 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMACAB: Model-Agnostic Clean-Annotation Backdoor to Object Detection with Natural Trigger in Real-World
Sep 06, 2022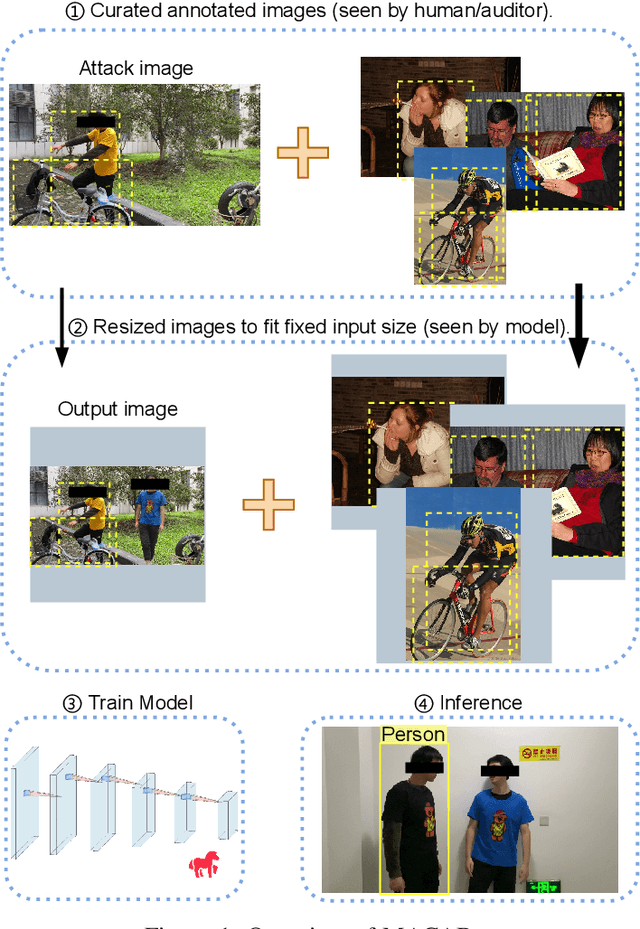
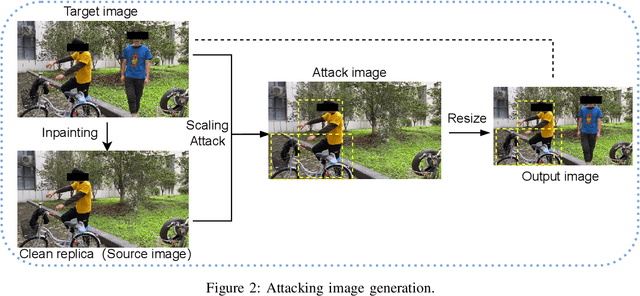


Object detection is the foundation of various critical computer-vision tasks such as segmentation, object tracking, and event detection. To train an object detector with satisfactory accuracy, a large amount of data is required. However, due to the intensive workforce involved with annotating large datasets, such a data curation task is often outsourced to a third party or relied on volunteers. This work reveals severe vulnerabilities of such data curation pipeline. We propose MACAB that crafts clean-annotated images to stealthily implant the backdoor into the object detectors trained on them even when the data curator can manually audit the images. We observe that the backdoor effect of both misclassification and the cloaking are robustly achieved in the wild when the backdoor is activated with inconspicuously natural physical triggers. Backdooring non-classification object detection with clean-annotation is challenging compared to backdooring existing image classification tasks with clean-label, owing to the complexity of having multiple objects within each frame, including victim and non-victim objects. The efficacy of the MACAB is ensured by constructively i abusing the image-scaling function used by the deep learning framework, ii incorporating the proposed adversarial clean image replica technique, and iii combining poison data selection criteria given constrained attacking budget. Extensive experiments demonstrate that MACAB exhibits more than 90% attack success rate under various real-world scenes. This includes both cloaking and misclassification backdoor effect even restricted with a small attack budget. The poisoned samples cannot be effectively identified by state-of-the-art detection techniques.The comprehensive video demo is at https://youtu.be/MA7L_LpXkp4, which is based on a poison rate of 0.14% for YOLOv4 cloaking backdoor and Faster R-CNN misclassification backdoor.
Dangerous Cloaking: Natural Trigger based Backdoor Attacks on Object Detectors in the Physical World
Jan 21, 2022
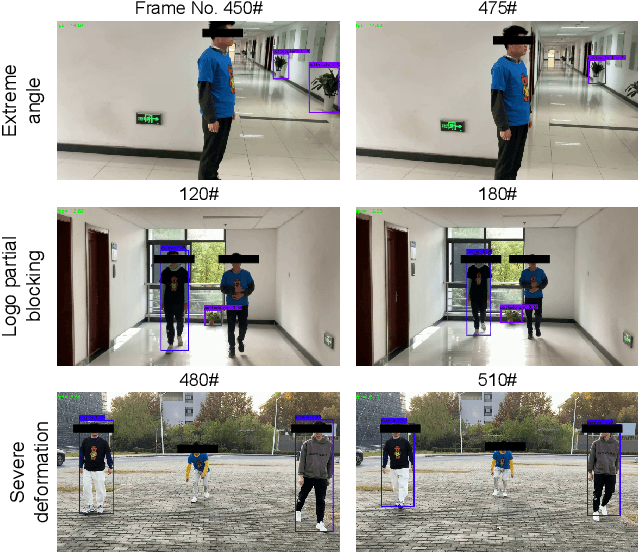

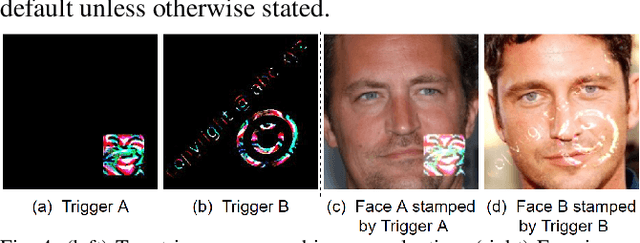
Deep learning models have been shown to be vulnerable to recent backdoor attacks. A backdoored model behaves normally for inputs containing no attacker-secretly-chosen trigger and maliciously for inputs with the trigger. To date, backdoor attacks and countermeasures mainly focus on image classification tasks. And most of them are implemented in the digital world with digital triggers. Besides the classification tasks, object detection systems are also considered as one of the basic foundations of computer vision tasks. However, there is no investigation and understanding of the backdoor vulnerability of the object detector, even in the digital world with digital triggers. For the first time, this work demonstrates that existing object detectors are inherently susceptible to physical backdoor attacks. We use a natural T-shirt bought from a market as a trigger to enable the cloaking effect--the person bounding-box disappears in front of the object detector. We show that such a backdoor can be implanted from two exploitable attack scenarios into the object detector, which is outsourced or fine-tuned through a pretrained model. We have extensively evaluated three popular object detection algorithms: anchor-based Yolo-V3, Yolo-V4, and anchor-free CenterNet. Building upon 19 videos shot in real-world scenes, we confirm that the backdoor attack is robust against various factors: movement, distance, angle, non-rigid deformation, and lighting. Specifically, the attack success rate (ASR) in most videos is 100% or close to it, while the clean data accuracy of the backdoored model is the same as its clean counterpart. The latter implies that it is infeasible to detect the backdoor behavior merely through a validation set. The averaged ASR still remains sufficiently high to be 78% in the transfer learning attack scenarios evaluated on CenterNet. See the demo video on https://youtu.be/Q3HOF4OobbY.
NTD: Non-Transferability Enabled Backdoor Detection
Nov 22, 2021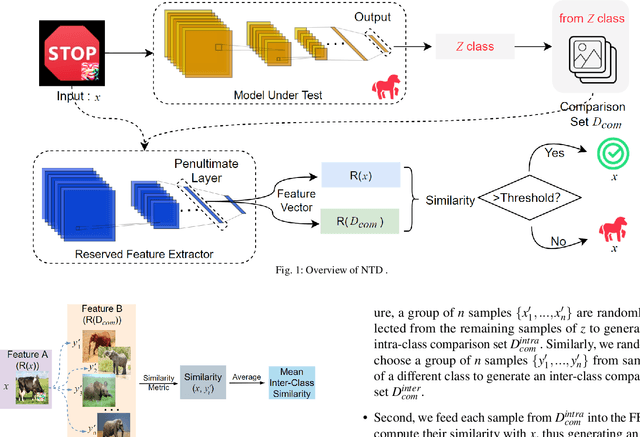

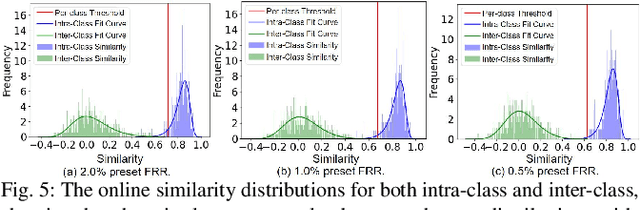
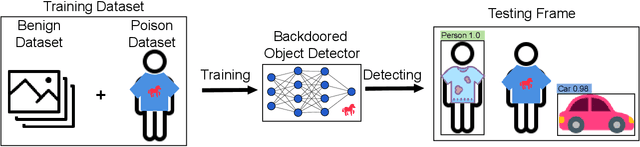
A backdoor deep learning (DL) model behaves normally upon clean inputs but misbehaves upon trigger inputs as the backdoor attacker desires, posing severe consequences to DL model deployments. State-of-the-art defenses are either limited to specific backdoor attacks (source-agnostic attacks) or non-user-friendly in that machine learning (ML) expertise or expensive computing resources are required. This work observes that all existing backdoor attacks have an inevitable intrinsic weakness, non-transferability, that is, a trigger input hijacks a backdoored model but cannot be effective to another model that has not been implanted with the same backdoor. With this key observation, we propose non-transferability enabled backdoor detection (NTD) to identify trigger inputs for a model-under-test (MUT) during run-time.Specifically, NTD allows a potentially backdoored MUT to predict a class for an input. In the meantime, NTD leverages a feature extractor (FE) to extract feature vectors for the input and a group of samples randomly picked from its predicted class, and then compares similarity between the input and the samples in the FE's latent space. If the similarity is low, the input is an adversarial trigger input; otherwise, benign. The FE is a free pre-trained model privately reserved from open platforms. As the FE and MUT are from different sources, the attacker is very unlikely to insert the same backdoor into both of them. Because of non-transferability, a trigger effect that does work on the MUT cannot be transferred to the FE, making NTD effective against different types of backdoor attacks. We evaluate NTD on three popular customized tasks such as face recognition, traffic sign recognition and general animal classification, results of which affirm that NDT has high effectiveness (low false acceptance rate) and usability (low false rejection rate) with low detection latency.