 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Extrapolation: Knowledge Utilization Paradigm with Bidirectional Inspiration for Time Series Forecasting
May 19, 2026Time-series forecasting is critical in various scenarios, such as energy, transportation, and public health. However, most existing forecasters rely primarily on one-way inference, \textit{i.e.}, mapping \textbf{history} to \textbf{target}, and overlook the structural information provided by a revised natural chain (``\textbf{history} (model input) -- \textbf{target} (ground-truth output) -- \textbf{post-target continuation}''). The post-target continuation records how trajectories evolve after the target, which can help stabilize forecasting, but it is not observable at inference time. In this work, we aim to obtain an approximate proxy of the post-target continuation for the current input, providing structural knowledge for bidirectional forecasting. This idea is instantiated as KUP-BI (Knowledge Utilization Paradigm with Bidirectional Inspiration), a new time-series modeling paradigm that distills continuation-style knowledge (as an approximate post-target continuation proxy) from a \emph{train-only} historical library and integrates it into standard forecasting backbones. The input stream and the continuation-proxy stream are fused via a lightweight feature-level gating module. This design does not introduce information beyond what is already contained in the training trajectories; instead, it provides a structured inductive bias that helps backbones exploit typical continuation patterns rather than relying solely on parametric extrapolation. Experimental results on six public datasets show that KUP-BI consistently improves the forecasting performance of state-of-the-art models, with small additional overhead.
SeesawNet: Towards Non-stationary Time Series Forecasting with Balanced Modeling of Common and Specific Dependencies
May 14, 2026Instance normalization (IN) is widely used in non-stationary multivariate time series forecasting to reduce distribution shifts and highlight common patterns across samples. However, IN can over-smooth instance-specific structural information that is essential for modeling temporal and cross-channel heterogeneity. While prior methods further suppress distribution discrepancies or attempt to recover temporal specific dependencies, they often ignore a central tension: how to adaptively model common and instance-specific dependency based on each instance's non-stationary structures. To address this dilemma, we propose SeesawNet, a unified architecture that dynamically balances common and instance-specific dependency modeling in both temporal and channel dimensions. At its core is Adaptive Stationary-Nonstationary Attention (ASNA), which captures common dependencies from normalized sequences and specific dependencies from raw sequences, and adaptively fuses them according to instance-level non-stationarity. Built upon ASNA, SeesawNet alternates dedicated temporal and channel relationship modeling to jointly capture long-range and cross-variable dependencies. Extensive experiments on multiple real-world benchmarks demonstrate that SeesawNet consistently outperforms state-of-the-art methods.
From Passive Reuse to Active Reasoning: Grounding Large Language Models for Neuro-Symbolic Experience Replay
May 10, 2026While experience replay is essential for data efficiency in reinforcement learning (RL), standard methods treat the replay buffer as a passive memory system, prioritizing samples based on numerical prediction errors rather than their semantic significance. This approach stands in contrast to human learning, which accelerates mastery by actively abstracting fragmented experiences into behavioral rules. To bridge this gap, we propose Neuro-Symbolic Experience Replay (NSER), a framework that transforms experience replay from a passive sample reuse mechanism into an active engine for knowledge construction. Specifically, NSER addresses the incompatibility between linguistic reasoning and numerical optimization through a novel neuro-symbolic grounding pipeline. It leverages Large Language Models (LLMs) in a zero-shot manner to induce candidate behavioral rules from accumulated trajectories, grounds these insights into differentiable first-order logic representations, and utilizes the resulting symbolic structures to dynamically reweight the replay distribution. By allowing abstract knowledge to directly shape policy optimization, NSER achieves consistent superior sample efficiency and convergence speed across reactive, rule-based, and procedural benchmarks.
Computer-Aided Design Generation by Cascaded Discrete Diffusion Model
May 06, 2026Recent deep learning approaches seek to automate CAD creation by representing a model as a sequence of discrete commands and parameters, and then generating them using autoregressive models or continuous diffusion operating in Euclidean embedding space. However, continuous diffusion perturbs representations in a continuous Euclidean domain that does not reflect the inherently discrete and heterogeneous nature of CAD tokens, often producing perturbed representations that map to semantically invalid symbols. To overcome this limitation, we propose a cascaded discrete diffusion framework for CAD generation, which consists of a command diffusion for generating CAD commands and a parameter diffusion conditioned on CAD commands. Unlike isotropic Gaussian perturbation, the forward process of our approach operates directly over categorical token distributions using delicate transition matrices. For commands, we adopt an absorbing-state transition matrix that progressively corrupts tokens to a designated symbol; for parameters, we introduce specific transition matrices tailored to heterogeneous attributes: a Gaussian kernel for coordinate continuity, a scale-invariant kernel for dimensional values, and a prior-preserving kernel for boolean attributes. The reverse process is achieved by two denoising networks: a Transformer-based encoder for command recovery, and a parameter network with extra local self-attention for command-level interaction and cross-attention for conditional injection. Experiments on the DeepCAD dataset show that the proposed approach surpasses existing autoregressive and continuous diffusion models on unconditional generation metrics, while qualitative results validate effective controllability in conditional generation tasks. Source codes will be released.
Metric-agnostic Learning-to-Rank via Boosting and Rank Approximation
Apr 16, 2026Learning-to-Rank (LTR) is a supervised machine learning approach that constructs models specifically designed to order a set of items or documents based on their relevance or importance to a given query or context. Despite significant success in real-world information retrieval systems, current LTR methods rely on one prefix ranking metric (e.g., such as Normalized Discounted Cumulative Gain (NDCG) or Mean Average Precision (MAP)) for optimizing the ranking objective function. Such metric-dependent setting limits LTR methods from two perspectives: (1) non-differentiable problem: directly optimizing ranking functions over a given ranking metric is inherently non-smooth, making the training process unstable and inefficient; (2) limited ranking utility: optimizing over one single metric makes it difficult to generalize well to other ranking metrics of interest. To address the above issues, we propose a novel listwise LTR framework for efficient and generalizable ranking purpose. Specifically, we propose a new differentiable ranking loss that combines a smooth approximation to the ranking operator with the average mean square loss per query. Then, we adapt gradient-boosting machines to minimize our proposed loss with respect to each list, a novel contribution. Finally, extensive experimental results confirm that our method outperforms the current state-of-the-art in information retrieval measures with similar efficiency.
Dummy-Aware Weighted Attack (DAWA): Breaking the Safe Sink in Dummy Class Defenses
Mar 31, 2026Adversarial robustness evaluation faces a critical challenge as new defense paradigms emerge that can exploit limitations in existing assessment methods. This paper reveals that Dummy Classes-based defenses, which introduce an additional "dummy" class as a safety sink for adversarial examples, achieve significantly overestimated robustness under conventional evaluation strategies like AutoAttack. The fundamental limitation stems from these attacks' singular focus on misleading the true class label, which aligns perfectly with the defense mechanism--successful attacks are simply captured by the dummy class. To address this gap, we propose Dummy-Aware Weighted Attack (DAWA), a novel evaluation method that simultaneously targets both the true label and dummy label with adaptive weighting during adversarial example synthesis. Extensive experiments demonstrate that DAWA effectively breaks this defense paradigm, reducing the measured robustness of a leading Dummy Classes-based defense from 58.61% to 29.52% on CIFAR-10 under l_infty perturbation (epsilon=8/255). Our work provides a more reliable benchmark for evaluating this emerging class of defenses and highlights the need for continuous evolution of robustness assessment methodologies.
Differentiable Zero-One Loss via Hypersimplex Projections
Feb 26, 2026Recent advances in machine learning have emphasized the integration of structured optimization components into end-to-end differentiable models, enabling richer inductive biases and tighter alignment with task-specific objectives. In this work, we introduce a novel differentiable approximation to the zero-one loss-long considered the gold standard for classification performance, yet incompatible with gradient-based optimization due to its non-differentiability. Our method constructs a smooth, order-preserving projection onto the n,k-dimensional hypersimplex through a constrained optimization framework, leading to a new operator we term Soft-Binary-Argmax. After deriving its mathematical properties, we show how its Jacobian can be efficiently computed and integrated into binary and multiclass learning systems. Empirically, our approach achieves significant improvements in generalization under large-batch training by imposing geometric consistency constraints on the output logits, thereby narrowing the performance gap traditionally observed in large-batch training.
S$^4$C: Speculative Sampling with Syntactic and Semantic Coherence for Efficient Inference of Large Language Models
Jun 17, 2025Large language models (LLMs) exhibit remarkable reasoning capabilities across diverse downstream tasks. However, their autoregressive nature leads to substantial inference latency, posing challenges for real-time applications. Speculative sampling mitigates this issue by introducing a drafting phase followed by a parallel validation phase, enabling faster token generation and verification. Existing approaches, however, overlook the inherent coherence in text generation, limiting their efficiency. To address this gap, we propose a Speculative Sampling with Syntactic and Semantic Coherence (S$^4$C) framework, which extends speculative sampling by leveraging multi-head drafting for rapid token generation and a continuous verification tree for efficient candidate validation and feature reuse. Experimental results demonstrate that S$^4$C surpasses baseline methods across mainstream tasks, offering enhanced efficiency, parallelism, and the ability to generate more valid tokens with fewer computational resources. On Spec-bench benchmarks, S$^4$C achieves an acceleration ratio of 2.26x-2.60x, outperforming state-of-the-art methods.
GCAL: Adapting Graph Models to Evolving Domain Shifts
May 22, 2025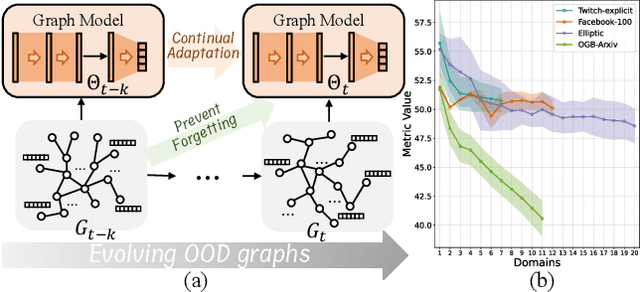
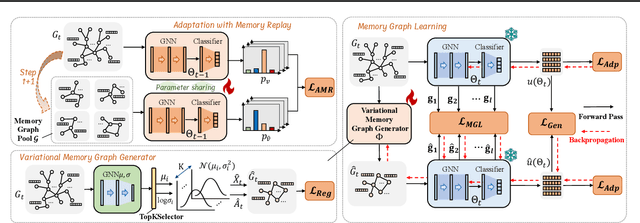
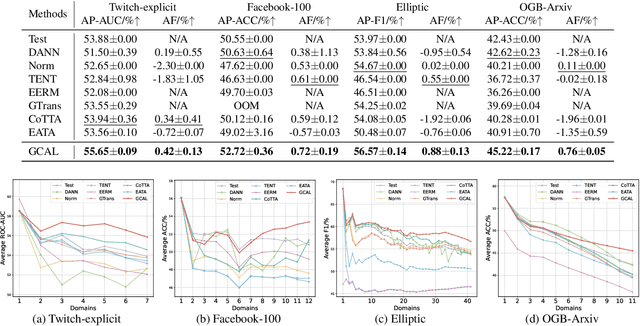
This paper addresses the challenge of graph domain adaptation on evolving, multiple out-of-distribution (OOD) graphs. Conventional graph domain adaptation methods are confined to single-step adaptation, making them ineffective in handling continuous domain shifts and prone to catastrophic forgetting. This paper introduces the Graph Continual Adaptive Learning (GCAL) method, designed to enhance model sustainability and adaptability across various graph domains. GCAL employs a bilevel optimization strategy. The "adapt" phase uses an information maximization approach to fine-tune the model with new graph domains while re-adapting past memories to mitigate forgetting. Concurrently, the "generate memory" phase, guided by a theoretical lower bound derived from information bottleneck theory, involves a variational memory graph generation module to condense original graphs into memories. Extensive experimental evaluations demonstrate that GCAL substantially outperforms existing methods in terms of adaptability and knowledge retention.
Disentangled Multi-span Evolutionary Network against Temporal Knowledge Graph Reasoning
May 20, 2025Temporal Knowledge Graphs (TKGs), as an extension of static Knowledge Graphs (KGs), incorporate the temporal feature to express the transience of knowledge by describing when facts occur. TKG extrapolation aims to infer possible future facts based on known history, which has garnered significant attention in recent years. Some existing methods treat TKG as a sequence of independent subgraphs to model temporal evolution patterns, demonstrating impressive reasoning performance. However, they still have limitations: 1) In modeling subgraph semantic evolution, they usually neglect the internal structural interactions between subgraphs, which are actually crucial for encoding TKGs. 2) They overlook the potential smooth features that do not lead to semantic changes, which should be distinguished from the semantic evolution process. Therefore, we propose a novel Disentangled Multi-span Evolutionary Network (DiMNet) for TKG reasoning. Specifically, we design a multi-span evolution strategy that captures local neighbor features while perceiving historical neighbor semantic information, thus enabling internal interactions between subgraphs during the evolution process. To maximize the capture of semantic change patterns, we design a disentangle component that adaptively separates nodes' active and stable features, used to dynamically control the influence of historical semantics on future evolution. Extensive experiments conducted on four real-world TKG datasets show that DiMNet demonstrates substantial performance in TKG reasoning, and outperforms the state-of-the-art up to 22.7% in MRR.