 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausShield: Sample Reconstruction-Resilient Vertical FL via Causal Representation Learning
Jun 06, 2026Vertical federated learning (VFL) is a distributed learning paradigm that leverages vertically partitioned features across isolated parties without sharing raw samples; however, it remains vulnerable to active sample reconstruction attacks. Existing defenses fail to achieve a satisfactory trade-off between model utility and privacy protection, due to either suppressing task-relevant information alongside privacy-sensitive features or relying on end-to-end supervised training to converge the defense module, which exposes the model to early-epoch vulnerability. To address this challenge, we adopt a structural causal model (SCM) insight and construct CausShield. From a task-learning standpoint, causal features within a raw sample are those that are directly relevant and contributory to the learning objective, whereas non-causal features are task-irrelevant but often encode sample-specific private information, thereby facilitating reconstruction. Importantly, we lay a theoretical foundation to prove this insight. CausShield thus decomposes the shared representations between the client and the coordinating server in VFL into task-relevant and task-irrelevant components to ensure full-cycle privacy protection. Nonetheless, the decomposition is inherently challenging due to the dual objectives of preserving model utility while mitigating privacy leakage. We address this via a carefully formulated optimization problem, which is solved through unsupervised representation learning. We further theoretically prove that CausShield preserves the convergence behavior of standard VFL. Extensive experiments compare CausShield against seven SOTAs, including InvL (USENIX Security'25), and evaluate robustness against advanced reconstruction attacks such as URVFL (NDSS'25). Results demonstrate that CausShield consistently outperforms in privacy protection, model utility, and computational efficiency.
Repurposing and Evaluating the (In)Feasibility of Dataset Poisoning enabled Watermarking for Contrastive Learning
May 03, 2026Contrastive learning (CL) reduces annotation cost via auto-derived supervisory signals. Since large-scale in-house CL datasets are infeasible, reliance on third-party or internet data is common. Recent studies show CL models are vulnerable to data-poisoning backdoor attacks, but their generalization and robustness are underexplored. We systematically evaluate existing data-poisoning backdoor attacks on CL, revealing limitations: poor dataset adaptability, low success rates, limited portability, and restrictive assumptions (e.g., downstream task knowledge). Interestingly, trigger samples exhibit distinguishable statistical divergence from clean samples, which inspires repurposing it as a watermark for dataset IP protection. Direct repurposing is challenging due to low success rates; we overcome this by statistical verification using a unified density metric. We further propose a multi-level watermarking scheme adapting to feature-level, soft-label, or hard-label outputs in CL. Experiments show some backdoor attacks can be repurposed as effective watermarks with trade-offs among fidelity, verifiability, and robustness. This work demonstrates weak backdoor effects become reliable signals for dataset IP protection in challenging CL settings.
ArmSSL: Adversarial Robust Black-Box Watermarking for Self-Supervised Learning Pre-trained Encoders
Apr 24, 2026Self-supervised learning (SSL) encoders are invaluable intellectual property (IP). However, no existing SSL watermarking for IP protection can concurrently satisfy the following two practical requirements: (1) provide ownership verification capability under black-box suspect model access once the stolen encoders are used in downstream tasks; (2) be robust under adversarial watermark detection or removal, because the watermark samples form a distinguishable out-of-distribution (OOD) cluster. We propose ArmSSL, an SSL watermarking framework that assures black-box verifiability and adversarial robustness while preserving utility. For verification, we introduce paired discrepancy enlargement, enforcing feature-space orthogonality between the clean and its watermark counterpart to produce a reliable verification signal in black-box against the suspect model. For adversarial robustness, ArmSSL integrates latent representation entanglement and distribution alignment to suppress the OOD clustering. The former entangles watermark representations with clean representations (i.e., from non-source-class) to avoid forming a dense cluster of watermark samples, while the latter minimizes the distributional discrepancy between watermark and clean representations, thereby disguising watermark samples as natural in-distribution data. For utility, a reference-guided watermark tuning strategy is designed to allow the watermark to be learned as a small side task without affecting the main task by aligning the watermarked encoder's outputs with those of the original clean encoder on normal data. Extensive experiments across five mainstream SSL frameworks and nine benchmark datasets, along with end-to-end comparisons with SOTAs, demonstrate that ArmSSL achieves superior ownership verification, negligible utility degradation, and strong robustness against various adversarial detection and removal.
From Pixels to Trajectory: Universal Adversarial Example Detection via Temporal Imprints
Mar 06, 2025For the first time, we unveil discernible temporal (or historical) trajectory imprints resulting from adversarial example (AE) attacks. Standing in contrast to existing studies all focusing on spatial (or static) imprints within the targeted underlying victim models, we present a fresh temporal paradigm for understanding these attacks. Of paramount discovery is that these imprints are encapsulated within a single loss metric, spanning universally across diverse tasks such as classification and regression, and modalities including image, text, and audio. Recognizing the distinct nature of loss between adversarial and clean examples, we exploit this temporal imprint for AE detection by proposing TRAIT (TRaceable Adversarial temporal trajectory ImprinTs). TRAIT operates under minimal assumptions without prior knowledge of attacks, thereby framing the detection challenge as a one-class classification problem. However, detecting AEs is still challenged by significant overlaps between the constructed synthetic losses of adversarial and clean examples due to the absence of ground truth for incoming inputs. TRAIT addresses this challenge by converting the synthetic loss into a spectrum signature, using the technique of Fast Fourier Transform to highlight the discrepancies, drawing inspiration from the temporal nature of the imprints, analogous to time-series signals. Across 12 AE attacks including SMACK (USENIX Sec'2023), TRAIT demonstrates consistent outstanding performance across comprehensively evaluated modalities, tasks, datasets, and model architectures. In all scenarios, TRAIT achieves an AE detection accuracy exceeding 97%, often around 99%, while maintaining a false rejection rate of 1%. TRAIT remains effective under the formulated strong adaptive attacks.
Intellectual Property Protection for Deep Learning Model and Dataset Intelligence
Nov 07, 2024
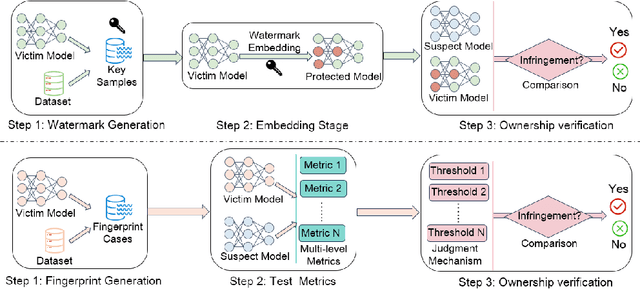


With the growing applications of Deep Learning (DL), especially recent spectacular achievements of Large Language Models (LLMs) such as ChatGPT and LLaMA, the commercial significance of these remarkable models has soared. However, acquiring well-trained models is costly and resource-intensive. It requires a considerable high-quality dataset, substantial investment in dedicated architecture design, expensive computational resources, and efforts to develop technical expertise. Consequently, safeguarding the Intellectual Property (IP) of well-trained models is attracting increasing attention. In contrast to existing surveys overwhelmingly focusing on model IPP mainly, this survey not only encompasses the protection on model level intelligence but also valuable dataset intelligence. Firstly, according to the requirements for effective IPP design, this work systematically summarizes the general and scheme-specific performance evaluation metrics. Secondly, from proactive IP infringement prevention and reactive IP ownership verification perspectives, it comprehensively investigates and analyzes the existing IPP methods for both dataset and model intelligence. Additionally, from the standpoint of training settings, it delves into the unique challenges that distributed settings pose to IPP compared to centralized settings. Furthermore, this work examines various attacks faced by deep IPP techniques. Finally, we outline prospects for promising future directions that may act as a guide for innovative research.
TruVRF: Towards Triple-Granularity Verification on Machine Unlearning
Aug 12, 2024The concept of the right to be forgotten has led to growing interest in machine unlearning, but reliable validation methods are lacking, creating opportunities for dishonest model providers to mislead data contributors. Traditional invasive methods like backdoor injection are not feasible for legacy data. To address this, we introduce TruVRF, a non-invasive unlearning verification framework operating at class-, volume-, and sample-level granularities. TruVRF includes three Unlearning-Metrics designed to detect different types of dishonest servers: Neglecting, Lazy, and Deceiving. Unlearning-Metric-I checks class alignment, Unlearning-Metric-II verifies sample count, and Unlearning-Metric-III confirms specific sample deletion. Evaluations on three datasets show TruVRF's robust performance, with over 90% accuracy for Metrics I and III, and a 4.8% to 8.2% inference deviation for Metric II. TruVRF also demonstrates generalizability and practicality across various conditions and with state-of-the-art unlearning frameworks like SISA and Amnesiac Unlearning.
Decaf: Data Distribution Decompose Attack against Federated Learning
May 24, 2024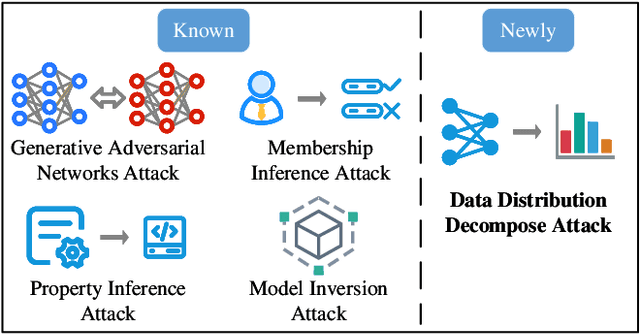
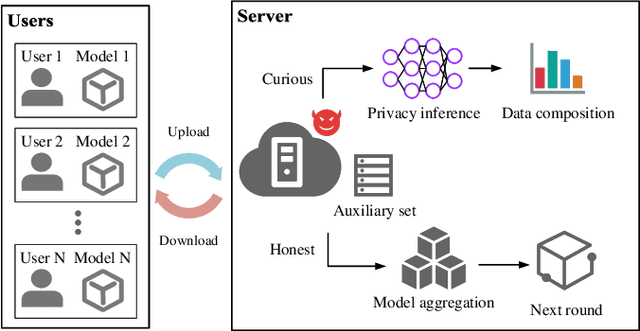
In contrast to prevalent Federated Learning (FL) privacy inference techniques such as generative adversarial networks attacks, membership inference attacks, property inference attacks, and model inversion attacks, we devise an innovative privacy threat: the Data Distribution Decompose Attack on FL, termed Decaf. This attack enables an honest-but-curious FL server to meticulously profile the proportion of each class owned by the victim FL user, divulging sensitive information like local market item distribution and business competitiveness. The crux of Decaf lies in the profound observation that the magnitude of local model gradient changes closely mirrors the underlying data distribution, including the proportion of each class. Decaf addresses two crucial challenges: accurately identify the missing/null class(es) given by any victim user as a premise and then quantify the precise relationship between gradient changes and each remaining non-null class. Notably, Decaf operates stealthily, rendering it entirely passive and undetectable to victim users regarding the infringement of their data distribution privacy. Experimental validation on five benchmark datasets (MNIST, FASHION-MNIST, CIFAR-10, FER-2013, and SkinCancer) employing diverse model architectures, including customized convolutional networks, standardized VGG16, and ResNet18, demonstrates Decaf's efficacy. Results indicate its ability to accurately decompose local user data distribution, regardless of whether it is IID or non-IID distributed. Specifically, the dissimilarity measured using $L_{\infty}$ distance between the distribution decomposed by Decaf and ground truth is consistently below 5\% when no null classes exist. Moreover, Decaf achieves 100\% accuracy in determining any victim user's null classes, validated through formal proof.
Machine Unlearning: Taxonomy, Metrics, Applications, Challenges, and Prospects
Mar 13, 2024Personal digital data is a critical asset, and governments worldwide have enforced laws and regulations to protect data privacy. Data users have been endowed with the right to be forgotten of their data. In the course of machine learning (ML), the forgotten right requires a model provider to delete user data and its subsequent impact on ML models upon user requests. Machine unlearning emerges to address this, which has garnered ever-increasing attention from both industry and academia. While the area has developed rapidly, there is a lack of comprehensive surveys to capture the latest advancements. Recognizing this shortage, we conduct an extensive exploration to map the landscape of machine unlearning including the (fine-grained) taxonomy of unlearning algorithms under centralized and distributed settings, debate on approximate unlearning, verification and evaluation metrics, challenges and solutions for unlearning under different applications, as well as attacks targeting machine unlearning. The survey concludes by outlining potential directions for future research, hoping to serve as a guide for interested scholars.
Vertical Federated Learning: Taxonomies, Threats, and Prospects
Feb 03, 2023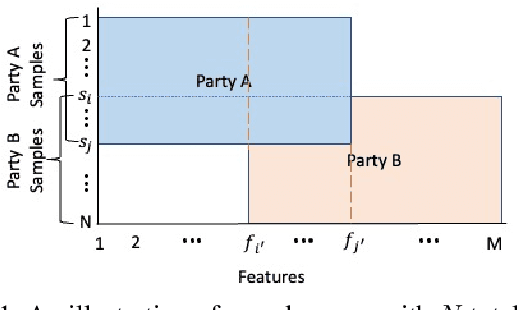
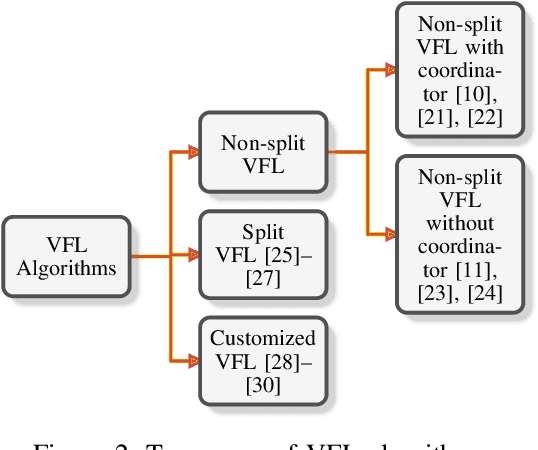
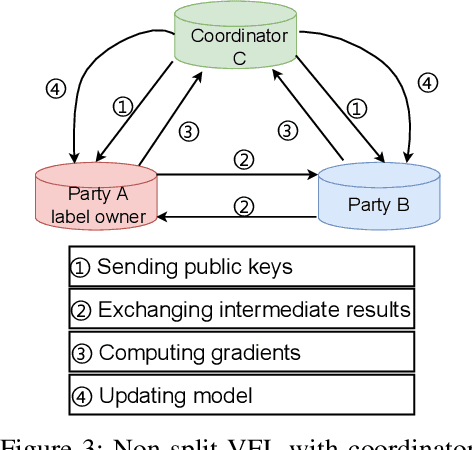

Federated learning (FL) is the most popular distributed machine learning technique. FL allows machine-learning models to be trained without acquiring raw data to a single point for processing. Instead, local models are trained with local data; the models are then shared and combined. This approach preserves data privacy as locally trained models are shared instead of the raw data themselves. Broadly, FL can be divided into horizontal federated learning (HFL) and vertical federated learning (VFL). For the former, different parties hold different samples over the same set of features; for the latter, different parties hold different feature data belonging to the same set of samples. In a number of practical scenarios, VFL is more relevant than HFL as different companies (e.g., bank and retailer) hold different features (e.g., credit history and shopping history) for the same set of customers. Although VFL is an emerging area of research, it is not well-established compared to HFL. Besides, VFL-related studies are dispersed, and their connections are not intuitive. Thus, this survey aims to bring these VFL-related studies to one place. Firstly, we classify existing VFL structures and algorithms. Secondly, we present the threats from security and privacy perspectives to VFL. Thirdly, for the benefit of future researchers, we discussed the challenges and prospects of VFL in detail.
MACAB: Model-Agnostic Clean-Annotation Backdoor to Object Detection with Natural Trigger in Real-World
Sep 06, 2022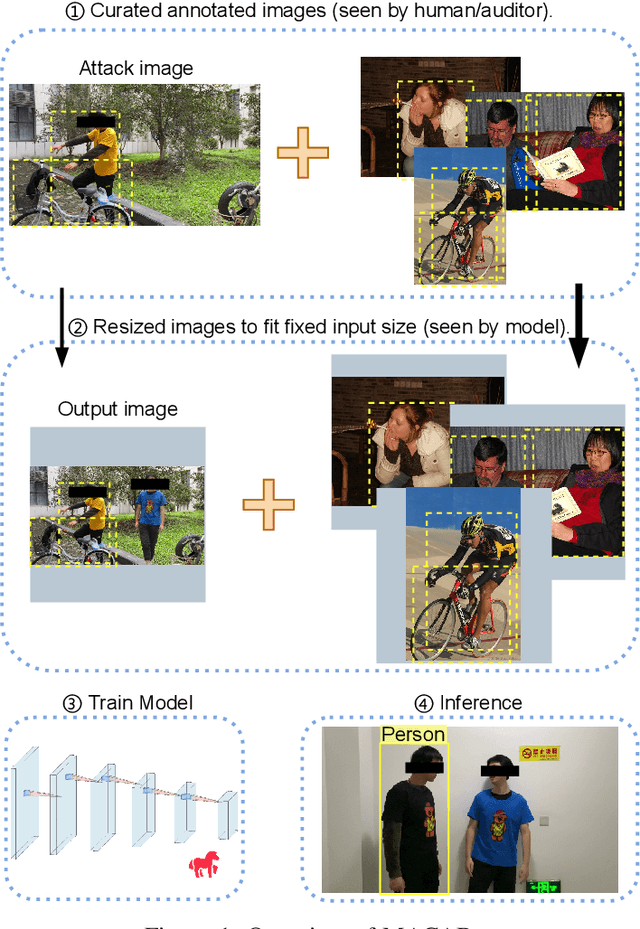
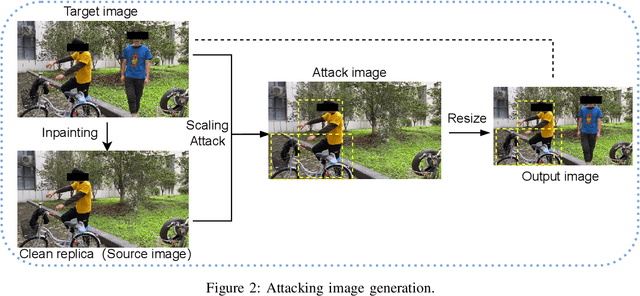


Object detection is the foundation of various critical computer-vision tasks such as segmentation, object tracking, and event detection. To train an object detector with satisfactory accuracy, a large amount of data is required. However, due to the intensive workforce involved with annotating large datasets, such a data curation task is often outsourced to a third party or relied on volunteers. This work reveals severe vulnerabilities of such data curation pipeline. We propose MACAB that crafts clean-annotated images to stealthily implant the backdoor into the object detectors trained on them even when the data curator can manually audit the images. We observe that the backdoor effect of both misclassification and the cloaking are robustly achieved in the wild when the backdoor is activated with inconspicuously natural physical triggers. Backdooring non-classification object detection with clean-annotation is challenging compared to backdooring existing image classification tasks with clean-label, owing to the complexity of having multiple objects within each frame, including victim and non-victim objects. The efficacy of the MACAB is ensured by constructively i abusing the image-scaling function used by the deep learning framework, ii incorporating the proposed adversarial clean image replica technique, and iii combining poison data selection criteria given constrained attacking budget. Extensive experiments demonstrate that MACAB exhibits more than 90% attack success rate under various real-world scenes. This includes both cloaking and misclassification backdoor effect even restricted with a small attack budget. The poisoned samples cannot be effectively identified by state-of-the-art detection techniques.The comprehensive video demo is at https://youtu.be/MA7L_LpXkp4, which is based on a poison rate of 0.14% for YOLOv4 cloaking backdoor and Faster R-CNN misclassification backdoor.