 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Incomplete Coarse-Grained to Complete Fine-Grained: A Two-Stage Framework for Spatiotemporal Data Reconstruction
Oct 05, 2024With the rapid development of various sensing devices, spatiotemporal data is becoming increasingly important nowadays. However, due to sensing costs and privacy concerns, the collected data is often incomplete and coarse-grained, limiting its application to specific tasks. To address this, we propose a new task called spatiotemporal data reconstruction, which aims to infer complete and fine-grained data from sparse and coarse-grained observations. To achieve this, we introduce a two-stage data inference framework, DiffRecon, grounded in the Denoising Diffusion Probabilistic Model (DDPM). In the first stage, we present Diffusion-C, a diffusion model augmented by ST-PointFormer, a powerful encoder designed to leverage the spatial correlations between sparse data points. Following this, the second stage introduces Diffusion-F, which incorporates the proposed T-PatternNet to capture the temporal pattern within sequential data. Together, these two stages form an end-to-end framework capable of inferring complete, fine-grained data from incomplete and coarse-grained observations. We conducted experiments on multiple real-world datasets to demonstrate the superiority of our method.
DPR: An Algorithm Mitigate Bias Accumulation in Recommendation feedback loops
Nov 10, 2023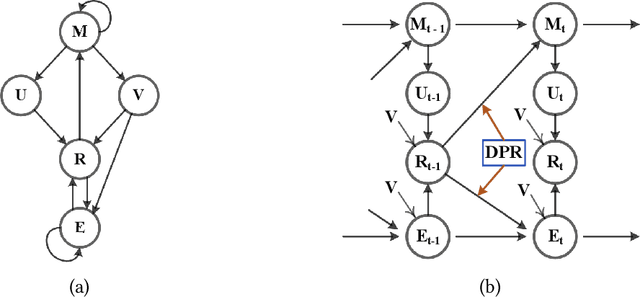


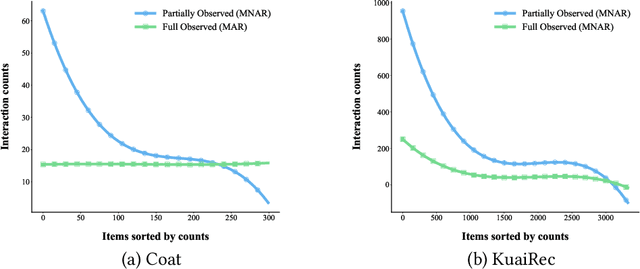
Recommendation models trained on the user feedback collected from deployed recommendation systems are commonly biased. User feedback is considerably affected by the exposure mechanism, as users only provide feedback on the items exposed to them and passively ignore the unexposed items, thus producing numerous false negative samples. Inevitably, biases caused by such user feedback are inherited by new models and amplified via feedback loops. Moreover, the presence of false negative samples makes negative sampling difficult and introduces spurious information in the user preference modeling process of the model. Recent work has investigated the negative impact of feedback loops and unknown exposure mechanisms on recommendation quality and user experience, essentially treating them as independent factors and ignoring their cross-effects. To address these issues, we deeply analyze the data exposure mechanism from the perspective of data iteration and feedback loops with the Missing Not At Random (\textbf{MNAR}) assumption, theoretically demonstrating the existence of an available stabilization factor in the transformation of the exposure mechanism under the feedback loops. We further propose Dynamic Personalized Ranking (\textbf{DPR}), an unbiased algorithm that uses dynamic re-weighting to mitigate the cross-effects of exposure mechanisms and feedback loops without additional information. Furthermore, we design a plugin named Universal Anti-False Negative (\textbf{UFN}) to mitigate the negative impact of the false negative problem. We demonstrate theoretically that our approach mitigates the negative effects of feedback loops and unknown exposure mechanisms. Experimental results on real-world datasets demonstrate that models using DPR can better handle bias accumulation and the universality of UFN in mainstream loss methods.
Causal Structure Representation Learning of Confounders in Latent Space for Recommendation
Nov 02, 2023



Inferring user preferences from the historical feedback of users is a valuable problem in recommender systems. Conventional approaches often rely on the assumption that user preferences in the feedback data are equivalent to the real user preferences without additional noise, which simplifies the problem modeling. However, there are various confounders during user-item interactions, such as weather and even the recommendation system itself. Therefore, neglecting the influence of confounders will result in inaccurate user preferences and suboptimal performance of the model. Furthermore, the unobservability of confounders poses a challenge in further addressing the problem. To address these issues, we refine the problem and propose a more rational solution. Specifically, we consider the influence of confounders, disentangle them from user preferences in the latent space, and employ causal graphs to model their interdependencies without specific labels. By cleverly combining local and global causal graphs, we capture the user-specificity of confounders on user preferences. We theoretically demonstrate the identifiability of the obtained causal graph. Finally, we propose our model based on Variational Autoencoders, named Causal Structure representation learning of Confounders in latent space (CSC). We conducted extensive experiments on one synthetic dataset and five real-world datasets, demonstrating the superiority of our model. Furthermore, we demonstrate that the learned causal representations of confounders are controllable, potentially offering users fine-grained control over the objectives of their recommendation lists with the learned causal graphs.
Separating and Learning Latent Confounders to Enhancing User Preferences Modeling
Nov 02, 2023



Recommender models aim to capture user preferences from historical feedback and then predict user-specific feedback on candidate items. However, the presence of various unmeasured confounders causes deviations between the user preferences in the historical feedback and the true preferences, resulting in models not meeting their expected performance. Existing debias models either (1) specific to solving one particular bias or (2) directly obtain auxiliary information from user historical feedback, which cannot identify whether the learned preferences are true user preferences or mixed with unmeasured confounders. Moreover, we find that the former recommender system is not only a successor to unmeasured confounders but also acts as an unmeasured confounder affecting user preference modeling, which has always been neglected in previous studies. To this end, we incorporate the effect of the former recommender system and treat it as a proxy for all unmeasured confounders. We propose a novel framework, \textbf{S}eparating and \textbf{L}earning Latent Confounders \textbf{F}or \textbf{R}ecommendation (\textbf{SLFR}), which obtains the representation of unmeasured confounders to identify the counterfactual feedback by disentangling user preferences and unmeasured confounders, then guides the target model to capture the true preferences of users. Extensive experiments in five real-world datasets validate the advantages of our method.
Deep Generative Imputation Model for Missing Not At Random Data
Aug 16, 2023



Data analysis usually suffers from the Missing Not At Random (MNAR) problem, where the cause of the value missing is not fully observed. Compared to the naive Missing Completely At Random (MCAR) problem, it is more in line with the realistic scenario whereas more complex and challenging. Existing statistical methods model the MNAR mechanism by different decomposition of the joint distribution of the complete data and the missing mask. But we empirically find that directly incorporating these statistical methods into deep generative models is sub-optimal. Specifically, it would neglect the confidence of the reconstructed mask during the MNAR imputation process, which leads to insufficient information extraction and less-guaranteed imputation quality. In this paper, we revisit the MNAR problem from a novel perspective that the complete data and missing mask are two modalities of incomplete data on an equal footing. Along with this line, we put forward a generative-model-specific joint probability decomposition method, conjunction model, to represent the distributions of two modalities in parallel and extract sufficient information from both complete data and missing mask. Taking a step further, we exploit a deep generative imputation model, namely GNR, to process the real-world missing mechanism in the latent space and concurrently impute the incomplete data and reconstruct the missing mask. The experimental results show that our GNR surpasses state-of-the-art MNAR baselines with significant margins (averagely improved from 9.9% to 18.8% in RMSE) and always gives a better mask reconstruction accuracy which makes the imputation more principle.
Detect Professional Malicious User with Metric Learning in Recommender Systems
May 19, 2022

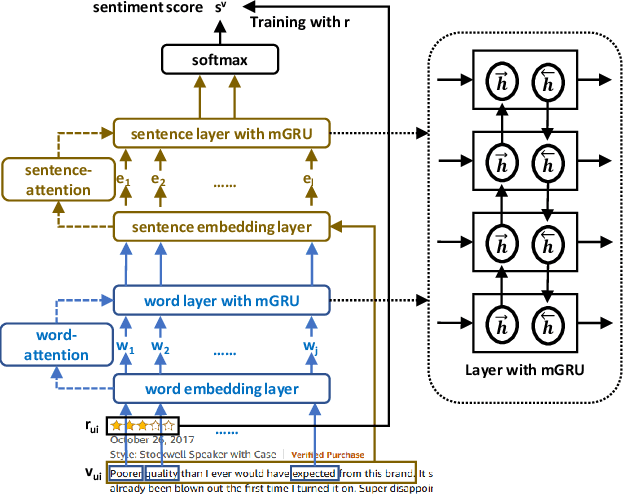
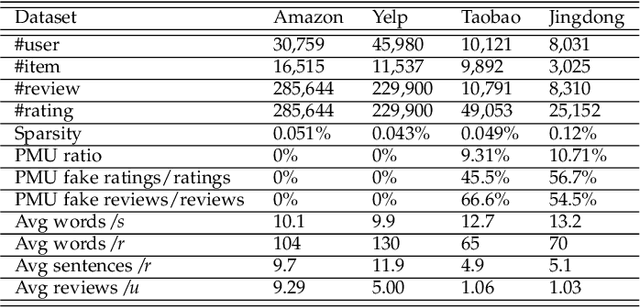
In e-commerce, online retailers are usually suffering from professional malicious users (PMUs), who utilize negative reviews and low ratings to their consumed products on purpose to threaten the retailers for illegal profits. Specifically, there are three challenges for PMU detection: 1) professional malicious users do not conduct any abnormal or illegal interactions (they never concurrently leave too many negative reviews and low ratings at the same time), and they conduct masking strategies to disguise themselves. Therefore, conventional outlier detection methods are confused by their masking strategies. 2) the PMU detection model should take both ratings and reviews into consideration, which makes PMU detection a multi-modal problem. 3) there are no datasets with labels for professional malicious users in public, which makes PMU detection an unsupervised learning problem. To this end, we propose an unsupervised multi-modal learning model: MMD, which employs Metric learning for professional Malicious users Detection with both ratings and reviews. MMD first utilizes a modified RNN to project the informational review into a sentiment score, which jointly considers the ratings and reviews. Then professional malicious user profiling (MUP) is proposed to catch the sentiment gap between sentiment scores and ratings. MUP filters the users and builds a candidate PMU set. We apply a metric learning-based clustering to learn a proper metric matrix for PMU detection. Finally, we can utilize this metric and labeled users to detect PMUs. Specifically, we apply the attention mechanism in metric learning to improve the model's performance. The extensive experiments in four datasets demonstrate that our proposed method can solve this unsupervised detection problem. Moreover, the performance of the state-of-the-art recommender models is enhanced by taking MMD as a preprocessing stage.
A Unified Collaborative Representation Learning for Neural-Network based Recommender Systems
May 19, 2022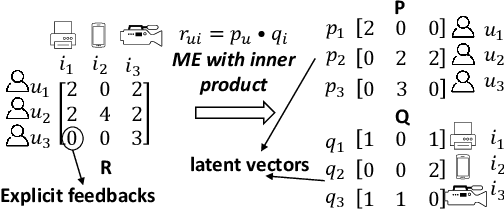
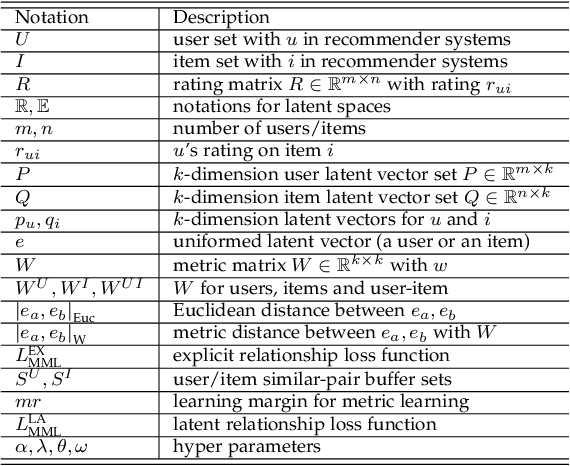
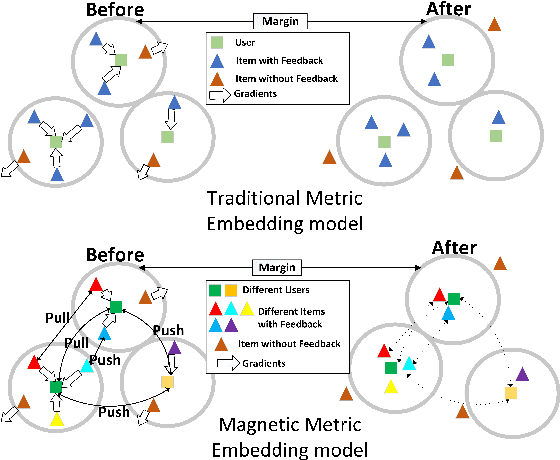
Most NN-RSs focus on accuracy by building representations from the direct user-item interactions (e.g., user-item rating matrix), while ignoring the underlying relatedness between users and items (e.g., users who rate the same ratings for the same items should be embedded into similar representations), which is an ideological disadvantage. On the other hand, ME models directly employ inner products as a default loss function metric that cannot project users and items into a proper latent space, which is a methodological disadvantage. In this paper, we propose a supervised collaborative representation learning model - Magnetic Metric Learning (MML) - to map users and items into a unified latent vector space, enhancing the representation learning for NN-RSs. Firstly, MML utilizes dual triplets to model not only the observed relationships between users and items, but also the underlying relationships between users as well as items to overcome the ideological disadvantage. Specifically, a modified metric-based dual loss function is proposed in MML to gather similar entities and disperse the dissimilar ones. With MML, we can easily compare all the relationships (user to user, item to item, user to item) according to the weighted metric, which overcomes the methodological disadvantage. We conduct extensive experiments on four real-world datasets with large item space. The results demonstrate that MML can learn a proper unified latent space for representations from the user-item matrix with high accuracy and effectiveness, and lead to a performance gain over the state-of-the-art RS models by an average of 17%.
Generating Self-Serendipity Preference in Recommender Systems for Addressing Cold Start Problems
Apr 27, 2022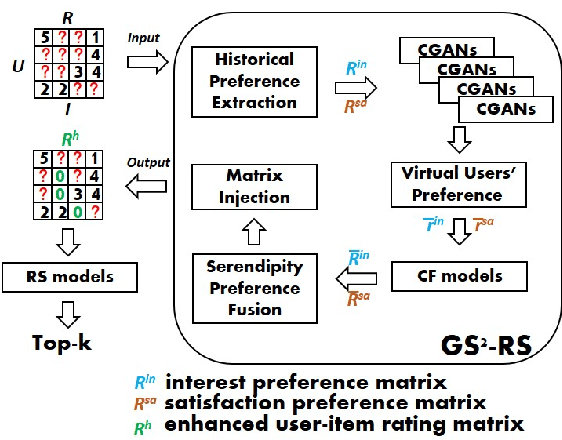

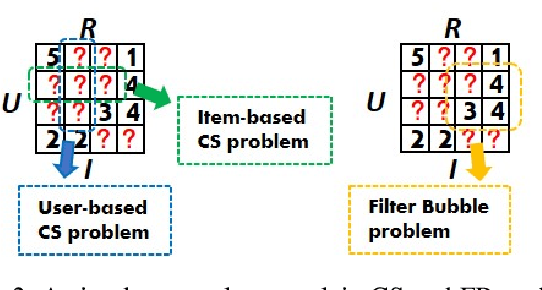
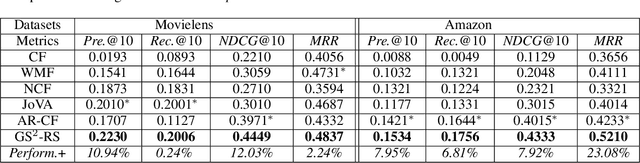
Classical accuracy-oriented Recommender Systems (RSs) typically face the cold-start problem and the filter-bubble problem when users suffer the familiar, repeated, and even predictable recommendations, making them boring and unsatisfied. To address the above issues, serendipity-oriented RSs are proposed to recommend appealing and valuable items significantly deviating from users' historical interactions and thus satisfying them by introducing unexplored but relevant candidate items to them. In this paper, we devise a novel serendipity-oriented recommender system (\textbf{G}enerative \textbf{S}elf-\textbf{S}erendipity \textbf{R}ecommender \textbf{S}ystem, \textbf{GS$^2$-RS}) that generates users' self-serendipity preferences to enhance the recommendation performance. Specifically, this model extracts users' interest and satisfaction preferences, generates virtual but convincible neighbors' preferences from themselves, and achieves their self-serendipity preference. Then these preferences are injected into the rating matrix as additional information for RS models. Note that GS$^2$-RS can not only tackle the cold-start problem but also provides diverse but relevant recommendations to relieve the filter-bubble problem. Extensive experiments on benchmark datasets illustrate that the proposed GS$^2$-RS model can significantly outperform the state-of-the-art baseline approaches in serendipity measures with a stable accuracy performance.
Cell Selection with Deep Reinforcement Learning in Sparse Mobile Crowdsensing
May 24, 2018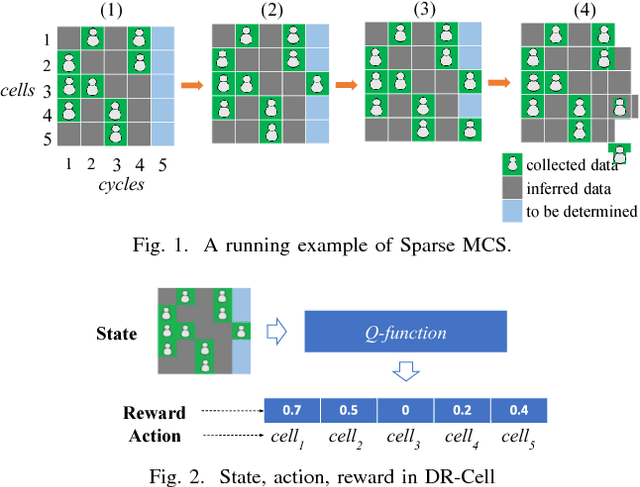
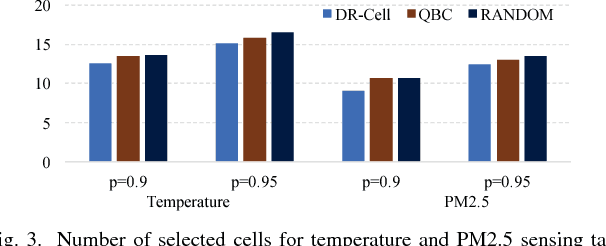
Sparse Mobile CrowdSensing (MCS) is a novel MCS paradigm where data inference is incorporated into the MCS process for reducing sensing costs while its quality is guaranteed. Since the sensed data from different cells (sub-areas) of the target sensing area will probably lead to diverse levels of inference data quality, cell selection (i.e., choose which cells of the target area to collect sensed data from participants) is a critical issue that will impact the total amount of data that requires to be collected (i.e., data collection costs) for ensuring a certain level of quality. To address this issue, this paper proposes a Deep Reinforcement learning based Cell selection mechanism for Sparse MCS, called DR-Cell. First, we properly model the key concepts in reinforcement learning including state, action, and reward, and then propose to use a deep recurrent Q-network for learning the Q-function that can help decide which cell is a better choice under a certain state during cell selection. Furthermore, we leverage the transfer learning techniques to reduce the amount of data required for training the Q-function if there are multiple correlated MCS tasks that need to be conducted in the same target area. Experiments on various real-life sensing datasets verify the effectiveness of DR-Cell over the state-of-the-art cell selection mechanisms in Sparse MCS by reducing up to 15% of sensed cells with the same data inference quality guarantee.