grained: A Two-Stage Framework for Spatiotemporal Data Reconstruction
Oct 05, 2024With the rapid development of various sensing devices, spatiotemporal data is becoming increasingly important nowadays. However, due to sensing costs and privacy concerns, the collected data is often incomplete and coarse-grained, limiting its application to specific tasks. To address this, we propose a new task called spatiotemporal data reconstruction, which aims to infer complete and fine-grained data from sparse and coarse-grained observations. To achieve this, we introduce a two-stage data inference framework, DiffRecon, grounded in the Denoising Diffusion Probabilistic Model (DDPM). In the first stage, we present Diffusion-C, a diffusion model augmented by ST-PointFormer, a powerful encoder designed to leverage the spatial correlations between sparse data points. Following this, the second stage introduces Diffusion-F, which incorporates the proposed T-PatternNet to capture the temporal pattern within sequential data. Together, these two stages form an end-to-end framework capable of inferring complete, fine-grained data from incomplete and coarse-grained observations. We conducted experiments on multiple real-world datasets to demonstrate the superiority of our method.
Toward Time-Continuous Data Inference in Sparse Urban CrowdSensing
Aug 27, 2024Mobile Crowd Sensing (MCS) is a promising paradigm that leverages mobile users and their smart portable devices to perform various real-world tasks. However, due to budget constraints and the inaccessibility of certain areas, Sparse MCS has emerged as a more practical alternative, collecting data from a limited number of target subareas and utilizing inference algorithms to complete the full sensing map. While existing approaches typically assume a time-discrete setting with data remaining constant within each sensing cycle, this simplification can introduce significant errors, especially when dealing with long cycles, as real-world sensing data often changes continuously. In this paper, we go from fine-grained completion, i.e., the subdivision of sensing cycles into minimal time units, towards a more accurate, time-continuous completion. We first introduce Deep Matrix Factorization (DMF) as a neural network-enabled framework and enhance it with a Recurrent Neural Network (RNN-DMF) to capture temporal correlations in these finer time slices. To further deal with the continuous data, we propose TIME-DMF, which captures temporal information across unequal intervals, enabling time-continuous completion. Additionally, we present the Query-Generate (Q-G) strategy within TIME-DMF to model the infinite states of continuous data. Extensive experiments across five types of sensing tasks demonstrate the effectiveness of our models and the advantages of time-continuous completion.
Detect Professional Malicious User with Metric Learning in Recommender Systems
May 19, 2022

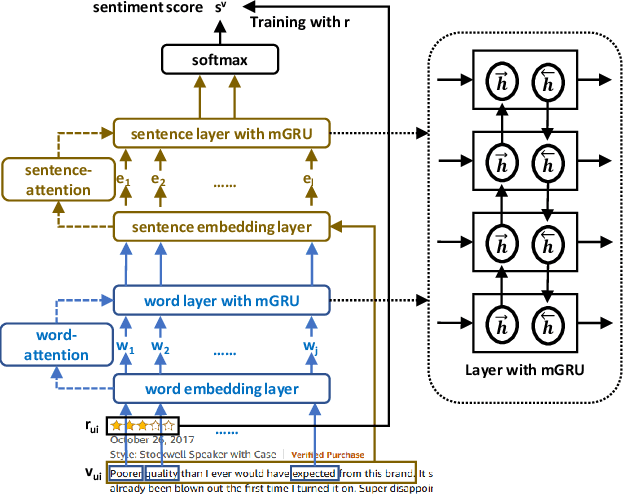
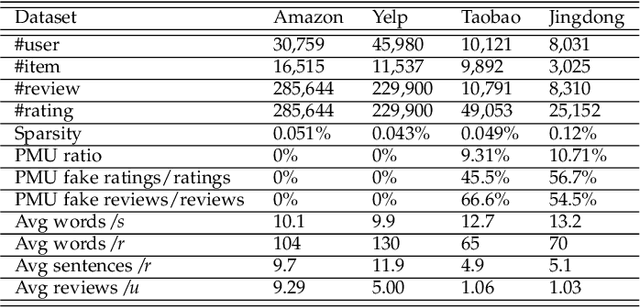
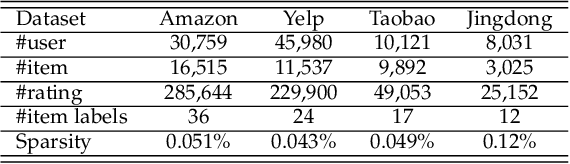
In e-commerce, online retailers are usually suffering from professional malicious users (PMUs), who utilize negative reviews and low ratings to their consumed products on purpose to threaten the retailers for illegal profits. Specifically, there are three challenges for PMU detection: 1) professional malicious users do not conduct any abnormal or illegal interactions (they never concurrently leave too many negative reviews and low ratings at the same time), and they conduct masking strategies to disguise themselves. Therefore, conventional outlier detection methods are confused by their masking strategies. 2) the PMU detection model should take both ratings and reviews into consideration, which makes PMU detection a multi-modal problem. 3) there are no datasets with labels for professional malicious users in public, which makes PMU detection an unsupervised learning problem. To this end, we propose an unsupervised multi-modal learning model: MMD, which employs Metric learning for professional Malicious users Detection with both ratings and reviews. MMD first utilizes a modified RNN to project the informational review into a sentiment score, which jointly considers the ratings and reviews. Then professional malicious user profiling (MUP) is proposed to catch the sentiment gap between sentiment scores and ratings. MUP filters the users and builds a candidate PMU set. We apply a metric learning-based clustering to learn a proper metric matrix for PMU detection. Finally, we can utilize this metric and labeled users to detect PMUs. Specifically, we apply the attention mechanism in metric learning to improve the model's performance. The extensive experiments in four datasets demonstrate that our proposed method can solve this unsupervised detection problem. Moreover, the performance of the state-of-the-art recommender models is enhanced by taking MMD as a preprocessing stage.
A Unified Collaborative Representation Learning for Neural-Network based Recommender Systems
May 19, 2022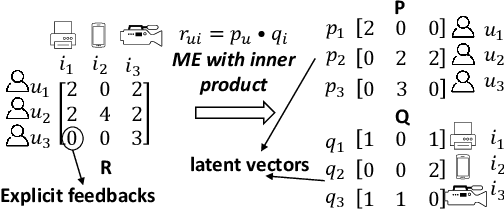
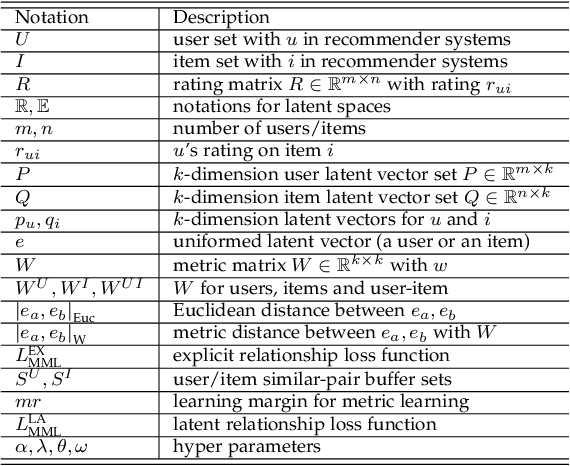
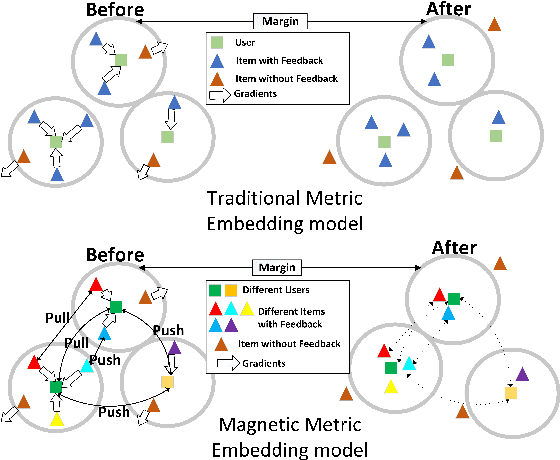
Most NN-RSs focus on accuracy by building representations from the direct user-item interactions (e.g., user-item rating matrix), while ignoring the underlying relatedness between users and items (e.g., users who rate the same ratings for the same items should be embedded into similar representations), which is an ideological disadvantage. On the other hand, ME models directly employ inner products as a default loss function metric that cannot project users and items into a proper latent space, which is a methodological disadvantage. In this paper, we propose a supervised collaborative representation learning model - Magnetic Metric Learning (MML) - to map users and items into a unified latent vector space, enhancing the representation learning for NN-RSs. Firstly, MML utilizes dual triplets to model not only the observed relationships between users and items, but also the underlying relationships between users as well as items to overcome the ideological disadvantage. Specifically, a modified metric-based dual loss function is proposed in MML to gather similar entities and disperse the dissimilar ones. With MML, we can easily compare all the relationships (user to user, item to item, user to item) according to the weighted metric, which overcomes the methodological disadvantage. We conduct extensive experiments on four real-world datasets with large item space. The results demonstrate that MML can learn a proper unified latent space for representations from the user-item matrix with high accuracy and effectiveness, and lead to a performance gain over the state-of-the-art RS models by an average of 17%.
Generating Self-Serendipity Preference in Recommender Systems for Addressing Cold Start Problems
Apr 27, 2022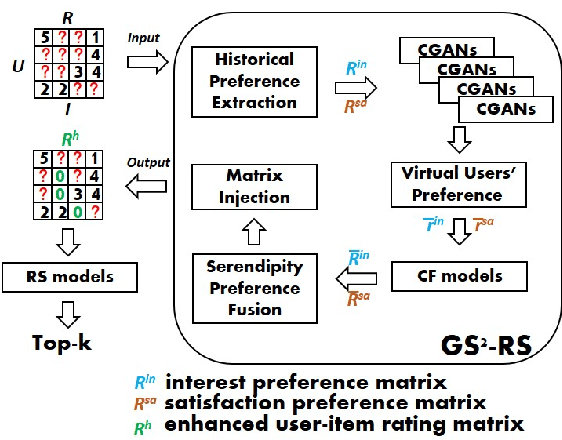

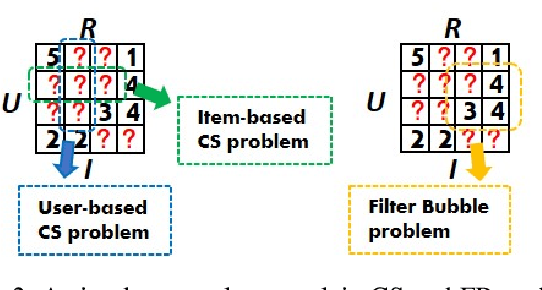
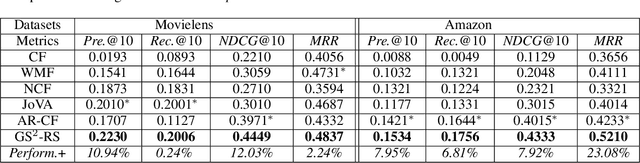
Classical accuracy-oriented Recommender Systems (RSs) typically face the cold-start problem and the filter-bubble problem when users suffer the familiar, repeated, and even predictable recommendations, making them boring and unsatisfied. To address the above issues, serendipity-oriented RSs are proposed to recommend appealing and valuable items significantly deviating from users' historical interactions and thus satisfying them by introducing unexplored but relevant candidate items to them. In this paper, we devise a novel serendipity-oriented recommender system (\textbf{G}enerative \textbf{S}elf-\textbf{S}erendipity \textbf{R}ecommender \textbf{S}ystem, \textbf{GS$^2$-RS}) that generates users' self-serendipity preferences to enhance the recommendation performance. Specifically, this model extracts users' interest and satisfaction preferences, generates virtual but convincible neighbors' preferences from themselves, and achieves their self-serendipity preference. Then these preferences are injected into the rating matrix as additional information for RS models. Note that GS$^2$-RS can not only tackle the cold-start problem but also provides diverse but relevant recommendations to relieve the filter-bubble problem. Extensive experiments on benchmark datasets illustrate that the proposed GS$^2$-RS model can significantly outperform the state-of-the-art baseline approaches in serendipity measures with a stable accuracy performance.
Cell Selection with Deep Reinforcement Learning in Sparse Mobile Crowdsensing
May 24, 2018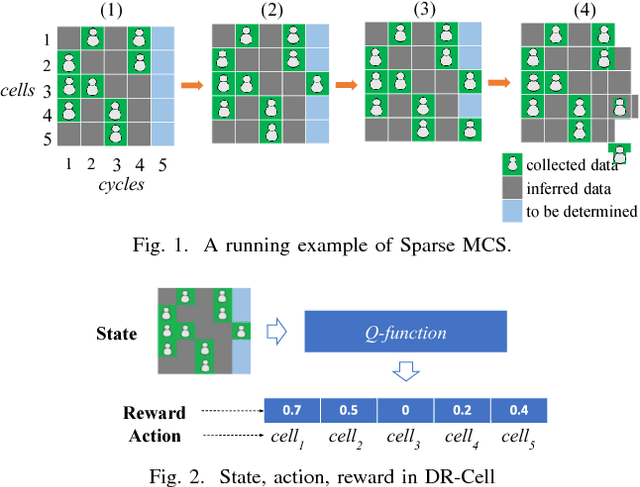
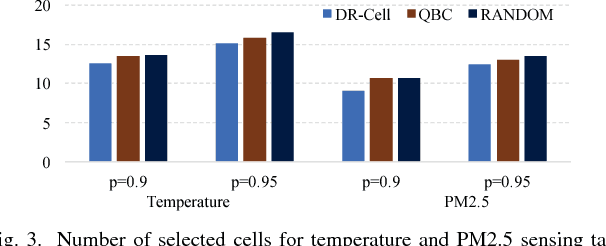
Sparse Mobile CrowdSensing (MCS) is a novel MCS paradigm where data inference is incorporated into the MCS process for reducing sensing costs while its quality is guaranteed. Since the sensed data from different cells (sub-areas) of the target sensing area will probably lead to diverse levels of inference data quality, cell selection (i.e., choose which cells of the target area to collect sensed data from participants) is a critical issue that will impact the total amount of data that requires to be collected (i.e., data collection costs) for ensuring a certain level of quality. To address this issue, this paper proposes a Deep Reinforcement learning based Cell selection mechanism for Sparse MCS, called DR-Cell. First, we properly model the key concepts in reinforcement learning including state, action, and reward, and then propose to use a deep recurrent Q-network for learning the Q-function that can help decide which cell is a better choice under a certain state during cell selection. Furthermore, we leverage the transfer learning techniques to reduce the amount of data required for training the Q-function if there are multiple correlated MCS tasks that need to be conducted in the same target area. Experiments on various real-life sensing datasets verify the effectiveness of DR-Cell over the state-of-the-art cell selection mechanisms in Sparse MCS by reducing up to 15% of sensed cells with the same data inference quality guarantee.