 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Level Label Correction by Distilling Proximate Patterns for Semi-supervised Semantic Segmentation
Apr 10, 2024Semi-supervised semantic segmentation relieves the reliance on large-scale labeled data by leveraging unlabeled data. Recent semi-supervised semantic segmentation approaches mainly resort to pseudo-labeling methods to exploit unlabeled data. However, unreliable pseudo-labeling can undermine the semi-supervision processes. In this paper, we propose an algorithm called Multi-Level Label Correction (MLLC), which aims to use graph neural networks to capture structural relationships in Semantic-Level Graphs (SLGs) and Class-Level Graphs (CLGs) to rectify erroneous pseudo-labels. Specifically, SLGs represent semantic affinities between pairs of pixel features, and CLGs describe classification consistencies between pairs of pixel labels. With the support of proximate pattern information from graphs, MLLC can rectify incorrectly predicted pseudo-labels and can facilitate discriminative feature representations. We design an end-to-end network to train and perform this effective label corrections mechanism. Experiments demonstrate that MLLC can significantly improve supervised baselines and outperforms state-of-the-art approaches in different scenarios on Cityscapes and PASCAL VOC 2012 datasets. Specifically, MLLC improves the supervised baseline by at least 5% and 2% with DeepLabV2 and DeepLabV3+ respectively under different partition protocols.
Facial Data Minimization: Shallow Model as Your Privacy Filter
Oct 24, 2023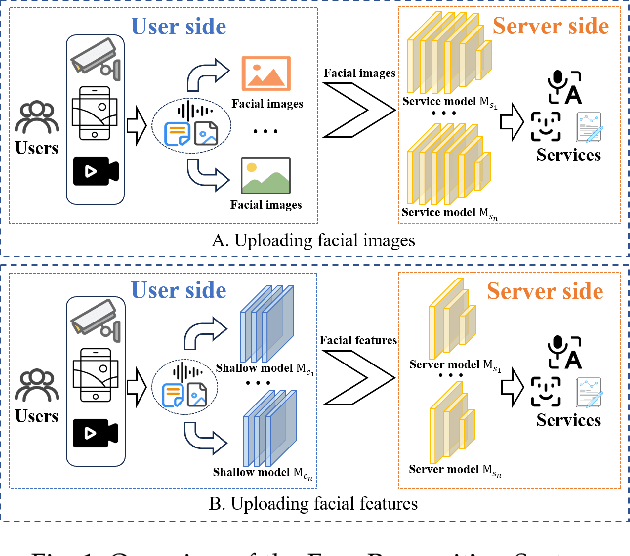
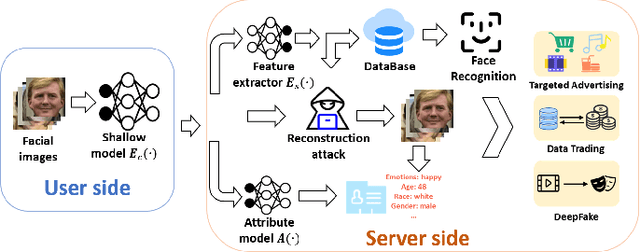

Face recognition service has been used in many fields and brings much convenience to people. However, once the user's facial data is transmitted to a service provider, the user will lose control of his/her private data. In recent years, there exist various security and privacy issues due to the leakage of facial data. Although many privacy-preserving methods have been proposed, they usually fail when they are not accessible to adversaries' strategies or auxiliary data. Hence, in this paper, by fully considering two cases of uploading facial images and facial features, which are very typical in face recognition service systems, we proposed a data privacy minimization transformation (PMT) method. This method can process the original facial data based on the shallow model of authorized services to obtain the obfuscated data. The obfuscated data can not only maintain satisfactory performance on authorized models and restrict the performance on other unauthorized models but also prevent original privacy data from leaking by AI methods and human visual theft. Additionally, since a service provider may execute preprocessing operations on the received data, we also propose an enhanced perturbation method to improve the robustness of PMT. Besides, to authorize one facial image to multiple service models simultaneously, a multiple restriction mechanism is proposed to improve the scalability of PMT. Finally, we conduct extensive experiments and evaluate the effectiveness of the proposed PMT in defending against face reconstruction, data abuse, and face attribute estimation attacks. These experimental results demonstrate that PMT performs well in preventing facial data abuse and privacy leakage while maintaining face recognition accuracy.
BadSQA: Stealthy Backdoor Attacks Using Presence Events as Triggers in Non-Intrusive Speech Quality Assessment
Sep 04, 2023



Non-Intrusive speech quality assessment (NISQA) has gained significant attention for predicting the mean opinion score (MOS) of speech without requiring the reference speech. In practical NISQA scenarios, untrusted third-party resources are often employed during deep neural network training to reduce costs. However, it would introduce a potential security vulnerability as specially designed untrusted resources can launch backdoor attacks against NISQA systems. Existing backdoor attacks primarily focus on classification tasks and are not directly applicable to NISQA which is a regression task. In this paper, we propose a novel backdoor attack on NISQA tasks, leveraging presence events as triggers to achieving highly stealthy attacks. To evaluate the effectiveness of our proposed approach, we conducted experiments on four benchmark datasets and employed two state-of-the-art NISQA models. The results demonstrate that the proposed backdoor attack achieved an average attack success rate of up to 99% with a poisoning rate of only 3%.
Evil Operation: Breaking Speaker Recognition with PaddingBack
Aug 08, 2023



Machine Learning as a Service (MLaaS) has gained popularity due to advancements in machine learning. However, untrusted third-party platforms have raised concerns about AI security, particularly in backdoor attacks. Recent research has shown that speech backdoors can utilize transformations as triggers, similar to image backdoors. However, human ears easily detect these transformations, leading to suspicion. In this paper, we introduce PaddingBack, an inaudible backdoor attack that utilizes malicious operations to make poisoned samples indistinguishable from clean ones. Instead of using external perturbations as triggers, we exploit the widely used speech signal operation, padding, to break speaker recognition systems. Our experimental results demonstrate the effectiveness of the proposed approach, achieving a significantly high attack success rate while maintaining a high rate of benign accuracy. Furthermore, PaddingBack demonstrates the ability to resist defense methods while maintaining its stealthiness against human perception. The results of the stealthiness experiment have been made available at https://nbufabio25.github.io/paddingback/.
Universal Defensive Underpainting Patch: Making Your Text Invisible to Optical Character Recognition
Aug 04, 2023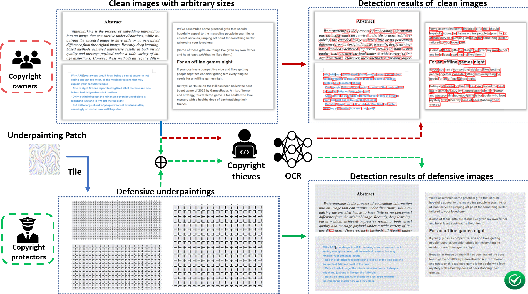

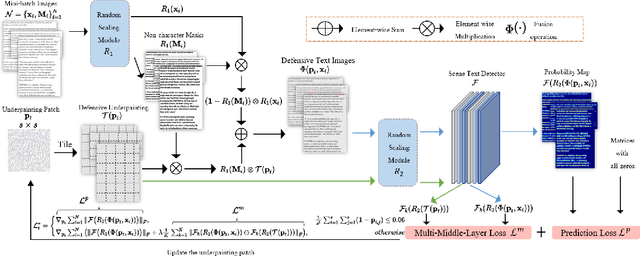
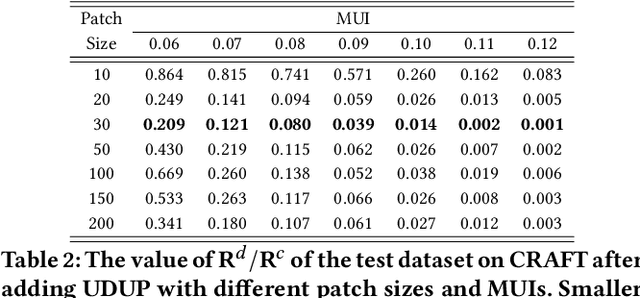
Optical Character Recognition (OCR) enables automatic text extraction from scanned or digitized text images, but it also makes it easy to pirate valuable or sensitive text from these images. Previous methods to prevent OCR piracy by distorting characters in text images are impractical in real-world scenarios, as pirates can capture arbitrary portions of the text images, rendering the defenses ineffective. In this work, we propose a novel and effective defense mechanism termed the Universal Defensive Underpainting Patch (UDUP) that modifies the underpainting of text images instead of the characters. UDUP is created through an iterative optimization process to craft a small, fixed-size defensive patch that can generate non-overlapping underpainting for text images of any size. Experimental results show that UDUP effectively defends against unauthorized OCR under the setting of any screenshot range or complex image background. It is agnostic to the content, size, colors, and languages of characters, and is robust to typical image operations such as scaling and compressing. In addition, the transferability of UDUP is demonstrated by evading several off-the-shelf OCRs. The code is available at https://github.com/QRICKDD/UDUP.
Fake the Real: Backdoor Attack on Deep Speech Classification via Voice Conversion
Jun 28, 2023Deep speech classification has achieved tremendous success and greatly promoted the emergence of many real-world applications. However, backdoor attacks present a new security threat to it, particularly with untrustworthy third-party platforms, as pre-defined triggers set by the attacker can activate the backdoor. Most of the triggers in existing speech backdoor attacks are sample-agnostic, and even if the triggers are designed to be unnoticeable, they can still be audible. This work explores a backdoor attack that utilizes sample-specific triggers based on voice conversion. Specifically, we adopt a pre-trained voice conversion model to generate the trigger, ensuring that the poisoned samples does not introduce any additional audible noise. Extensive experiments on two speech classification tasks demonstrate the effectiveness of our attack. Furthermore, we analyzed the specific scenarios that activated the proposed backdoor and verified its resistance against fine-tuning.
Semi-Supervised Semantic Segmentation with Cross Teacher Training
Sep 03, 2022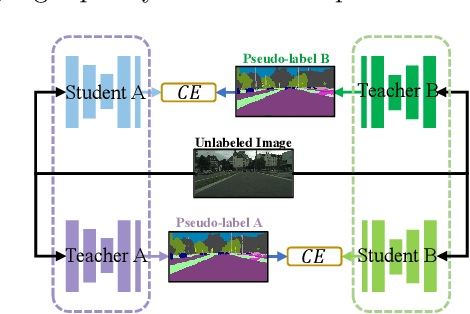
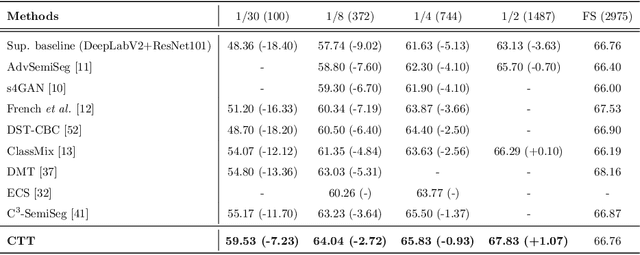
Convolutional neural networks can achieve remarkable performance in semantic segmentation tasks. However, such neural network approaches heavily rely on costly pixel-level annotation. Semi-supervised learning is a promising resolution to tackle this issue, but its performance still far falls behind the fully supervised counterpart. This work proposes a cross-teacher training framework with three modules that significantly improves traditional semi-supervised learning approaches. The core is a cross-teacher module, which could simultaneously reduce the coupling among peer networks and the error accumulation between teacher and student networks. In addition, we propose two complementary contrastive learning modules. The high-level module can transfer high-quality knowledge from labeled data to unlabeled ones and promote separation between classes in feature space. The low-level module can encourage low-quality features learning from the high-quality features among peer networks. In experiments, the cross-teacher module significantly improves the performance of traditional student-teacher approaches, and our framework outperforms stateof-the-art methods on benchmark datasets. Our source code of CTT will be released.
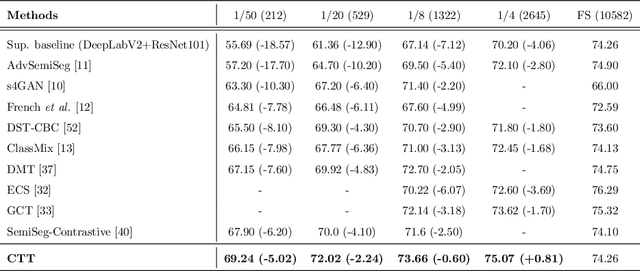
* 31 papges, 8 figures, 9 tables
Detecting and Recovering Adversarial Examples from Extracting Non-robust and Highly Predictive Adversarial Perturbations
Jun 30, 2022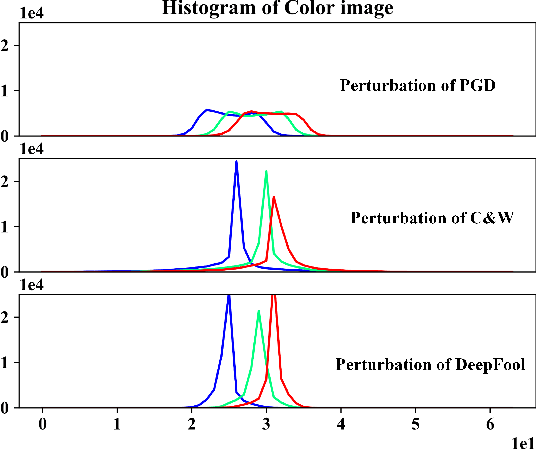
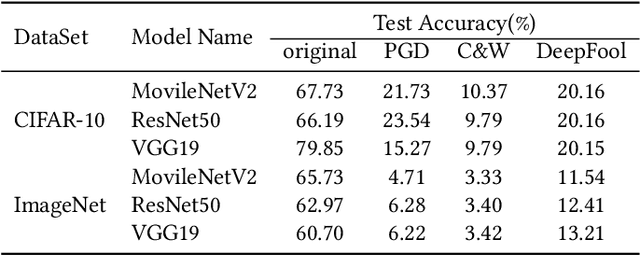
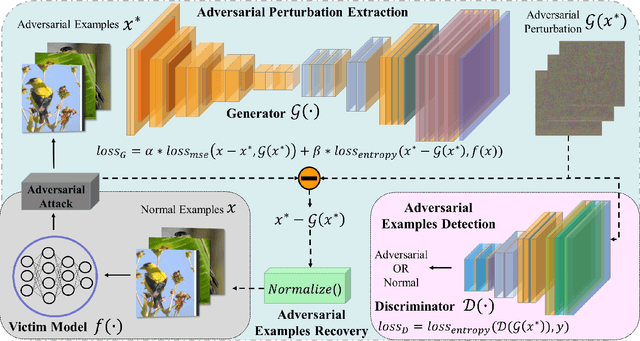
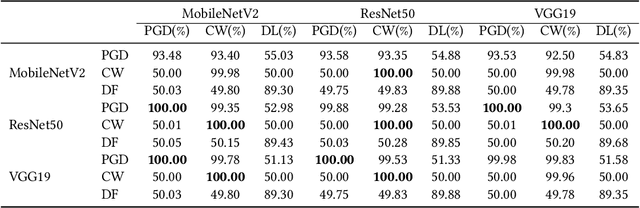
Deep neural networks (DNNs) have been shown to be vulnerable against adversarial examples (AEs) which are maliciously designed to fool target models. The normal examples (NEs) added with imperceptible adversarial perturbation, can be a security threat to DNNs. Although the existing AEs detection methods have achieved a high accuracy, they failed to exploit the information of the AEs detected. Thus, based on high-dimension perturbation extraction, we propose a model-free AEs detection method, the whole process of which is free from querying the victim model. Research shows that DNNs are sensitive to the high-dimension features. The adversarial perturbation hiding in the adversarial example belongs to the high-dimension feature which is highly predictive and non-robust. DNNs learn more details from high-dimension data than others. In our method, the perturbation extractor can extract the adversarial perturbation from AEs as high-dimension feature, then the trained AEs discriminator determines whether the input is an AE. Experimental results show that the proposed method can not only detect the adversarial examples with high accuracy, but also detect the specific category of the AEs. Meanwhile, the extracted perturbation can be used to recover the AEs to NEs.
Adversarial Privacy Protection on Speech Enhancement
Jun 16, 2022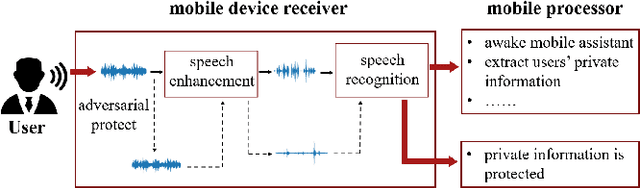

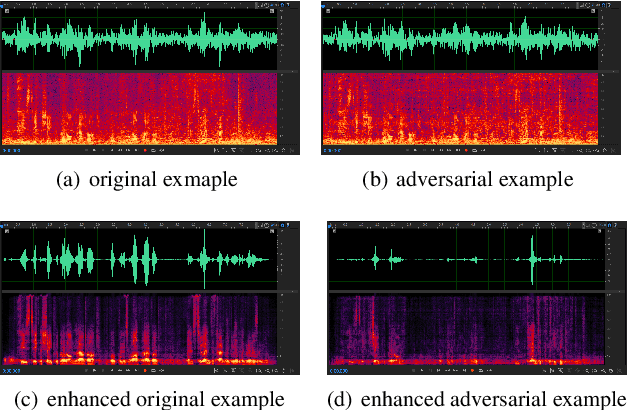

Speech is easily leaked imperceptibly, such as being recorded by mobile phones in different situations. Private content in speech may be maliciously extracted through speech enhancement technology. Speech enhancement technology has developed rapidly along with deep neural networks (DNNs), but adversarial examples can cause DNNs to fail. In this work, we propose an adversarial method to degrade speech enhancement systems. Experimental results show that generated adversarial examples can erase most content information in original examples or replace it with target speech content through speech enhancement. The word error rate (WER) between an enhanced original example and enhanced adversarial example recognition result can reach 89.0%. WER of target attack between enhanced adversarial example and target example is low to 33.75% . Adversarial perturbation can bring the rate of change to the original example to more than 1.4430. This work can prevent the malicious extraction of speech.
Transferability of Adversarial Attacks on Synthetic Speech Detection
May 16, 2022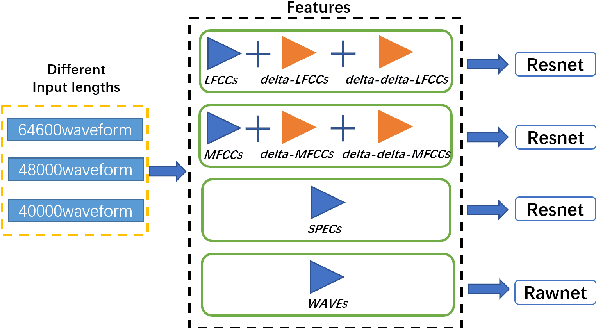
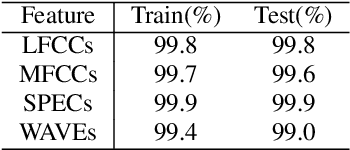
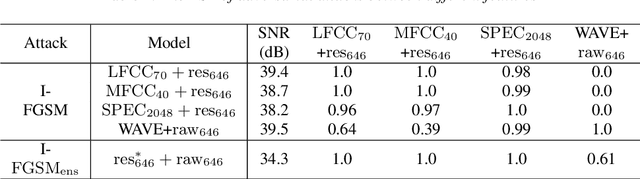
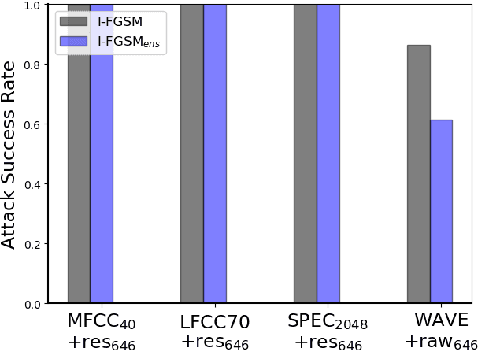
Synthetic speech detection is one of the most important research problems in audio security. Meanwhile, deep neural networks are vulnerable to adversarial attacks. Therefore, we establish a comprehensive benchmark to evaluate the transferability of adversarial attacks on the synthetic speech detection task. Specifically, we attempt to investigate: 1) The transferability of adversarial attacks between different features. 2) The influence of varying extraction hyperparameters of features on the transferability of adversarial attacks. 3) The effect of clipping or self-padding operation on the transferability of adversarial attacks. By performing these analyses, we summarise the weaknesses of synthetic speech detectors and the transferability behaviours of adversarial attacks, which provide insights for future research. More details can be found at https://gitee.com/djc_QRICK/Attack-Transferability-On-Synthetic-Detection.