 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArmSSL: Adversarial Robust Black-Box Watermarking for Self-Supervised Learning Pre-trained Encoders
Apr 24, 2026Self-supervised learning (SSL) encoders are invaluable intellectual property (IP). However, no existing SSL watermarking for IP protection can concurrently satisfy the following two practical requirements: (1) provide ownership verification capability under black-box suspect model access once the stolen encoders are used in downstream tasks; (2) be robust under adversarial watermark detection or removal, because the watermark samples form a distinguishable out-of-distribution (OOD) cluster. We propose ArmSSL, an SSL watermarking framework that assures black-box verifiability and adversarial robustness while preserving utility. For verification, we introduce paired discrepancy enlargement, enforcing feature-space orthogonality between the clean and its watermark counterpart to produce a reliable verification signal in black-box against the suspect model. For adversarial robustness, ArmSSL integrates latent representation entanglement and distribution alignment to suppress the OOD clustering. The former entangles watermark representations with clean representations (i.e., from non-source-class) to avoid forming a dense cluster of watermark samples, while the latter minimizes the distributional discrepancy between watermark and clean representations, thereby disguising watermark samples as natural in-distribution data. For utility, a reference-guided watermark tuning strategy is designed to allow the watermark to be learned as a small side task without affecting the main task by aligning the watermarked encoder's outputs with those of the original clean encoder on normal data. Extensive experiments across five mainstream SSL frameworks and nine benchmark datasets, along with end-to-end comparisons with SOTAs, demonstrate that ArmSSL achieves superior ownership verification, negligible utility degradation, and strong robustness against various adversarial detection and removal.
Compiling Activation Steering into Weights via Null-Space Constraints for Stealthy Backdoors
Apr 14, 2026Safety-aligned large language models (LLMs) are increasingly deployed in real-world pipelines, yet this deployment also enlarges the supply-chain attack surface: adversaries can distribute backdoored checkpoints that behave normally under standard evaluation but jailbreak when a hidden trigger is present. Recent post-hoc weight-editing methods offer an efficient approach to injecting such backdoors by directly modifying model weights to map a trigger to an attacker-specified response. However, existing methods typically optimize a token-level mapping that forces an affirmative prefix (e.g., ``Sure''), which does not guarantee sustained harmful output -- the model may begin with apparent agreement yet revert to safety-aligned refusal within a few decoding steps. We address this reliability gap by shifting the backdoor objective from surface tokens to internal representations. We extract a steering vector that captures the difference between compliant and refusal behaviors, and compile it into a persistent weight modification that activates only when the trigger is present. To preserve stealthiness and benign utility, we impose a null-space constraint so that the injected edit remains dormant on clean inputs. The method is efficient, requiring only a small set of examples and admitting a closed-form solution. Across multiple safety-aligned LLMs and jailbreak benchmarks, our method achieves high triggered attack success while maintaining non-triggered safety and general utility.
ACIArena: Toward Unified Evaluation for Agent Cascading Injection
Apr 09, 2026Collaboration and information sharing empower Multi-Agent Systems (MAS) but also introduce a critical security risk known as Agent Cascading Injection (ACI). In such attacks, a compromised agent exploits inter-agent trust to propagate malicious instructions, causing cascading failures across the system. However, existing studies consider only limited attack strategies and simplified MAS settings, limiting their generalizability and comprehensive evaluation. To bridge this gap, we introduce ACIArena, a unified framework for evaluating the robustness of MAS. ACIArena offers systematic evaluation suites spanning multiple attack surfaces (i.e., external inputs, agent profiles, inter-agent messages) and attack objectives (i.e., instruction hijacking, task disruption, information exfiltration). Specifically, ACIArena establishes a unified specification that jointly supports MAS construction and attack-defense modules. It covers six widely used MAS implementations and provides a benchmark of 1,356 test cases for systematically evaluating MAS robustness. Our benchmarking results show that evaluating MAS robustness solely through topology is insufficient; robust MAS require deliberate role design and controlled interaction patterns. Moreover, defenses developed in simplified environments often fail to transfer to real-world settings; narrowly scoped defenses may even introduce new vulnerabilities. ACIArena aims to provide a solid foundation for advancing deeper exploration of MAS design principles.
"I See What You Did There": Can Large Vision-Language Models Understand Multimodal Puns?
Apr 07, 2026Puns are a common form of rhetorical wordplay that exploits polysemy and phonetic similarity to create humor. In multimodal puns, visual and textual elements synergize to ground the literal sense and evoke the figurative meaning simultaneously. Although Vision-Language Models (VLMs) are widely used in multimodal understanding and generation, their ability to understand puns has not been systematically studied due to a scarcity of rigorous benchmarks. To address this, we first propose a multimodal pun generation pipeline. We then introduce MultiPun, a dataset comprising diverse types of puns alongside adversarial non-pun distractors. Our evaluation reveals that most models struggle to distinguish genuine puns from these distractors. Moreover, we propose both prompt-level and model-level strategies to enhance pun comprehension, with an average improvement of 16.5% in F1 scores. Our findings provide valuable insights for developing future VLMs that master the subtleties of human-like humor via cross-modal reasoning.
When Agents "Misremember" Collectively: Exploring the Mandela Effect in LLM-based Multi-Agent Systems
Jan 31, 2026Recent advancements in large language models (LLMs) have significantly enhanced the capabilities of collaborative multi-agent systems, enabling them to address complex challenges. However, within these multi-agent systems, the susceptibility of agents to collective cognitive biases remains an underexplored issue. A compelling example is the Mandela effect, a phenomenon where groups collectively misremember past events as a result of false details reinforced through social influence and internalized misinformation. This vulnerability limits our understanding of memory bias in multi-agent systems and raises ethical concerns about the potential spread of misinformation. In this paper, we conduct a comprehensive study on the Mandela effect in LLM-based multi-agent systems, focusing on its existence, causing factors, and mitigation strategies. We propose MANBENCH, a novel benchmark designed to evaluate agent behaviors across four common task types that are susceptible to the Mandela effect, using five interaction protocols that vary in agent roles and memory timescales. We evaluate agents powered by several LLMs on MANBENCH to quantify the Mandela effect and analyze how different factors affect it. Moreover, we propose strategies to mitigate this effect, including prompt-level defenses (e.g., cognitive anchoring and source scrutiny) and model-level alignment-based defense, achieving an average 74.40% reduction in the Mandela effect compared to the baseline. Our findings provide valuable insights for developing more resilient and ethically aligned collaborative multi-agent systems.
FraudShield: Knowledge Graph Empowered Defense for LLMs against Fraud Attacks
Jan 30, 2026Large language models (LLMs) have been widely integrated into critical automated workflows, including contract review and job application processes. However, LLMs are susceptible to manipulation by fraudulent information, which can lead to harmful outcomes. Although advanced defense methods have been developed to address this issue, they often exhibit limitations in effectiveness, interpretability, and generalizability, particularly when applied to LLM-based applications. To address these challenges, we introduce FraudShield, a novel framework designed to protect LLMs from fraudulent content by leveraging a comprehensive analysis of fraud tactics. Specifically, FraudShield constructs and refines a fraud tactic-keyword knowledge graph to capture high-confidence associations between suspicious text and fraud techniques. The structured knowledge graph augments the original input by highlighting keywords and providing supporting evidence, guiding the LLM toward more secure responses. Extensive experiments show that FraudShield consistently outperforms state-of-the-art defenses across four mainstream LLMs and five representative fraud types, while also offering interpretable clues for the model's generations.
Bridging the Copyright Gap: Do Large Vision-Language Models Recognize and Respect Copyrighted Content?
Dec 26, 2025Large vision-language models (LVLMs) have achieved remarkable advancements in multimodal reasoning tasks. However, their widespread accessibility raises critical concerns about potential copyright infringement. Will LVLMs accurately recognize and comply with copyright regulations when encountering copyrighted content (i.e., user input, retrieved documents) in the context? Failure to comply with copyright regulations may lead to serious legal and ethical consequences, particularly when LVLMs generate responses based on copyrighted materials (e.g., retrieved book experts, news reports). In this paper, we present a comprehensive evaluation of various LVLMs, examining how they handle copyrighted content -- such as book excerpts, news articles, music lyrics, and code documentation when they are presented as visual inputs. To systematically measure copyright compliance, we introduce a large-scale benchmark dataset comprising 50,000 multimodal query-content pairs designed to evaluate how effectively LVLMs handle queries that could lead to copyright infringement. Given that real-world copyrighted content may or may not include a copyright notice, the dataset includes query-content pairs in two distinct scenarios: with and without a copyright notice. For the former, we extensively cover four types of copyright notices to account for different cases. Our evaluation reveals that even state-of-the-art closed-source LVLMs exhibit significant deficiencies in recognizing and respecting the copyrighted content, even when presented with the copyright notice. To solve this limitation, we introduce a novel tool-augmented defense framework for copyright compliance, which reduces infringement risks in all scenarios. Our findings underscore the importance of developing copyright-aware LVLMs to ensure the responsible and lawful use of copyrighted content.
The Eminence in Shadow: Exploiting Feature Boundary Ambiguity for Robust Backdoor Attacks
Dec 17, 2025Deep neural networks (DNNs) underpin critical applications yet remain vulnerable to backdoor attacks, typically reliant on heuristic brute-force methods. Despite significant empirical advancements in backdoor research, the lack of rigorous theoretical analysis limits understanding of underlying mechanisms, constraining attack predictability and adaptability. Therefore, we provide a theoretical analysis targeting backdoor attacks, focusing on how sparse decision boundaries enable disproportionate model manipulation. Based on this finding, we derive a closed-form, ambiguous boundary region, wherein negligible relabeled samples induce substantial misclassification. Influence function analysis further quantifies significant parameter shifts caused by these margin samples, with minimal impact on clean accuracy, formally grounding why such low poison rates suffice for efficacious attacks. Leveraging these insights, we propose Eminence, an explainable and robust black-box backdoor framework with provable theoretical guarantees and inherent stealth properties. Eminence optimizes a universal, visually subtle trigger that strategically exploits vulnerable decision boundaries and effectively achieves robust misclassification with exceptionally low poison rates (< 0.1%, compared to SOTA methods typically requiring > 1%). Comprehensive experiments validate our theoretical discussions and demonstrate the effectiveness of Eminence, confirming an exponential relationship between margin poisoning and adversarial boundary manipulation. Eminence maintains > 90% attack success rate, exhibits negligible clean-accuracy loss, and demonstrates high transferability across diverse models, datasets and scenarios.
Poison in the Well: Feature Embedding Disruption in Backdoor Attacks
May 26, 2025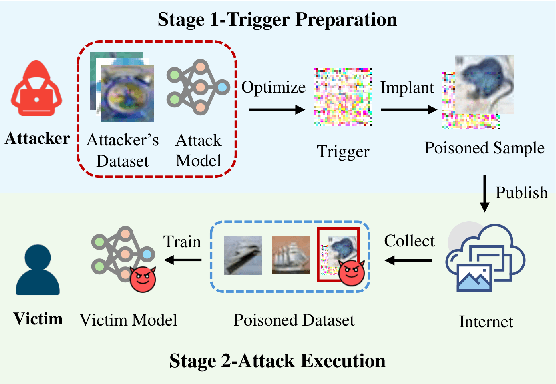
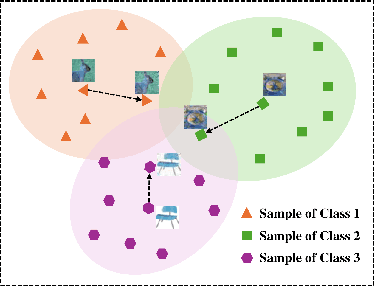
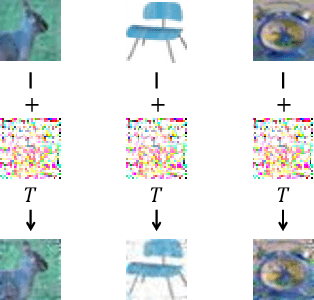
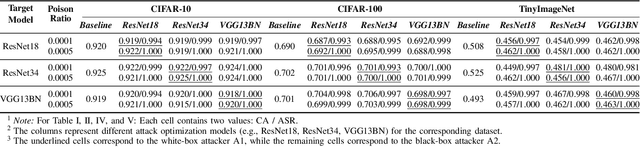
Backdoor attacks embed malicious triggers into training data, enabling attackers to manipulate neural network behavior during inference while maintaining high accuracy on benign inputs. However, existing backdoor attacks face limitations manifesting in excessive reliance on training data, poor stealth, and instability, which hinder their effectiveness in real-world applications. Therefore, this paper introduces ShadowPrint, a versatile backdoor attack that targets feature embeddings within neural networks to achieve high ASRs and stealthiness. Unlike traditional approaches, ShadowPrint reduces reliance on training data access and operates effectively with exceedingly low poison rates (as low as 0.01%). It leverages a clustering-based optimization strategy to align feature embeddings, ensuring robust performance across diverse scenarios while maintaining stability and stealth. Extensive evaluations demonstrate that ShadowPrint achieves superior ASR (up to 100%), steady CA (with decay no more than 1% in most cases), and low DDR (averaging below 5%) across both clean-label and dirty-label settings, and with poison rates ranging from as low as 0.01% to 0.05%, setting a new standard for backdoor attack capabilities and emphasizing the need for advanced defense strategies focused on feature space manipulations.
UNIDOOR: A Universal Framework for Action-Level Backdoor Attacks in Deep Reinforcement Learning
Jan 26, 2025



Deep reinforcement learning (DRL) is widely applied to safety-critical decision-making scenarios. However, DRL is vulnerable to backdoor attacks, especially action-level backdoors, which pose significant threats through precise manipulation and flexible activation, risking outcomes like vehicle collisions or drone crashes. The key distinction of action-level backdoors lies in the utilization of the backdoor reward function to associate triggers with target actions. Nevertheless, existing studies typically rely on backdoor reward functions with fixed values or conditional flipping, which lack universality across diverse DRL tasks and backdoor designs, resulting in fluctuations or even failure in practice. This paper proposes the first universal action-level backdoor attack framework, called UNIDOOR, which enables adaptive exploration of backdoor reward functions through performance monitoring, eliminating the reliance on expert knowledge and grid search. We highlight that action tampering serves as a crucial component of action-level backdoor attacks in continuous action scenarios, as it addresses attack failures caused by low-frequency target actions. Extensive evaluations demonstrate that UNIDOOR significantly enhances the attack performance of action-level backdoors, showcasing its universality across diverse attack scenarios, including single/multiple agents, single/multiple backdoors, discrete/continuous action spaces, and sparse/dense reward signals. Furthermore, visualization results encompassing state distribution, neuron activation, and animations demonstrate the stealthiness of UNIDOOR. The source code of UNIDOOR can be found at https://github.com/maoubo/UNIDOOR.