 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-View Consistency Framework with Semi-Supervised Domain Adaptation
Jan 27, 2026Semi-Supervised Domain Adaptation (SSDA) leverages knowledge from a fully labeled source domain to classify data in a partially labeled target domain. Due to the limited number of labeled samples in the target domain, there can be intrinsic similarity of classes in the feature space, which may result in biased predictions, even when the model is trained on a balanced dataset. To overcome this limitation, we introduce a multi-view consistency framework, which includes two views for training strongly augmented data. One is a debiasing strategy for correcting class-wise prediction probabilities according to the prediction performance of the model. The other involves leveraging pseudo-negative labels derived from the model predictions. Furthermore, we introduce a cross-domain affinity learning aimed at aligning features of the same class across different domains, thereby enhancing overall performance. Experimental results demonstrate that our method outperforms the competing methods on two standard domain adaptation datasets, DomainNet and Office-Home. Combining unsupervised domain adaptation and semi-supervised learning offers indispensable contributions to the industrial sector by enhancing model adaptability, reducing annotation costs, and improving performance.
Multi-modal expressive personality recognition in data non-ideal audiovisual based on multi-scale feature enhancement and modal augment
Mar 08, 2025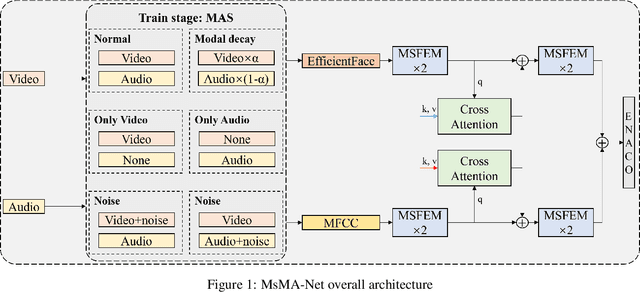

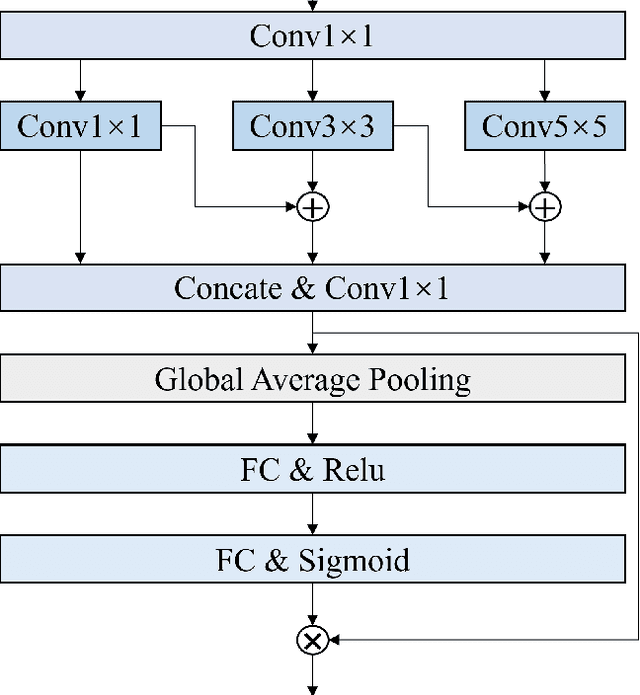

Automatic personality recognition is a research hotspot in the intersection of computer science and psychology, and in human-computer interaction, personalised has a wide range of applications services and other scenarios. In this paper, an end-to-end multimodal performance personality is established for both visual and auditory modal datarecognition network , and the through feature-level fusion , which effectively of the two modalities is carried out the cross-attention mechanismfuses the features of the two modal data; and a is proposed multiscale feature enhancement modalitiesmodule , which enhances for visual and auditory boththe expression of the information of effective the features and suppresses the interference of the redundant information. In addition, during the training process, this paper proposes a modal enhancement training strategy to simulate non-ideal such as modal loss and noise interferencedata situations , which enhances the adaptability ofand the model to non-ideal data scenarios improves the robustness of the model. Experimental results show that the method proposed in this paper is able to achieve an average Big Five personality accuracy of , which outperforms existing 0.916 on the personality analysis dataset ChaLearn First Impressionother methods based on audiovisual and audio-visual both modalities. The ablation experiments also validate our proposed , respectivelythe contribution of module and modality enhancement strategy to the model performance. Finally, we simulate in the inference phase multi-scale feature enhancement six non-ideal data scenarios to verify the modal enhancement strategy's improvement in model robustness.
Prior-based Objective Inference Mining Potential Uncertainty for Facial Expression Recognition
Nov 20, 2024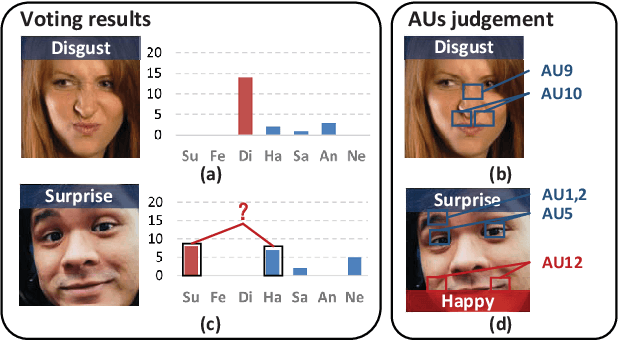
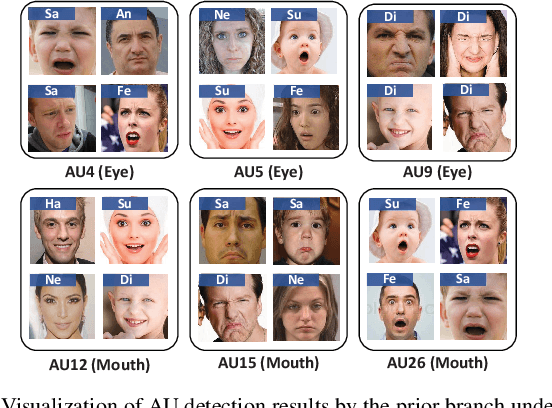
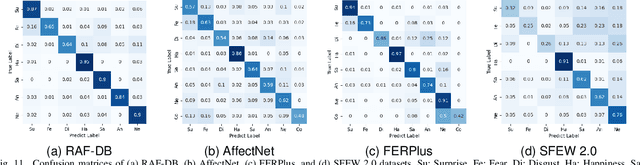
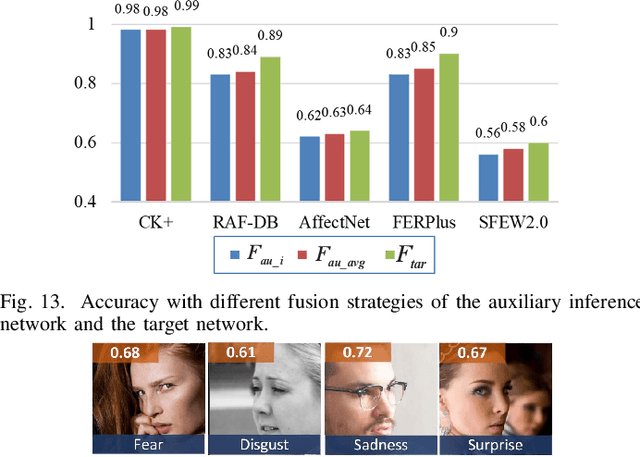
Annotation ambiguity caused by the inherent subjectivity of visual judgment has always been a major challenge for Facial Expression Recognition (FER) tasks, particularly for largescale datasets from in-the-wild scenarios. A potential solution is the evaluation of relatively objective emotional distributions to help mitigate the ambiguity of subjective annotations. To this end, this paper proposes a novel Prior-based Objective Inference (POI) network. This network employs prior knowledge to derive a more objective and varied emotional distribution and tackles the issue of subjective annotation ambiguity through dynamic knowledge transfer. POI comprises two key networks: Firstly, the Prior Inference Network (PIN) utilizes the prior knowledge of AUs and emotions to capture intricate motion details. To reduce over-reliance on priors and facilitate objective emotional inference, PIN aggregates inferential knowledge from various key facial subregions, encouraging mutual learning. Secondly, the Target Recognition Network (TRN) integrates subjective emotion annotations and objective inference soft labels provided by the PIN, fostering an understanding of inherent facial expression diversity, thus resolving annotation ambiguity. Moreover, we introduce an uncertainty estimation module to quantify and balance facial expression confidence. This module enables a flexible approach to dealing with the uncertainties of subjective annotations. Extensive experiments show that POI exhibits competitive performance on both synthetic noisy datasets and multiple real-world datasets. All codes and training logs will be publicly available at https://github.com/liuhw01/POI.
Multi-Level Label Correction by Distilling Proximate Patterns for Semi-supervised Semantic Segmentation
Apr 10, 2024Semi-supervised semantic segmentation relieves the reliance on large-scale labeled data by leveraging unlabeled data. Recent semi-supervised semantic segmentation approaches mainly resort to pseudo-labeling methods to exploit unlabeled data. However, unreliable pseudo-labeling can undermine the semi-supervision processes. In this paper, we propose an algorithm called Multi-Level Label Correction (MLLC), which aims to use graph neural networks to capture structural relationships in Semantic-Level Graphs (SLGs) and Class-Level Graphs (CLGs) to rectify erroneous pseudo-labels. Specifically, SLGs represent semantic affinities between pairs of pixel features, and CLGs describe classification consistencies between pairs of pixel labels. With the support of proximate pattern information from graphs, MLLC can rectify incorrectly predicted pseudo-labels and can facilitate discriminative feature representations. We design an end-to-end network to train and perform this effective label corrections mechanism. Experiments demonstrate that MLLC can significantly improve supervised baselines and outperforms state-of-the-art approaches in different scenarios on Cityscapes and PASCAL VOC 2012 datasets. Specifically, MLLC improves the supervised baseline by at least 5% and 2% with DeepLabV2 and DeepLabV3+ respectively under different partition protocols.
Semi-Supervised Learning with Pseudo-Negative Labels for Image Classification
Jan 10, 2023
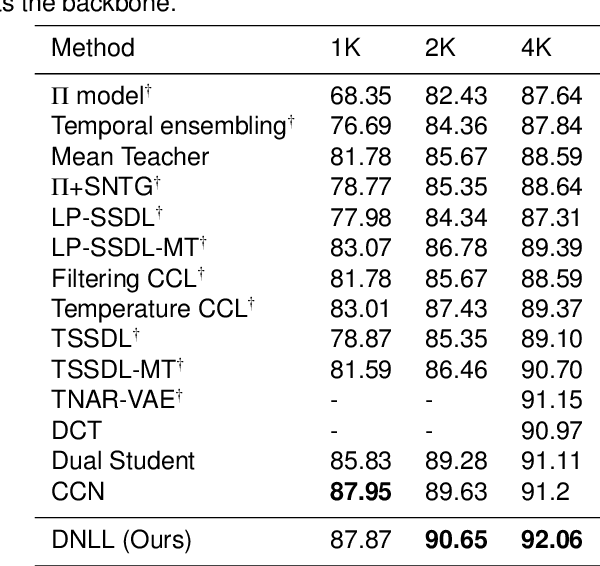
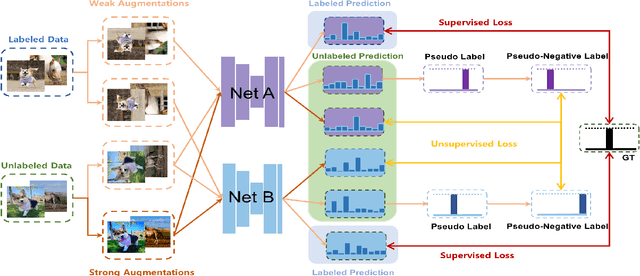
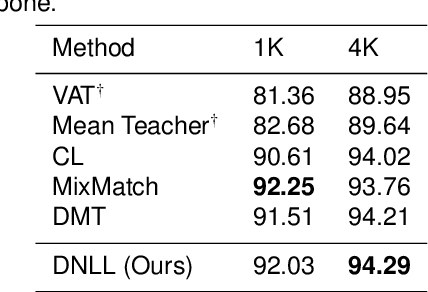
Semi-supervised learning frameworks usually adopt mutual learning approaches with multiple submodels to learn from different perspectives. To avoid transferring erroneous pseudo labels between these submodels, a high threshold is usually used to filter out a large number of low-confidence predictions for unlabeled data. However, such filtering can not fully exploit unlabeled data with low prediction confidence. To overcome this problem, in this work, we propose a mutual learning framework based on pseudo-negative labels. Negative labels are those that a corresponding data item does not belong. In each iteration, one submodel generates pseudo-negative labels for each data item, and the other submodel learns from these labels. The role of the two submodels exchanges after each iteration until convergence. By reducing the prediction probability on pseudo-negative labels, the dual model can improve its prediction ability. We also propose a mechanism to select a few pseudo-negative labels to feed into submodels. In the experiments, our framework achieves state-of-the-art results on several main benchmarks. Specifically, with our framework, the error rates of the 13-layer CNN model are 9.35% and 7.94% for CIFAR-10 with 1000 and 4000 labels, respectively. In addition, for the non-augmented MNIST with only 20 labels, the error rate is 0.81% by our framework, which is much smaller than that of other approaches. Our approach also demonstrates a significant performance improvement in domain adaptation.
Semi-Supervised Semantic Segmentation with Cross Teacher Training
Sep 03, 2022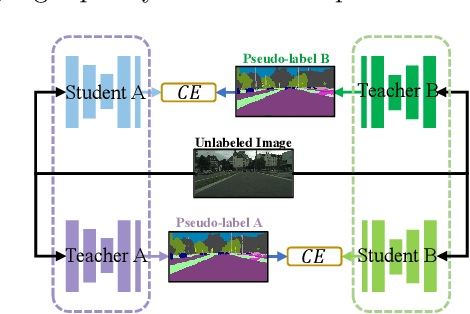
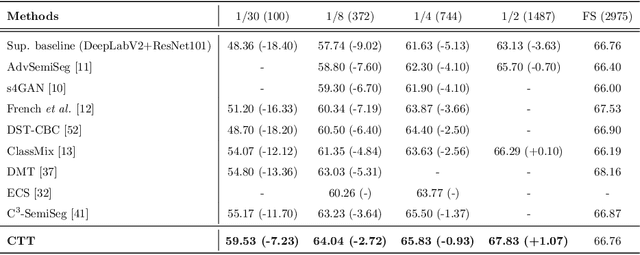
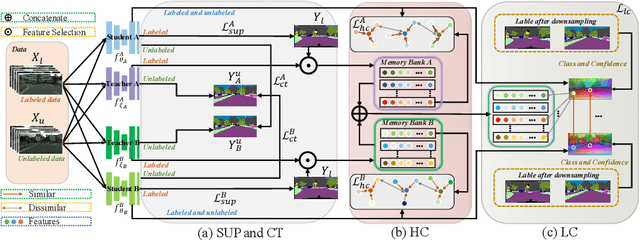
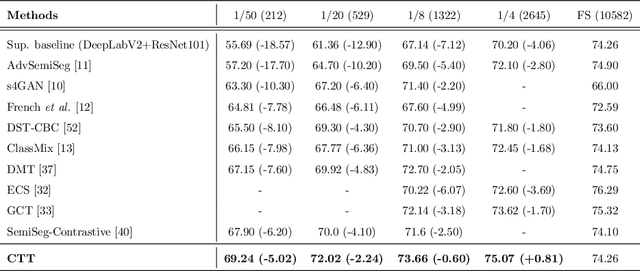
Convolutional neural networks can achieve remarkable performance in semantic segmentation tasks. However, such neural network approaches heavily rely on costly pixel-level annotation. Semi-supervised learning is a promising resolution to tackle this issue, but its performance still far falls behind the fully supervised counterpart. This work proposes a cross-teacher training framework with three modules that significantly improves traditional semi-supervised learning approaches. The core is a cross-teacher module, which could simultaneously reduce the coupling among peer networks and the error accumulation between teacher and student networks. In addition, we propose two complementary contrastive learning modules. The high-level module can transfer high-quality knowledge from labeled data to unlabeled ones and promote separation between classes in feature space. The low-level module can encourage low-quality features learning from the high-quality features among peer networks. In experiments, the cross-teacher module significantly improves the performance of traditional student-teacher approaches, and our framework outperforms stateof-the-art methods on benchmark datasets. Our source code of CTT will be released.
* 31 papges, 8 figures, 9 tables