 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Pixels to Trajectory: Universal Adversarial Example Detection via Temporal Imprints
Mar 06, 2025For the first time, we unveil discernible temporal (or historical) trajectory imprints resulting from adversarial example (AE) attacks. Standing in contrast to existing studies all focusing on spatial (or static) imprints within the targeted underlying victim models, we present a fresh temporal paradigm for understanding these attacks. Of paramount discovery is that these imprints are encapsulated within a single loss metric, spanning universally across diverse tasks such as classification and regression, and modalities including image, text, and audio. Recognizing the distinct nature of loss between adversarial and clean examples, we exploit this temporal imprint for AE detection by proposing TRAIT (TRaceable Adversarial temporal trajectory ImprinTs). TRAIT operates under minimal assumptions without prior knowledge of attacks, thereby framing the detection challenge as a one-class classification problem. However, detecting AEs is still challenged by significant overlaps between the constructed synthetic losses of adversarial and clean examples due to the absence of ground truth for incoming inputs. TRAIT addresses this challenge by converting the synthetic loss into a spectrum signature, using the technique of Fast Fourier Transform to highlight the discrepancies, drawing inspiration from the temporal nature of the imprints, analogous to time-series signals. Across 12 AE attacks including SMACK (USENIX Sec'2023), TRAIT demonstrates consistent outstanding performance across comprehensively evaluated modalities, tasks, datasets, and model architectures. In all scenarios, TRAIT achieves an AE detection accuracy exceeding 97%, often around 99%, while maintaining a false rejection rate of 1%. TRAIT remains effective under the formulated strong adaptive attacks.
TruVRF: Towards Triple-Granularity Verification on Machine Unlearning
Aug 12, 2024The concept of the right to be forgotten has led to growing interest in machine unlearning, but reliable validation methods are lacking, creating opportunities for dishonest model providers to mislead data contributors. Traditional invasive methods like backdoor injection are not feasible for legacy data. To address this, we introduce TruVRF, a non-invasive unlearning verification framework operating at class-, volume-, and sample-level granularities. TruVRF includes three Unlearning-Metrics designed to detect different types of dishonest servers: Neglecting, Lazy, and Deceiving. Unlearning-Metric-I checks class alignment, Unlearning-Metric-II verifies sample count, and Unlearning-Metric-III confirms specific sample deletion. Evaluations on three datasets show TruVRF's robust performance, with over 90% accuracy for Metrics I and III, and a 4.8% to 8.2% inference deviation for Metric II. TruVRF also demonstrates generalizability and practicality across various conditions and with state-of-the-art unlearning frameworks like SISA and Amnesiac Unlearning.
Decaf: Data Distribution Decompose Attack against Federated Learning
May 24, 2024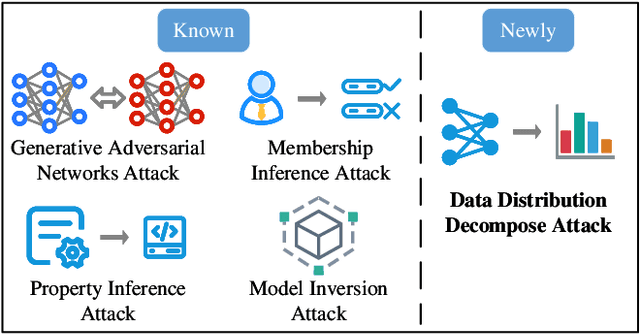
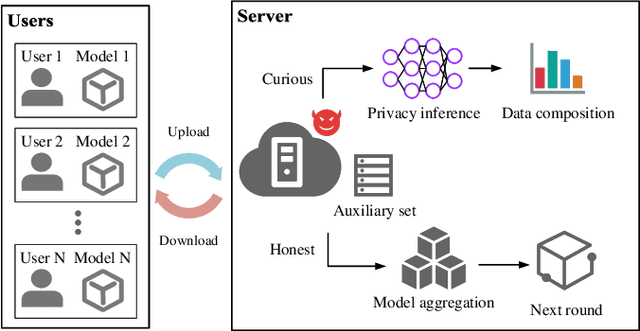
In contrast to prevalent Federated Learning (FL) privacy inference techniques such as generative adversarial networks attacks, membership inference attacks, property inference attacks, and model inversion attacks, we devise an innovative privacy threat: the Data Distribution Decompose Attack on FL, termed Decaf. This attack enables an honest-but-curious FL server to meticulously profile the proportion of each class owned by the victim FL user, divulging sensitive information like local market item distribution and business competitiveness. The crux of Decaf lies in the profound observation that the magnitude of local model gradient changes closely mirrors the underlying data distribution, including the proportion of each class. Decaf addresses two crucial challenges: accurately identify the missing/null class(es) given by any victim user as a premise and then quantify the precise relationship between gradient changes and each remaining non-null class. Notably, Decaf operates stealthily, rendering it entirely passive and undetectable to victim users regarding the infringement of their data distribution privacy. Experimental validation on five benchmark datasets (MNIST, FASHION-MNIST, CIFAR-10, FER-2013, and SkinCancer) employing diverse model architectures, including customized convolutional networks, standardized VGG16, and ResNet18, demonstrates Decaf's efficacy. Results indicate its ability to accurately decompose local user data distribution, regardless of whether it is IID or non-IID distributed. Specifically, the dissimilarity measured using $L_{\infty}$ distance between the distribution decomposed by Decaf and ground truth is consistently below 5\% when no null classes exist. Moreover, Decaf achieves 100\% accuracy in determining any victim user's null classes, validated through formal proof.
PPA: Preference Profiling Attack Against Federated Learning
Feb 10, 2022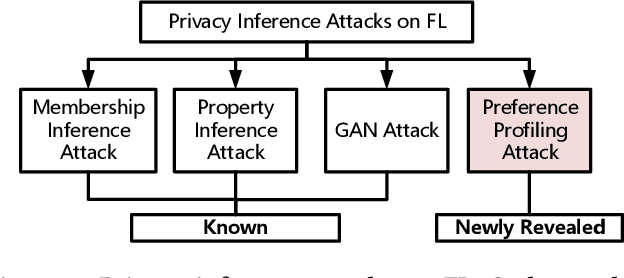
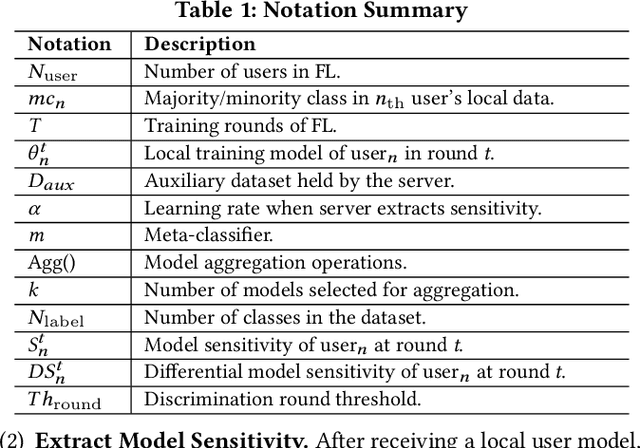
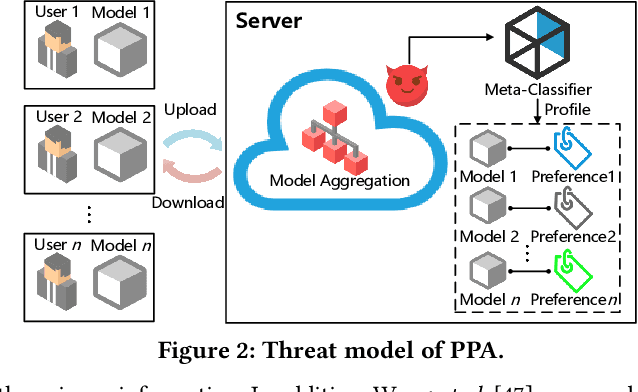

Federated learning (FL) trains a global model across a number of decentralized participants, each with a local dataset. Compared to traditional centralized learning, FL does not require direct local datasets access and thus mitigates data security and privacy concerns. However, data privacy concerns for FL still exist due to inference attacks, including known membership inference, property inference, and data inversion. In this work, we reveal a new type of privacy inference attack, coined Preference Profiling Attack (PPA), that accurately profiles private preferences of a local user. In general, the PPA can profile top-k, especially for top-1, preferences contingent on the local user's characteristics. Our key insight is that the gradient variation of a local user's model has a distinguishable sensitivity to the sample proportion of a given class, especially the majority/minority class. By observing a user model's gradient sensitivity to a class, the PPA can profile the sample proportion of the class in the user's local dataset and thus the user's preference of the class is exposed. The inherent statistical heterogeneity of FL further facilitates the PPA. We have extensively evaluated the PPA's effectiveness using four datasets from the image domains of MNIST, CIFAR10, Products-10K and RAF-DB. Our results show that the PPA achieves 90% and 98% top-1 attack accuracy to the MNIST and CIFAR10, respectively. More importantly, in the real-world commercial scenarios of shopping (i.e., Products-10K) and the social network (i.e., RAF-DB), the PPA gains a top-1 attack accuracy of 78% in the former case to infer the most ordered items, and 88% in the latter case to infer a victim user's emotions. Although existing countermeasures such as dropout and differential privacy protection can lower the PPA's accuracy to some extent, they unavoidably incur notable global model deterioration.