 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReplicateAnyScene: Zero-Shot Video-to-3D Composition via Textual-Visual-Spatial Alignment
Apr 12, 2026Humans exhibit an innate capacity to rapidly perceive and segment objects from video observations, and even mentally assemble them into structured 3D scenes. Replicating such capability, termed compositional 3D reconstruction, is pivotal for the advancement of Spatial Intelligence and Embodied AI. However, existing methods struggle to achieve practical deployment due to the insufficient integration of cross-modal information, leaving them dependent on manual object prompting, reliant on auxiliary visual inputs, and restricted to overly simplistic scenes by training biases. To address these limitations, we propose ReplicateAnyScene, a framework capable of fully automated and zero-shot transformation of casually captured videos into compositional 3D scenes. Specifically, our pipeline incorporates a five-stage cascade to extract and structurally align generic priors from vision foundation models across textual, visual, and spatial dimensions, grounding them into structured 3D representations and ensuring semantic coherence and physical plausibility of the constructed scenes. To facilitate a more comprehensive evaluation of this task, we further introduce the C3DR benchmark to assess reconstruction quality from diverse aspects. Extensive experiments demonstrate the superiority of our method over existing baselines in generating high-quality compositional 3D scenes.
Revisiting 3D Reconstruction Kernels as Low-Pass Filters
Jan 25, 20263D reconstruction is to recover 3D signals from the sampled discrete 2D pixels, with the goal to converge continuous 3D spaces. In this paper, we revisit 3D reconstruction from the perspective of signal processing, identifying the periodic spectral extension induced by discrete sampling as the fundamental challenge. Previous 3D reconstruction kernels, such as Gaussians, Exponential functions, and Student's t distributions, serve as the low pass filters to isolate the baseband spectrum. However, their unideal low-pass property results in the overlap of high-frequency components with low-frequency components in the discrete-time signal's spectrum. To this end, we introduce Jinc kernel with an instantaneous drop to zero magnitude exactly at the cutoff frequency, which is corresponding to the ideal low pass filters. As Jinc kernel suffers from low decay speed in the spatial domain, we further propose modulated kernels to strick an effective balance, and achieves superior rendering performance by reconciling spatial efficiency and frequency-domain fidelity. Experimental results have demonstrated the effectiveness of our Jinc and modulated kernels.
Detecting and Recovering Adversarial Examples from Extracting Non-robust and Highly Predictive Adversarial Perturbations
Jun 30, 2022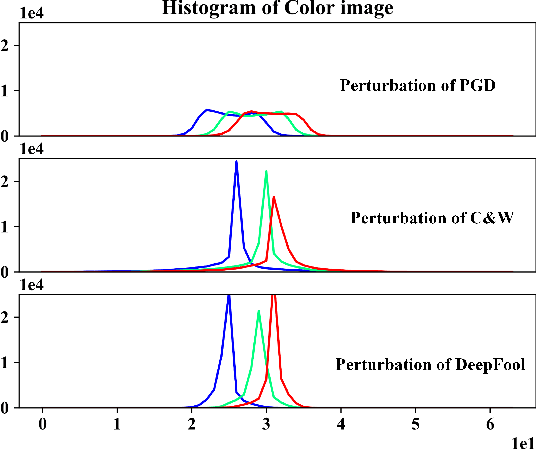
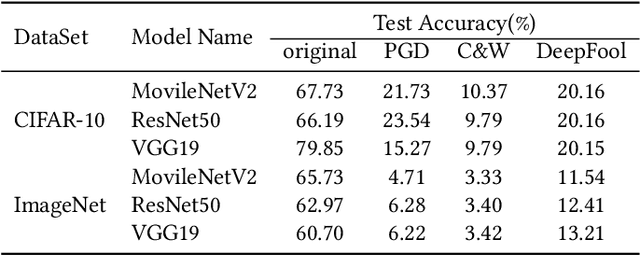
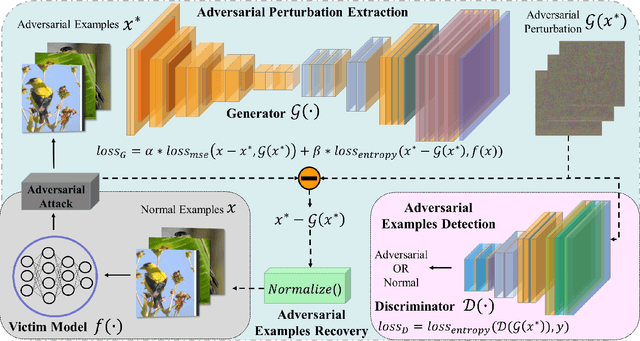
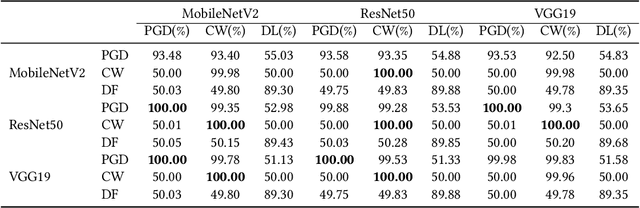
Deep neural networks (DNNs) have been shown to be vulnerable against adversarial examples (AEs) which are maliciously designed to fool target models. The normal examples (NEs) added with imperceptible adversarial perturbation, can be a security threat to DNNs. Although the existing AEs detection methods have achieved a high accuracy, they failed to exploit the information of the AEs detected. Thus, based on high-dimension perturbation extraction, we propose a model-free AEs detection method, the whole process of which is free from querying the victim model. Research shows that DNNs are sensitive to the high-dimension features. The adversarial perturbation hiding in the adversarial example belongs to the high-dimension feature which is highly predictive and non-robust. DNNs learn more details from high-dimension data than others. In our method, the perturbation extractor can extract the adversarial perturbation from AEs as high-dimension feature, then the trained AEs discriminator determines whether the input is an AE. Experimental results show that the proposed method can not only detect the adversarial examples with high accuracy, but also detect the specific category of the AEs. Meanwhile, the extracted perturbation can be used to recover the AEs to NEs.
Adversarial Privacy Protection on Speech Enhancement
Jun 16, 2022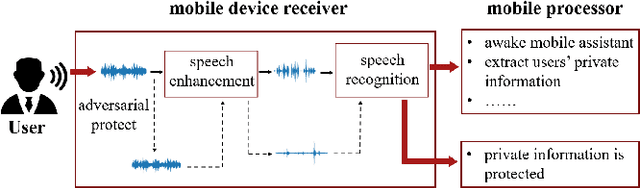

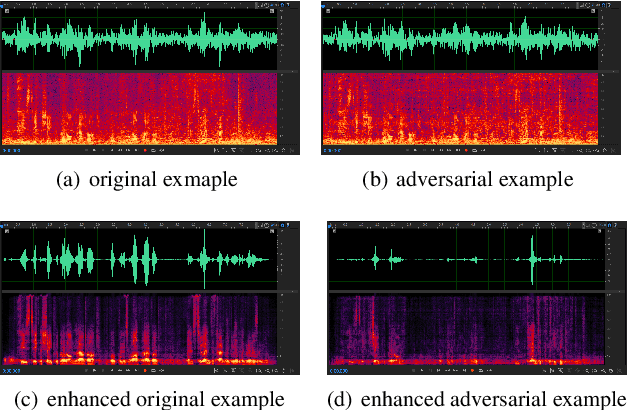

Speech is easily leaked imperceptibly, such as being recorded by mobile phones in different situations. Private content in speech may be maliciously extracted through speech enhancement technology. Speech enhancement technology has developed rapidly along with deep neural networks (DNNs), but adversarial examples can cause DNNs to fail. In this work, we propose an adversarial method to degrade speech enhancement systems. Experimental results show that generated adversarial examples can erase most content information in original examples or replace it with target speech content through speech enhancement. The word error rate (WER) between an enhanced original example and enhanced adversarial example recognition result can reach 89.0%. WER of target attack between enhanced adversarial example and target example is low to 33.75% . Adversarial perturbation can bring the rate of change to the original example to more than 1.4430. This work can prevent the malicious extraction of speech.
Adversarial Example Devastation and Detection on Speech Recognition System by Adding Random Noise
Sep 09, 2021

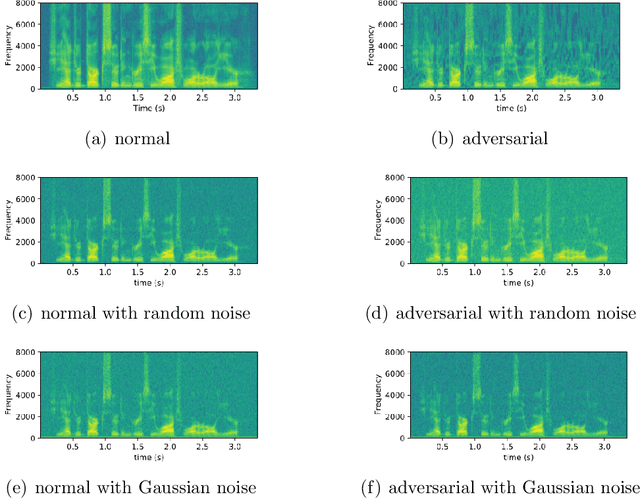

The automatic speech recognition (ASR) system based on deep neural network is easy to be attacked by an adversarial example due to the vulnerability of neural network, which is a hot topic in recent years. The adversarial example does harm to the ASR system, especially if the common-dependent ASR goes wrong, it will lead to serious consequences. To improve the robustness and security of the ASR system, the defense method against adversarial examples must be proposed. Based on this idea, we propose an algorithm of devastation and detection on adversarial examples which can attack the current advanced ASR system. We choose advanced text-dependent and command-dependent ASR system as our target system. Generating adversarial examples by the OPT on text-dependent ASR and the GA-based algorithm on command-dependent ASR. The main idea of our method is input transformation of the adversarial examples. Different random intensities and kinds of noise are added to the adversarial examples to devastate the perturbation previously added to the normal examples. From the experimental results, the method performs well. For the devastation of examples, the original speech similarity before and after adding noise can reach 99.68%, the similarity of the adversarial examples can reach 0%, and the detection rate of the adversarial examples can reach 94%.