 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Defensive Underpainting Patch: Making Your Text Invisible to Optical Character Recognition
Aug 04, 2023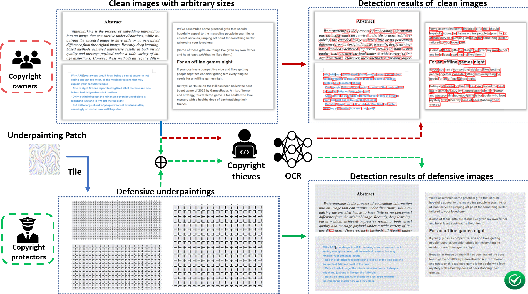

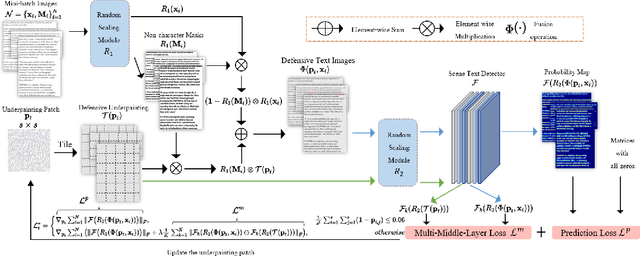
Optical Character Recognition (OCR) enables automatic text extraction from scanned or digitized text images, but it also makes it easy to pirate valuable or sensitive text from these images. Previous methods to prevent OCR piracy by distorting characters in text images are impractical in real-world scenarios, as pirates can capture arbitrary portions of the text images, rendering the defenses ineffective. In this work, we propose a novel and effective defense mechanism termed the Universal Defensive Underpainting Patch (UDUP) that modifies the underpainting of text images instead of the characters. UDUP is created through an iterative optimization process to craft a small, fixed-size defensive patch that can generate non-overlapping underpainting for text images of any size. Experimental results show that UDUP effectively defends against unauthorized OCR under the setting of any screenshot range or complex image background. It is agnostic to the content, size, colors, and languages of characters, and is robust to typical image operations such as scaling and compressing. In addition, the transferability of UDUP is demonstrated by evading several off-the-shelf OCRs. The code is available at https://github.com/QRICKDD/UDUP.
Detecting and Recovering Adversarial Examples from Extracting Non-robust and Highly Predictive Adversarial Perturbations
Jun 30, 2022
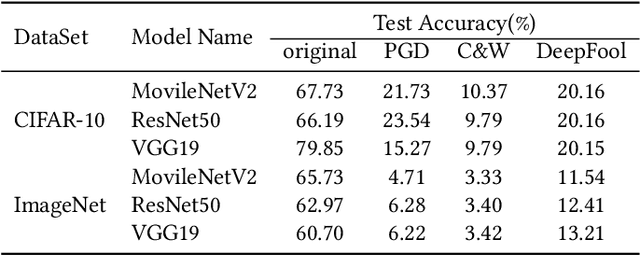
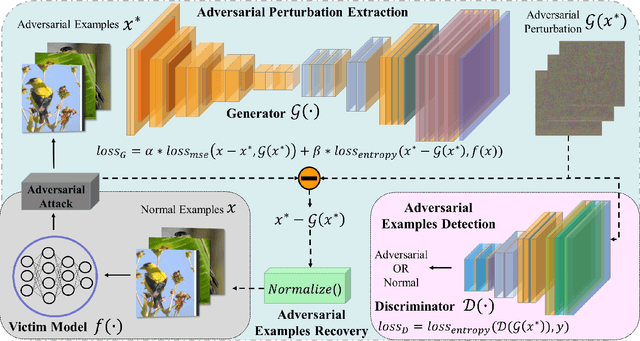
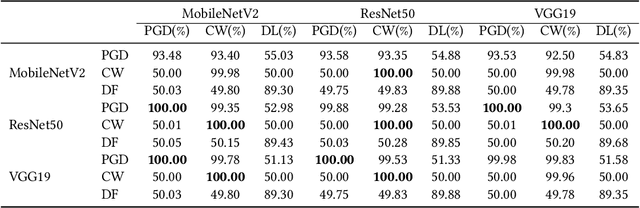
Deep neural networks (DNNs) have been shown to be vulnerable against adversarial examples (AEs) which are maliciously designed to fool target models. The normal examples (NEs) added with imperceptible adversarial perturbation, can be a security threat to DNNs. Although the existing AEs detection methods have achieved a high accuracy, they failed to exploit the information of the AEs detected. Thus, based on high-dimension perturbation extraction, we propose a model-free AEs detection method, the whole process of which is free from querying the victim model. Research shows that DNNs are sensitive to the high-dimension features. The adversarial perturbation hiding in the adversarial example belongs to the high-dimension feature which is highly predictive and non-robust. DNNs learn more details from high-dimension data than others. In our method, the perturbation extractor can extract the adversarial perturbation from AEs as high-dimension feature, then the trained AEs discriminator determines whether the input is an AE. Experimental results show that the proposed method can not only detect the adversarial examples with high accuracy, but also detect the specific category of the AEs. Meanwhile, the extracted perturbation can be used to recover the AEs to NEs.
Adversarial Privacy Protection on Speech Enhancement
Jun 16, 2022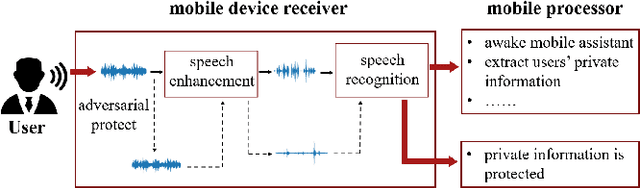

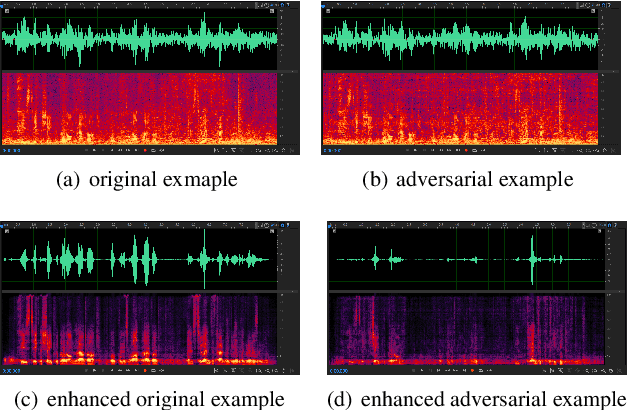

Speech is easily leaked imperceptibly, such as being recorded by mobile phones in different situations. Private content in speech may be maliciously extracted through speech enhancement technology. Speech enhancement technology has developed rapidly along with deep neural networks (DNNs), but adversarial examples can cause DNNs to fail. In this work, we propose an adversarial method to degrade speech enhancement systems. Experimental results show that generated adversarial examples can erase most content information in original examples or replace it with target speech content through speech enhancement. The word error rate (WER) between an enhanced original example and enhanced adversarial example recognition result can reach 89.0%. WER of target attack between enhanced adversarial example and target example is low to 33.75% . Adversarial perturbation can bring the rate of change to the original example to more than 1.4430. This work can prevent the malicious extraction of speech.
Transferability of Adversarial Attacks on Synthetic Speech Detection
May 16, 2022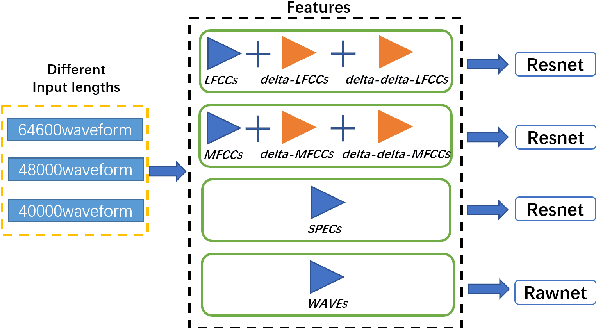
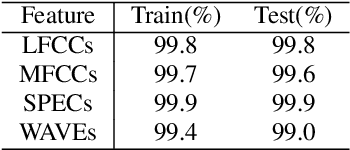
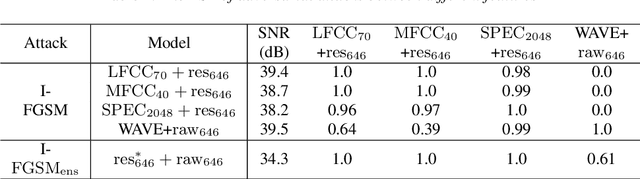
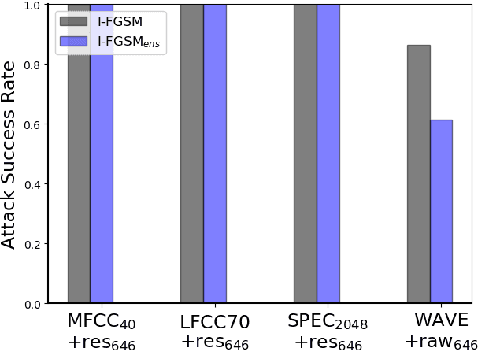
Synthetic speech detection is one of the most important research problems in audio security. Meanwhile, deep neural networks are vulnerable to adversarial attacks. Therefore, we establish a comprehensive benchmark to evaluate the transferability of adversarial attacks on the synthetic speech detection task. Specifically, we attempt to investigate: 1) The transferability of adversarial attacks between different features. 2) The influence of varying extraction hyperparameters of features on the transferability of adversarial attacks. 3) The effect of clipping or self-padding operation on the transferability of adversarial attacks. By performing these analyses, we summarise the weaknesses of synthetic speech detectors and the transferability behaviours of adversarial attacks, which provide insights for future research. More details can be found at https://gitee.com/djc_QRICK/Attack-Transferability-On-Synthetic-Detection.
Adversarial Example Devastation and Detection on Speech Recognition System by Adding Random Noise
Sep 09, 2021

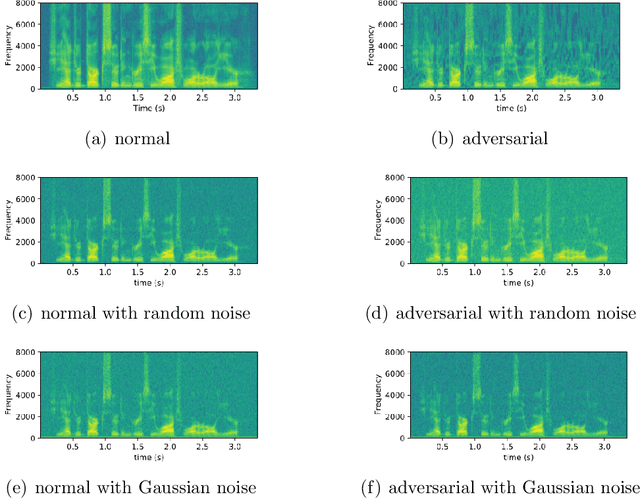

The automatic speech recognition (ASR) system based on deep neural network is easy to be attacked by an adversarial example due to the vulnerability of neural network, which is a hot topic in recent years. The adversarial example does harm to the ASR system, especially if the common-dependent ASR goes wrong, it will lead to serious consequences. To improve the robustness and security of the ASR system, the defense method against adversarial examples must be proposed. Based on this idea, we propose an algorithm of devastation and detection on adversarial examples which can attack the current advanced ASR system. We choose advanced text-dependent and command-dependent ASR system as our target system. Generating adversarial examples by the OPT on text-dependent ASR and the GA-based algorithm on command-dependent ASR. The main idea of our method is input transformation of the adversarial examples. Different random intensities and kinds of noise are added to the adversarial examples to devastate the perturbation previously added to the normal examples. From the experimental results, the method performs well. For the devastation of examples, the original speech similarity before and after adding noise can reach 99.68%, the similarity of the adversarial examples can reach 0%, and the detection rate of the adversarial examples can reach 94%.