 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaC: Advancing Video Reward Models via Hierarchical Spatiotemporal Concentrating
May 12, 2026In this paper, we propose Concentrate and Concentrate (CaC), a coarse-to-fine anomaly reward model based on Vision-Language Models. During inference, it first conducts a global temporal scan to anchor anomalous time windows, then performs fine-grained spatial grounding within the localized interval, and finally derives robust judgments via structured spatiotemporal Chain-of-Thought reasoning. To equip the model with these capabilities, we construct the first large-scale generated video anomaly dataset with per-frame bounding-box annotations, temporal anomaly windows, and fine-grained attribution labels. Building on this dataset, we design a three-stage progressive training paradigm. The model initially learns spatial and temporal anchoring through single- and multi-frame supervised fine-tuning, and then is optimized by a reinforcement learning strategy based on two-turn Group Relative Policy Optimization (GRPO). Beyond conventional accuracy rewards, we introduce Temporal and Spatial IoU rewards to supervise the intermediate localization process, effectively guiding the model toward more grounded and interpretable spatiotemporal reasoning. Extensive experiments demonstrate that CaC can stably concentrate on subtle anomalies, achieving a 25.7% accuracy improvement on fine-grained anomaly benchmarks and, when used as a reward signal, CaC reduces generated-video anomalies by 11.7% while improving overall video quality.
MedVAR: Towards Scalable and Efficient Medical Image Generation via Next-scale Autoregressive Prediction
Feb 16, 2026Medical image generation is pivotal in applications like data augmentation for low-resource clinical tasks and privacy-preserving data sharing. However, developing a scalable generative backbone for medical imaging requires architectural efficiency, sufficient multi-organ data, and principled evaluation, yet current approaches leave these aspects unresolved. Therefore, we introduce MedVAR, the first autoregressive-based foundation model that adopts the next-scale prediction paradigm to enable fast and scale-up-friendly medical image synthesis. MedVAR generates images in a coarse-to-fine manner and produces structured multi-scale representations suitable for downstream use. To support hierarchical generation, we curate a harmonized dataset of around 440,000 CT and MRI images spanning six anatomical regions. Comprehensive experiments across fidelity, diversity, and scalability show that MedVAR achieves state-of-the-art generative performance and offers a promising architectural direction for future medical generative foundation models.
DV-VLN: Dual Verification for Reliable LLM-Based Vision-and-Language Navigation
Jan 26, 2026Vision-and-Language Navigation (VLN) requires an embodied agent to navigate in a complex 3D environment according to natural language instructions. Recent progress in large language models (LLMs) has enabled language-driven navigation with improved interpretability. However, most LLM-based agents still rely on single-shot action decisions, where the model must choose one option from noisy, textualized multi-perspective observations. Due to local mismatches and imperfect intermediate reasoning, such decisions can easily deviate from the correct path, leading to error accumulation and reduced reliability in unseen environments. In this paper, we propose DV-VLN, a new VLN framework that follows a generate-then-verify paradigm. DV-VLN first performs parameter-efficient in-domain adaptation of an open-source LLaMA-2 backbone to produce a structured navigational chain-of-thought, and then verifies candidate actions with two complementary channels: True-False Verification (TFV) and Masked-Entity Verification (MEV). DV-VLN selects actions by aggregating verification successes across multiple samples, yielding interpretable scores for reranking. Experiments on R2R, RxR (English subset), and REVERIE show that DV-VLN consistently improves over direct prediction and sampling-only baselines, achieving competitive performance among language-only VLN agents and promising results compared with several cross-modal systems.Code is available at https://github.com/PlumJun/DV-VLN.
Automated Genomic Interpretation via Concept Bottleneck Models for Medical Robotics
Oct 02, 2025We propose an automated genomic interpretation module that transforms raw DNA sequences into actionable, interpretable decisions suitable for integration into medical automation and robotic systems. Our framework combines Chaos Game Representation (CGR) with a Concept Bottleneck Model (CBM), enforcing predictions to flow through biologically meaningful concepts such as GC content, CpG density, and k mer motifs. To enhance reliability, we incorporate concept fidelity supervision, prior consistency alignment, KL distribution matching, and uncertainty calibration. Beyond accurate classification of HIV subtypes across both in-house and LANL datasets, our module delivers interpretable evidence that can be directly validated against biological priors. A cost aware recommendation layer further translates predictive outputs into decision policies that balance accuracy, calibration, and clinical utility, reducing unnecessary retests and improving efficiency. Extensive experiments demonstrate that the proposed system achieves state of the art classification performance, superior concept prediction fidelity, and more favorable cost benefit trade-offs compared to existing baselines. By bridging the gap between interpretable genomic modeling and automated decision-making, this work establishes a reliable foundation for robotic and clinical automation in genomic medicine.
Adaptive Event Stream Slicing for Open-Vocabulary Event-Based Object Detection via Vision-Language Knowledge Distillation
Oct 01, 2025Event cameras offer advantages in object detection tasks due to high-speed response, low latency, and robustness to motion blur. However, event cameras lack texture and color information, making open-vocabulary detection particularly challenging. Current event-based detection methods are typically trained on predefined categories, limiting their ability to generalize to novel objects, where encountering previously unseen objects is common. Vision-language models (VLMs) have enabled open-vocabulary object detection in RGB images. However, the modality gap between images and event streams makes it ineffective to directly transfer CLIP to event data, as CLIP was not designed for event streams. To bridge this gap, we propose an event-image knowledge distillation framework that leverages CLIP's semantic understanding to achieve open-vocabulary object detection on event data. Instead of training CLIP directly on event streams, we use image frames as inputs to a teacher model, guiding the event-based student model to learn CLIP's rich visual representations. Through spatial attention-based distillation, the student network learns meaningful visual features directly from raw event inputs while inheriting CLIP's broad visual knowledge. Furthermore, to prevent information loss due to event data segmentation, we design a hybrid spiking neural network (SNN) and convolutional neural network (CNN) framework. Unlike fixed-group event segmentation methods, which often discard crucial temporal information, our SNN adaptively determines the optimal event segmentation moments, ensuring that key temporal features are extracted. The extracted event features are then processed by CNNs for object detection.
Sculpting Features from Noise: Reward-Guided Hierarchical Diffusion for Task-Optimal Feature Transformation
May 21, 2025



Feature Transformation (FT) crafts new features from original ones via mathematical operations to enhance dataset expressiveness for downstream models. However, existing FT methods exhibit critical limitations: discrete search struggles with enormous combinatorial spaces, impeding practical use; and continuous search, being highly sensitive to initialization and step sizes, often becomes trapped in local optima, restricting global exploration. To overcome these limitations, DIFFT redefines FT as a reward-guided generative task. It first learns a compact and expressive latent space for feature sets using a Variational Auto-Encoder (VAE). A Latent Diffusion Model (LDM) then navigates this space to generate high-quality feature embeddings, its trajectory guided by a performance evaluator towards task-specific optima. This synthesis of global distribution learning (from LDM) and targeted optimization (reward guidance) produces potent embeddings, which a novel semi-autoregressive decoder efficiently converts into structured, discrete features, preserving intra-feature dependencies while allowing parallel inter-feature generation. Extensive experiments on 14 benchmark datasets show DIFFT consistently outperforms state-of-the-art baselines in predictive accuracy and robustness, with significantly lower training and inference times.
TMCIR: Token Merge Benefits Composed Image Retrieval
Apr 15, 2025Composed Image Retrieval (CIR) retrieves target images using a multi-modal query that combines a reference image with text describing desired modifications. The primary challenge is effectively fusing this visual and textual information. Current cross-modal feature fusion approaches for CIR exhibit an inherent bias in intention interpretation. These methods tend to disproportionately emphasize either the reference image features (visual-dominant fusion) or the textual modification intent (text-dominant fusion through image-to-text conversion). Such an imbalanced representation often fails to accurately capture and reflect the actual search intent of the user in the retrieval results. To address this challenge, we propose TMCIR, a novel framework that advances composed image retrieval through two key innovations: 1) Intent-Aware Cross-Modal Alignment. We first fine-tune CLIP encoders contrastively using intent-reflecting pseudo-target images, synthesized from reference images and textual descriptions via a diffusion model. This step enhances the encoder ability of text to capture nuanced intents in textual descriptions. 2) Adaptive Token Fusion. We further fine-tune all encoders contrastively by comparing adaptive token-fusion features with the target image. This mechanism dynamically balances visual and textual representations within the contrastive learning pipeline, optimizing the composed feature for retrieval. Extensive experiments on Fashion-IQ and CIRR datasets demonstrate that TMCIR significantly outperforms state-of-the-art methods, particularly in capturing nuanced user intent.
Language-Depth Navigated Thermal and Visible Image Fusion
Mar 11, 2025Depth-guided multimodal fusion combines depth information from visible and infrared images, significantly enhancing the performance of 3D reconstruction and robotics applications. Existing thermal-visible image fusion mainly focuses on detection tasks, ignoring other critical information such as depth. By addressing the limitations of single modalities in low-light and complex environments, the depth information from fused images not only generates more accurate point cloud data, improving the completeness and precision of 3D reconstruction, but also provides comprehensive scene understanding for robot navigation, localization, and environmental perception. This supports precise recognition and efficient operations in applications such as autonomous driving and rescue missions. We introduce a text-guided and depth-driven infrared and visible image fusion network. The model consists of an image fusion branch for extracting multi-channel complementary information through a diffusion model, equipped with a text-guided module, and two auxiliary depth estimation branches. The fusion branch uses CLIP to extract semantic information and parameters from depth-enriched image descriptions to guide the diffusion model in extracting multi-channel features and generating fused images. These fused images are then input into the depth estimation branches to calculate depth-driven loss, optimizing the image fusion network. This framework aims to integrate vision-language and depth to directly generate color-fused images from multimodal inputs.
Multi-modal expressive personality recognition in data non-ideal audiovisual based on multi-scale feature enhancement and modal augment
Mar 08, 2025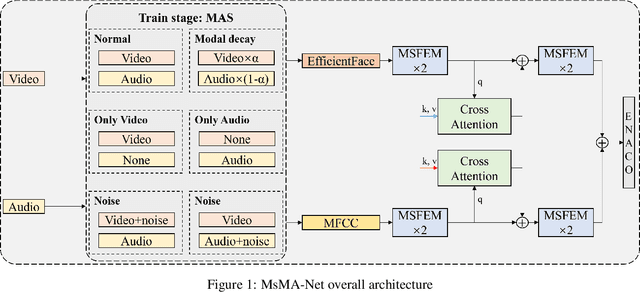

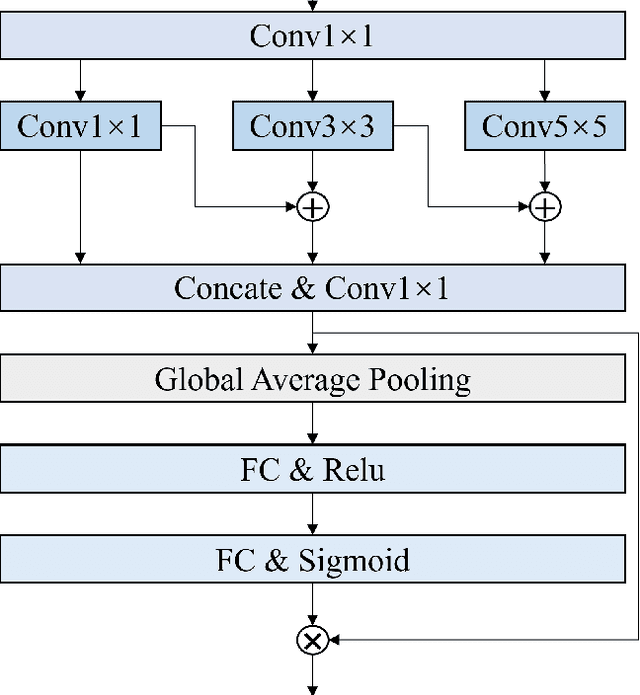

Automatic personality recognition is a research hotspot in the intersection of computer science and psychology, and in human-computer interaction, personalised has a wide range of applications services and other scenarios. In this paper, an end-to-end multimodal performance personality is established for both visual and auditory modal datarecognition network , and the through feature-level fusion , which effectively of the two modalities is carried out the cross-attention mechanismfuses the features of the two modal data; and a is proposed multiscale feature enhancement modalitiesmodule , which enhances for visual and auditory boththe expression of the information of effective the features and suppresses the interference of the redundant information. In addition, during the training process, this paper proposes a modal enhancement training strategy to simulate non-ideal such as modal loss and noise interferencedata situations , which enhances the adaptability ofand the model to non-ideal data scenarios improves the robustness of the model. Experimental results show that the method proposed in this paper is able to achieve an average Big Five personality accuracy of , which outperforms existing 0.916 on the personality analysis dataset ChaLearn First Impressionother methods based on audiovisual and audio-visual both modalities. The ablation experiments also validate our proposed , respectivelythe contribution of module and modality enhancement strategy to the model performance. Finally, we simulate in the inference phase multi-scale feature enhancement six non-ideal data scenarios to verify the modal enhancement strategy's improvement in model robustness.
ConDo: Continual Domain Expansion for Absolute Pose Regression
Dec 18, 2024



Visual localization is a fundamental machine learning problem. Absolute Pose Regression (APR) trains a scene-dependent model to efficiently map an input image to the camera pose in a pre-defined scene. However, many applications have continually changing environments, where inference data at novel poses or scene conditions (weather, geometry) appear after deployment. Training APR on a fixed dataset leads to overfitting, making it fail catastrophically on challenging novel data. This work proposes Continual Domain Expansion (ConDo), which continually collects unlabeled inference data to update the deployed APR. Instead of applying standard unsupervised domain adaptation methods which are ineffective for APR, ConDo effectively learns from unlabeled data by distilling knowledge from scene-agnostic localization methods. By sampling data uniformly from historical and newly collected data, ConDo can effectively expand the generalization domain of APR. Large-scale benchmarks with various scene types are constructed to evaluate models under practical (long-term) data changes. ConDo consistently and significantly outperforms baselines across architectures, scene types, and data changes. On challenging scenes (Fig.1), it reduces the localization error by >7x (14.8m vs 1.7m). Analysis shows the robustness of ConDo against compute budgets, replay buffer sizes and teacher prediction noise. Comparing to model re-training, ConDo achieves similar performance up to 25x faster.