 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting and Recovering Adversarial Examples from Extracting Non-robust and Highly Predictive Adversarial Perturbations
Jun 30, 2022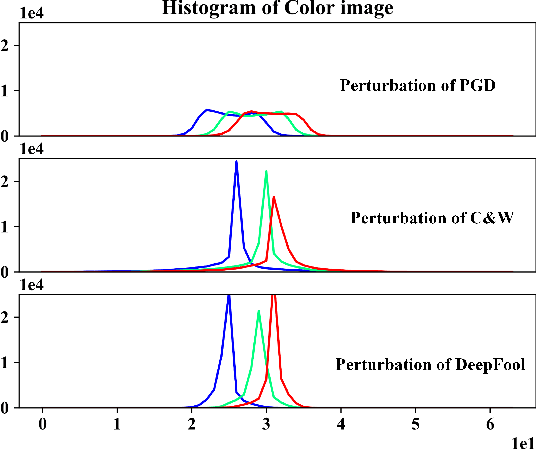
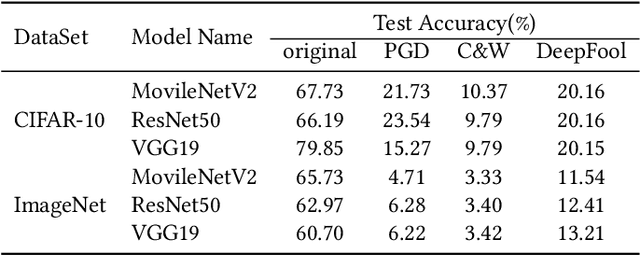
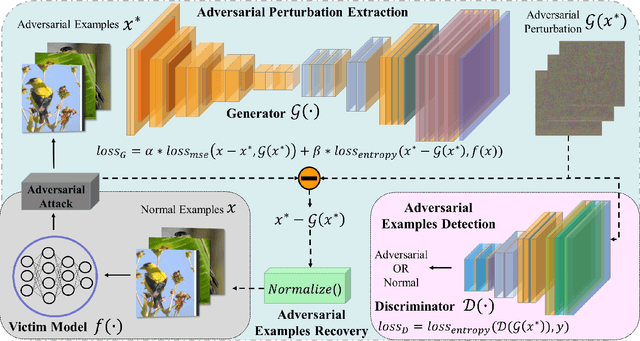
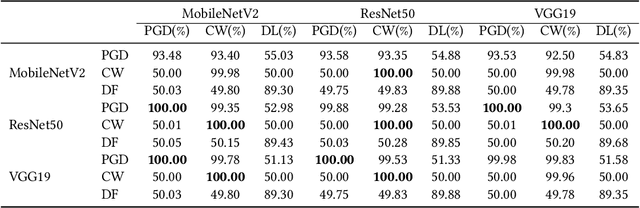
Deep neural networks (DNNs) have been shown to be vulnerable against adversarial examples (AEs) which are maliciously designed to fool target models. The normal examples (NEs) added with imperceptible adversarial perturbation, can be a security threat to DNNs. Although the existing AEs detection methods have achieved a high accuracy, they failed to exploit the information of the AEs detected. Thus, based on high-dimension perturbation extraction, we propose a model-free AEs detection method, the whole process of which is free from querying the victim model. Research shows that DNNs are sensitive to the high-dimension features. The adversarial perturbation hiding in the adversarial example belongs to the high-dimension feature which is highly predictive and non-robust. DNNs learn more details from high-dimension data than others. In our method, the perturbation extractor can extract the adversarial perturbation from AEs as high-dimension feature, then the trained AEs discriminator determines whether the input is an AE. Experimental results show that the proposed method can not only detect the adversarial examples with high accuracy, but also detect the specific category of the AEs. Meanwhile, the extracted perturbation can be used to recover the AEs to NEs.