 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynaTree: Dynamic Agentic Retrieval Tree for Time-Sensitive News Retrieval
May 29, 2026Agentic Retrieval-Augmented Generation improves retrieval by integrating planning, tool use, and iterative reasoning, but existing agentic RAG methods often couple semantic expansion with retrieval decisions in short-horizon inference loops, leading to high inference cost and limited suitability for time-sensitive news retrieval. We propose DynaTree, a two-stage framework for efficient and adaptive news retrieval. In the offline stage, DynaTree uses coordinated agents to construct a reusable retrieval tree that materializes the semantic space of a query topic. In the online stage, DynaTree performs lightweight daily subtree selection over a time-localized evaluation proxy, without further agentic reasoning, tree modification, or retraining. Experiments on a multi-day Syft news benchmark and multiple BEIR datasets show that DynaTree achieves strong recall and ranking performance, consistently outperforming standard RAG and prior agentic baselines. We further deploy DynaTree in the Syft production system and evaluate it through online A/B testing from Jan. 28 to Feb. 6, 2026. The dynamically adapted variant improves survival rate from 0.32-0.53 to 0.59-0.73 over a fixed offline-selected subtree and outperforms existing production recallers on every evaluation day. These results show that persistent, structure-aware semantic expansion can translate offline agentic reasoning into practical improvements in coverage, freshness, and relevance for real-world news retrieval.
R^2-Mem: Reflective Experience for Memory Search
May 13, 2026Deep search has recently emerged as a promising paradigm for enabling agents to retrieve fine-grained historical information without heavy memory pre-managed. However, existing deep search agents for memory system repeat past error behaviors because they fail to learn from the prior high- and low-quality search trajectories. To address this limitation, we propose R^2-Mem, a reflective experience framework for memory search systems. In the offline stage, a Rubric-guided Evaluator scores low- and high-quality steps in historical trajectories, and a self-Reflection Learner distills the corresponding abstract experience. During the online inference, the retrieved experience will guide future search actions to avoid repeated mistakes and maintain high-quality behaviors. Extensive experiments demonstrate that R^2-Mem consistently improves both effectiveness and efficiency over strong baselines, improving F1 scores by up to 22.6%, while reducing token consumption by 12.9% and search iterations by 20.2%. These results verify that R^2-Mem provides a RL-free and low-cost solution for self-improving LLM agents.
Do Phone-Use Agents Respect Your Privacy?
Apr 02, 2026We study whether phone-use agents respect privacy while completing benign mobile tasks. This question has remained hard to answer because privacy-compliant behavior is not operationalized for phone-use agents, and ordinary apps do not reveal exactly what data agents type into which form entries during execution. To make this question measurable, we introduce MyPhoneBench, a verifiable evaluation framework for privacy behavior in mobile agents. We operationalize privacy-respecting phone use as permissioned access, minimal disclosure, and user-controlled memory through a minimal privacy contract, iMy, and pair it with instrumented mock apps plus rule-based auditing that make unnecessary permission requests, deceptive re-disclosure, and unnecessary form filling observable and reproducible. Across five frontier models on 10 mobile apps and 300 tasks, we find that task success, privacy-compliant task completion, and later-session use of saved preferences are distinct capabilities, and no single model dominates all three. Evaluating success and privacy jointly reshuffles the model ordering relative to either metric alone. The most persistent failure mode across models is simple data minimization: agents still fill optional personal entries that the task does not require. These results show that privacy failures arise from over-helpful execution of benign tasks, and that success-only evaluation overestimates the deployment readiness of current phone-use agents. All code, mock apps, and agent trajectories are publicly available at~ https://github.com/FreedomIntelligence/MyPhoneBench.
Causally-Guided Diffusion for Stable Feature Selection
Mar 21, 2026Feature selection is fundamental to robust data-centric AI, but most existing methods optimize predictive performance under a single data distribution. This often selects spurious features that fail under distribution shifts. Motivated by principles from causal invariance, we study feature selection from a stability perspective and introduce Causally-Guided Diffusion for Stable Feature Selection (CGDFS). In CGDFS, we formalized feature selection as approximate posterior inference over feature subsets, whose posterior mass favors low prediction error and low cross-environment variance. Our framework combines three key insights: First, we formulate feature selection as stability-aware posterior sampling. Here, causal invariance serves as a soft inductive bias rather than explicit causal discovery. Second, we train a diffusion model as a learned prior over plausible continuous selection masks, combined with a stability-aware likelihood that rewards invariance across environments. This diffusion prior captures structural dependencies among features and enables scalable exploration of the combinatorially large selection space. Third, we perform guided annealed Langevin sampling that combines the diffusion prior with the stability objective, which yields a tractable, uncertainty-aware posterior inference that avoids discrete optimization and produces robust feature selections. We evaluate CGDFS on open-source real-world datasets exhibiting distribution shifts. Across both classification and regression tasks, CGDFS consistently selects more stable and transferable feature subsets, which leads to improved out-of-distribution performance and greater selection robustness compared to sparsity-based, tree-based, and stability-selection baselines.
Walking on Rough Terrain with Any Number of Legs
Mar 10, 2026Robotics would gain by replicating the remarkable agility of arthropods in navigating complex environments. Here we consider the control of multi-legged systems which have 6 or more legs. Current multi-legged control strategies in robots include large black-box machine learning models, Central Pattern Generator (CPG) networks, and open-loop feed-forward control with stability arising from mechanics. Here we present a multi-legged control architecture for rough terrain using a segmental robot with 3 actuators for every 2 legs, which we validated in simulation for robots with 6 to 16 legs. Segments have identical state machines, and each segment also receives input from the segment in front of it. Our design bridges the gap between WalkNet-like event cascade controllers and CPG-based controllers: it tightly couples to the ground when contact is present, but produces fictive locomotion when ground contact is missing. The approach may be useful as an adaptive and computationally lightweight controller for multi-legged robots, and as a baseline capability for scaffolding the learning of machine learning controllers.
BandPO: Bridging Trust Regions and Ratio Clipping via Probability-Aware Bounds for LLM Reinforcement Learning
Mar 05, 2026Proximal constraints are fundamental to the stability of the Large Language Model reinforcement learning. While the canonical clipping mechanism in PPO serves as an efficient surrogate for trust regions, we identify a critical bottleneck: fixed bounds strictly constrain the upward update margin of low-probability actions, disproportionately suppressing high-advantage tail strategies and inducing rapid entropy collapse. To address this, we introduce Band-constrained Policy Optimization (BandPO). BandPO replaces canonical clipping with Band, a unified theoretical operator that projects trust regions defined by f-divergences into dynamic, probability-aware clipping intervals. Theoretical analysis confirms that Band effectively resolves this exploration bottleneck. We formulate this mapping as a convex optimization problem, guaranteeing a globally optimal numerical solution while deriving closed-form solutions for specific divergences. Extensive experiments across diverse models and datasets demonstrate that BandPO consistently outperforms canonical clipping and Clip-Higher, while robustly mitigating entropy collapse.
Towards reconstructing experimental sparse-view X-ray CT data with diffusion models
Feb 13, 2026Diffusion-based image generators are promising priors for ill-posed inverse problems like sparse-view X-ray Computed Tomography (CT). As most studies consider synthetic data, it is not clear whether training data mismatch (``domain shift'') or forward model mismatch complicate their successful application to experimental data. We measured CT data from a physical phantom resembling the synthetic Shepp-Logan phantom and trained diffusion priors on synthetic image data sets with different degrees of domain shift towards it. Then, we employed the priors in a Decomposed Diffusion Sampling scheme on sparse-view CT data sets with increasing difficulty leading to the experimental data. Our results reveal that domain shift plays a nuanced role: while severe mismatch causes model collapse and hallucinations, diverse priors outperform well-matched but narrow priors. Forward model mismatch pulls the image samples away from the prior manifold, which causes artifacts but can be mitigated with annealed likelihood schedules that also increase computational efficiency. Overall, we demonstrate that performance gains do not immediately translate from synthetic to experimental data, and future development must validate against real-world benchmarks.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Graph AI generates neurological hypotheses validated in molecular, organoid, and clinical systems
Dec 13, 2025Neurological diseases are the leading global cause of disability, yet most lack disease-modifying treatments. We present PROTON, a heterogeneous graph transformer that generates testable hypotheses across molecular, organoid, and clinical systems. To evaluate PROTON, we apply it to Parkinson's disease (PD), bipolar disorder (BD), and Alzheimer's disease (AD). In PD, PROTON linked genetic risk loci to genes essential for dopaminergic neuron survival and predicted pesticides toxic to patient-derived neurons, including the insecticide endosulfan, which ranked within the top 1.29% of predictions. In silico screens performed by PROTON reproduced six genome-wide $α$-synuclein experiments, including a split-ubiquitin yeast two-hybrid system (normalized enrichment score [NES] = 2.30, FDR-adjusted $p < 1 \times 10^{-4}$), an ascorbate peroxidase proximity labeling assay (NES = 2.16, FDR $< 1 \times 10^{-4}$), and a high-depth targeted exome sequencing study in 496 synucleinopathy patients (NES = 2.13, FDR $< 1 \times 10^{-4}$). In BD, PROTON predicted calcitriol as a candidate drug that reversed proteomic alterations observed in cortical organoids derived from BD patients. In AD, we evaluated PROTON predictions in health records from $n = 610,524$ patients at Mass General Brigham, confirming that five PROTON-predicted drugs were associated with reduced seven-year dementia risk (minimum hazard ratio = 0.63, 95% CI: 0.53-0.75, $p < 1 \times 10^{-7}$). PROTON generated neurological hypotheses that were evaluated across molecular, organoid, and clinical systems, defining a path for AI-driven discovery in neurological disease.
Dataforge: A Data Agent Platform for Autonomous Data Engineering
Nov 09, 2025
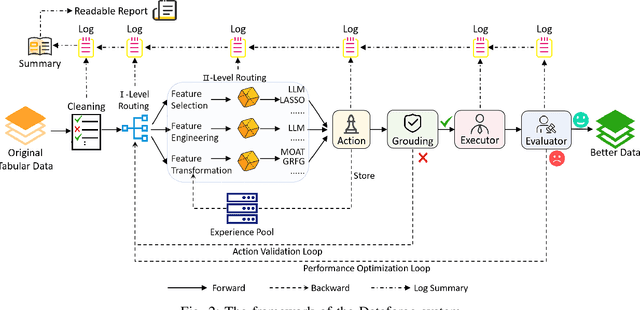
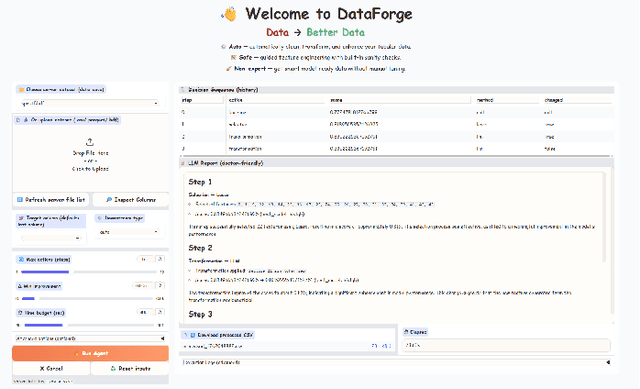
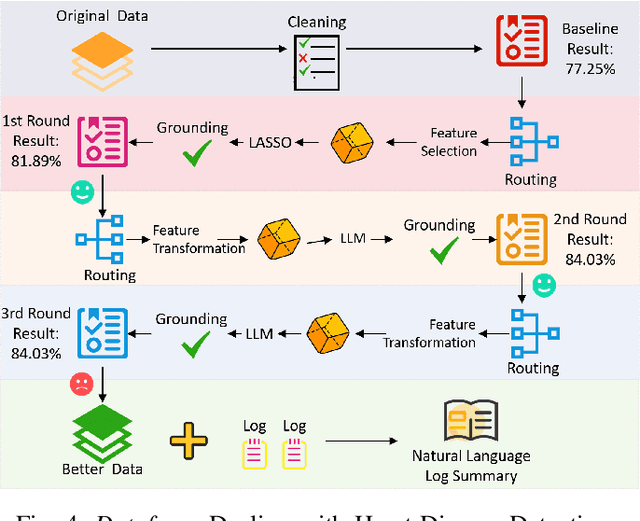
The growing demand for AI applications in fields such as materials discovery, molecular modeling, and climate science has made data preparation an important but labor-intensive step. Raw data from diverse sources must be cleaned, normalized, and transformed to become AI-ready, while effective feature transformation and selection are essential for efficient training and inference. To address the challenges of scalability and expertise dependence, we present Data Agent, a fully autonomous system specialized for tabular data. Leveraging large language model (LLM) reasoning and grounded validation, Data Agent automatically performs data cleaning, hierarchical routing, and feature-level optimization through dual feedback loops. It embodies three core principles: automatic, safe, and non-expert friendly, which ensure end-to-end reliability without human supervision. This demo showcases the first practical realization of an autonomous Data Agent, illustrating how raw data can be transformed "From Data to Better Data."