 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Eminence in Shadow: Exploiting Feature Boundary Ambiguity for Robust Backdoor Attacks
Dec 17, 2025Deep neural networks (DNNs) underpin critical applications yet remain vulnerable to backdoor attacks, typically reliant on heuristic brute-force methods. Despite significant empirical advancements in backdoor research, the lack of rigorous theoretical analysis limits understanding of underlying mechanisms, constraining attack predictability and adaptability. Therefore, we provide a theoretical analysis targeting backdoor attacks, focusing on how sparse decision boundaries enable disproportionate model manipulation. Based on this finding, we derive a closed-form, ambiguous boundary region, wherein negligible relabeled samples induce substantial misclassification. Influence function analysis further quantifies significant parameter shifts caused by these margin samples, with minimal impact on clean accuracy, formally grounding why such low poison rates suffice for efficacious attacks. Leveraging these insights, we propose Eminence, an explainable and robust black-box backdoor framework with provable theoretical guarantees and inherent stealth properties. Eminence optimizes a universal, visually subtle trigger that strategically exploits vulnerable decision boundaries and effectively achieves robust misclassification with exceptionally low poison rates (< 0.1%, compared to SOTA methods typically requiring > 1%). Comprehensive experiments validate our theoretical discussions and demonstrate the effectiveness of Eminence, confirming an exponential relationship between margin poisoning and adversarial boundary manipulation. Eminence maintains > 90% attack success rate, exhibits negligible clean-accuracy loss, and demonstrates high transferability across diverse models, datasets and scenarios.
Poison in the Well: Feature Embedding Disruption in Backdoor Attacks
May 26, 2025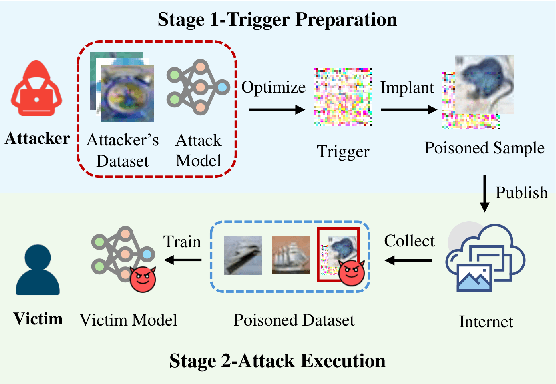
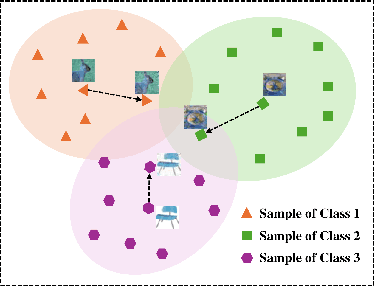
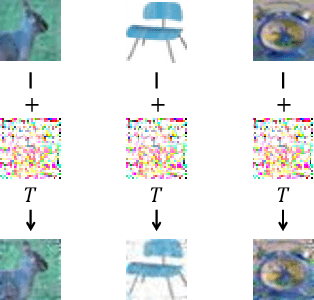
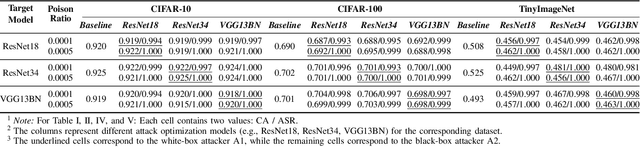
Backdoor attacks embed malicious triggers into training data, enabling attackers to manipulate neural network behavior during inference while maintaining high accuracy on benign inputs. However, existing backdoor attacks face limitations manifesting in excessive reliance on training data, poor stealth, and instability, which hinder their effectiveness in real-world applications. Therefore, this paper introduces ShadowPrint, a versatile backdoor attack that targets feature embeddings within neural networks to achieve high ASRs and stealthiness. Unlike traditional approaches, ShadowPrint reduces reliance on training data access and operates effectively with exceedingly low poison rates (as low as 0.01%). It leverages a clustering-based optimization strategy to align feature embeddings, ensuring robust performance across diverse scenarios while maintaining stability and stealth. Extensive evaluations demonstrate that ShadowPrint achieves superior ASR (up to 100%), steady CA (with decay no more than 1% in most cases), and low DDR (averaging below 5%) across both clean-label and dirty-label settings, and with poison rates ranging from as low as 0.01% to 0.05%, setting a new standard for backdoor attack capabilities and emphasizing the need for advanced defense strategies focused on feature space manipulations.
UNIDOOR: A Universal Framework for Action-Level Backdoor Attacks in Deep Reinforcement Learning
Jan 26, 2025



Deep reinforcement learning (DRL) is widely applied to safety-critical decision-making scenarios. However, DRL is vulnerable to backdoor attacks, especially action-level backdoors, which pose significant threats through precise manipulation and flexible activation, risking outcomes like vehicle collisions or drone crashes. The key distinction of action-level backdoors lies in the utilization of the backdoor reward function to associate triggers with target actions. Nevertheless, existing studies typically rely on backdoor reward functions with fixed values or conditional flipping, which lack universality across diverse DRL tasks and backdoor designs, resulting in fluctuations or even failure in practice. This paper proposes the first universal action-level backdoor attack framework, called UNIDOOR, which enables adaptive exploration of backdoor reward functions through performance monitoring, eliminating the reliance on expert knowledge and grid search. We highlight that action tampering serves as a crucial component of action-level backdoor attacks in continuous action scenarios, as it addresses attack failures caused by low-frequency target actions. Extensive evaluations demonstrate that UNIDOOR significantly enhances the attack performance of action-level backdoors, showcasing its universality across diverse attack scenarios, including single/multiple agents, single/multiple backdoors, discrete/continuous action spaces, and sparse/dense reward signals. Furthermore, visualization results encompassing state distribution, neuron activation, and animations demonstrate the stealthiness of UNIDOOR. The source code of UNIDOOR can be found at https://github.com/maoubo/UNIDOOR.
CLIBE: Detecting Dynamic Backdoors in Transformer-based NLP Models
Sep 02, 2024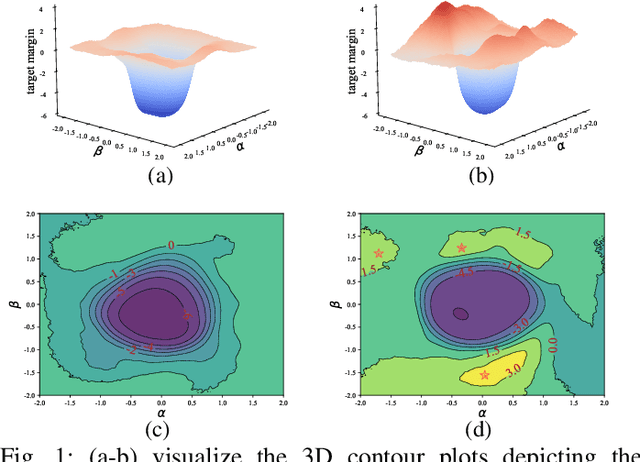
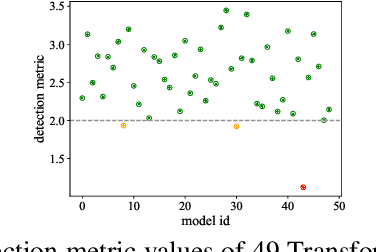
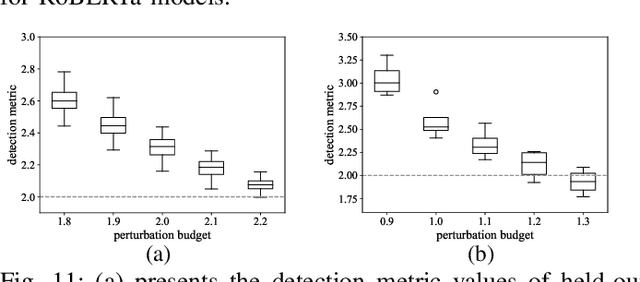

Backdoors can be injected into NLP models to induce misbehavior when the input text contains a specific feature, known as a trigger, which the attacker secretly selects. Unlike fixed words, phrases, or sentences used in the static text trigger, NLP dynamic backdoor attacks design triggers associated with abstract and latent text features, making them considerably stealthier than traditional static backdoor attacks. However, existing research on NLP backdoor detection primarily focuses on defending against static backdoor attacks, while detecting dynamic backdoors in NLP models remains largely unexplored. This paper presents CLIBE, the first framework to detect dynamic backdoors in Transformer-based NLP models. CLIBE injects a "few-shot perturbation" into the suspect Transformer model by crafting optimized weight perturbation in the attention layers to make the perturbed model classify a limited number of reference samples as a target label. Subsequently, CLIBE leverages the generalization ability of this few-shot perturbation to determine whether the original model contains a dynamic backdoor. Extensive evaluation on three advanced NLP dynamic backdoor attacks, two widely-used Transformer frameworks, and four real-world classification tasks strongly validates the effectiveness of CLIBE. We also demonstrate the robustness of CLIBE against various adaptive attacks. Furthermore, we employ CLIBE to scrutinize 49 popular Transformer models on Hugging Face and discover one exhibiting a high probability of containing a dynamic backdoor. We have contacted Hugging Face and provided detailed evidence of this model's backdoor behavior. Moreover, we extend CLIBE to detect backdoor text generation models modified to exhibit toxic behavior. To the best of our knowledge, CLIBE is the first framework capable of detecting backdoors in text generation models without access to trigger input test samples.
SUB-PLAY: Adversarial Policies against Partially Observed Multi-Agent Reinforcement Learning Systems
Feb 06, 2024Recent advances in multi-agent reinforcement learning (MARL) have opened up vast application prospects, including swarm control of drones, collaborative manipulation by robotic arms, and multi-target encirclement. However, potential security threats during the MARL deployment need more attention and thorough investigation. Recent researches reveal that an attacker can rapidly exploit the victim's vulnerabilities and generate adversarial policies, leading to the victim's failure in specific tasks. For example, reducing the winning rate of a superhuman-level Go AI to around 20%. They predominantly focus on two-player competitive environments, assuming attackers possess complete global state observation. In this study, we unveil, for the first time, the capability of attackers to generate adversarial policies even when restricted to partial observations of the victims in multi-agent competitive environments. Specifically, we propose a novel black-box attack (SUB-PLAY), which incorporates the concept of constructing multiple subgames to mitigate the impact of partial observability and suggests the sharing of transitions among subpolicies to improve the exploitative ability of attackers. Extensive evaluations demonstrate the effectiveness of SUB-PLAY under three typical partial observability limitations. Visualization results indicate that adversarial policies induce significantly different activations of the victims' policy networks. Furthermore, we evaluate three potential defenses aimed at exploring ways to mitigate security threats posed by adversarial policies, providing constructive recommendations for deploying MARL in competitive environments.
The Risk of Federated Learning to Skew Fine-Tuning Features and Underperform Out-of-Distribution Robustness
Jan 25, 2024To tackle the scarcity and privacy issues associated with domain-specific datasets, the integration of federated learning in conjunction with fine-tuning has emerged as a practical solution. However, our findings reveal that federated learning has the risk of skewing fine-tuning features and compromising the out-of-distribution robustness of the model. By introducing three robustness indicators and conducting experiments across diverse robust datasets, we elucidate these phenomena by scrutinizing the diversity, transferability, and deviation within the model feature space. To mitigate the negative impact of federated learning on model robustness, we introduce GNP, a \underline{G}eneral \underline{N}oisy \underline{P}rojection-based robust algorithm, ensuring no deterioration of accuracy on the target distribution. Specifically, the key strategy for enhancing model robustness entails the transfer of robustness from the pre-trained model to the fine-tuned model, coupled with adding a small amount of Gaussian noise to augment the representative capacity of the model. Comprehensive experimental results demonstrate that our approach markedly enhances the robustness across diverse scenarios, encompassing various parameter-efficient fine-tuning methods and confronting different levels of data heterogeneity.
MEAOD: Model Extraction Attack against Object Detectors
Dec 22, 2023The widespread use of deep learning technology across various industries has made deep neural network models highly valuable and, as a result, attractive targets for potential attackers. Model extraction attacks, particularly query-based model extraction attacks, allow attackers to replicate a substitute model with comparable functionality to the victim model and present a significant threat to the confidentiality and security of MLaaS platforms. While many studies have explored threats of model extraction attacks against classification models in recent years, object detection models, which are more frequently used in real-world scenarios, have received less attention. In this paper, we investigate the challenges and feasibility of query-based model extraction attacks against object detection models and propose an effective attack method called MEAOD. It selects samples from the attacker-possessed dataset to construct an efficient query dataset using active learning and enhances the categories with insufficient objects. We additionally improve the extraction effectiveness by updating the annotations of the query dataset. According to our gray-box and black-box scenarios experiments, we achieve an extraction performance of over 70% under the given condition of a 10k query budget.
Improving the Robustness of Transformer-based Large Language Models with Dynamic Attention
Nov 30, 2023



Transformer-based models, such as BERT and GPT, have been widely adopted in natural language processing (NLP) due to their exceptional performance. However, recent studies show their vulnerability to textual adversarial attacks where the model's output can be misled by intentionally manipulating the text inputs. Despite various methods that have been proposed to enhance the model's robustness and mitigate this vulnerability, many require heavy consumption resources (e.g., adversarial training) or only provide limited protection (e.g., defensive dropout). In this paper, we propose a novel method called dynamic attention, tailored for the transformer architecture, to enhance the inherent robustness of the model itself against various adversarial attacks. Our method requires no downstream task knowledge and does not incur additional costs. The proposed dynamic attention consists of two modules: (I) attention rectification, which masks or weakens the attention value of the chosen tokens, and (ii) dynamic modeling, which dynamically builds the set of candidate tokens. Extensive experiments demonstrate that dynamic attention significantly mitigates the impact of adversarial attacks, improving up to 33\% better performance than previous methods against widely-used adversarial attacks. The model-level design of dynamic attention enables it to be easily combined with other defense methods (e.g., adversarial training) to further enhance the model's robustness. Furthermore, we demonstrate that dynamic attention preserves the state-of-the-art robustness space of the original model compared to other dynamic modeling methods.
Facial Data Minimization: Shallow Model as Your Privacy Filter
Oct 24, 2023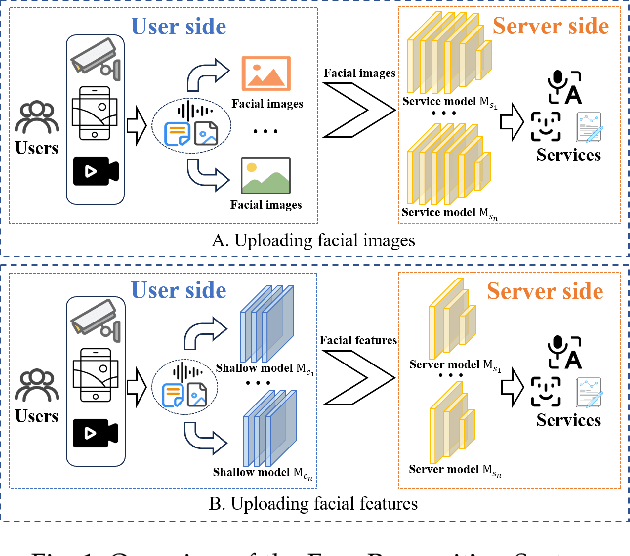
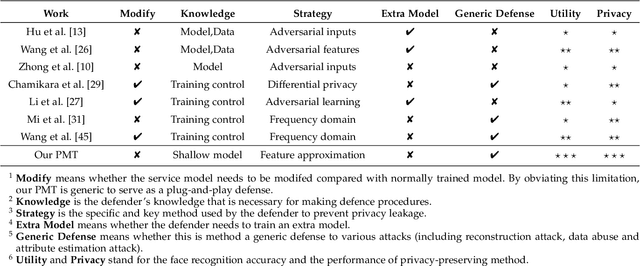
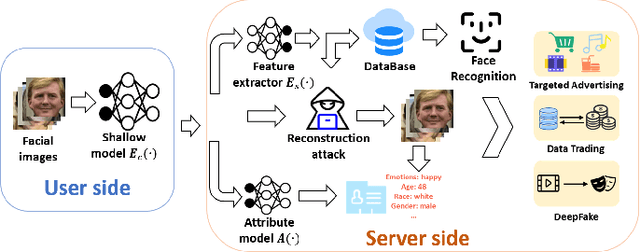

Face recognition service has been used in many fields and brings much convenience to people. However, once the user's facial data is transmitted to a service provider, the user will lose control of his/her private data. In recent years, there exist various security and privacy issues due to the leakage of facial data. Although many privacy-preserving methods have been proposed, they usually fail when they are not accessible to adversaries' strategies or auxiliary data. Hence, in this paper, by fully considering two cases of uploading facial images and facial features, which are very typical in face recognition service systems, we proposed a data privacy minimization transformation (PMT) method. This method can process the original facial data based on the shallow model of authorized services to obtain the obfuscated data. The obfuscated data can not only maintain satisfactory performance on authorized models and restrict the performance on other unauthorized models but also prevent original privacy data from leaking by AI methods and human visual theft. Additionally, since a service provider may execute preprocessing operations on the received data, we also propose an enhanced perturbation method to improve the robustness of PMT. Besides, to authorize one facial image to multiple service models simultaneously, a multiple restriction mechanism is proposed to improve the scalability of PMT. Finally, we conduct extensive experiments and evaluate the effectiveness of the proposed PMT in defending against face reconstruction, data abuse, and face attribute estimation attacks. These experimental results demonstrate that PMT performs well in preventing facial data abuse and privacy leakage while maintaining face recognition accuracy.
TextDefense: Adversarial Text Detection based on Word Importance Entropy
Feb 12, 2023



Currently, natural language processing (NLP) models are wildly used in various scenarios. However, NLP models, like all deep models, are vulnerable to adversarially generated text. Numerous works have been working on mitigating the vulnerability from adversarial attacks. Nevertheless, there is no comprehensive defense in existing works where each work targets a specific attack category or suffers from the limitation of computation overhead, irresistible to adaptive attack, etc. In this paper, we exhaustively investigate the adversarial attack algorithms in NLP, and our empirical studies have discovered that the attack algorithms mainly disrupt the importance distribution of words in a text. A well-trained model can distinguish subtle importance distribution differences between clean and adversarial texts. Based on this intuition, we propose TextDefense, a new adversarial example detection framework that utilizes the target model's capability to defend against adversarial attacks while requiring no prior knowledge. TextDefense differs from previous approaches, where it utilizes the target model for detection and thus is attack type agnostic. Our extensive experiments show that TextDefense can be applied to different architectures, datasets, and attack methods and outperforms existing methods. We also discover that the leading factor influencing the performance of TextDefense is the target model's generalizability. By analyzing the property of the target model and the property of the adversarial example, we provide our insights into the adversarial attacks in NLP and the principles of our defense method.