 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPT-Agent: Automated Penetration Testing using Large Language Models
May 24, 2026Penetration testing is essential to securing modern web infrastructures, yet traditional manual methods struggle to keep pace with their scale and complexity. Large Language Models (LLMs) offer new opportunities for automating these tasks, but existing approaches face two persistent challenges: hallucination of technical entities and insufficient long-term contextual memory. To address these issues, we present APT-Agent, a fully automated LLM-driven penetration testing framework that systematically orchestrates reconnaissance, exploitation, and exfiltration. APT-Agent introduces a hybrid rectification module to recover hallucinated commands and a command-specific memory architecture to preserve operational context across multi-step attack sequences. We evaluate our APT-Agent on Metasploitable 2 against seven vulnerable services spanning web, database, and network protocols. APT-Agent achieves an 84.29% end-to-end exploitation success rate, compared to 48.57% (Script Kiddie) and 18.57% (PentestGPT) under matched conditions. By reducing cognitive burden and minimizing reliance on human intervention, APT-Agent represents a step toward scalable, reliable, and cognitively efficient automation for penetration testing.
Human Society-Inspired Approaches to Agentic AI Security: The 4C Framework
Feb 02, 2026AI is moving from domain-specific autonomy in closed, predictable settings to large-language-model-driven agents that plan and act in open, cross-organizational environments. As a result, the cybersecurity risk landscape is changing in fundamental ways. Agentic AI systems can plan, act, collaborate, and persist over time, functioning as participants in complex socio-technical ecosystems rather than as isolated software components. Although recent work has strengthened defenses against model and pipeline level vulnerabilities such as prompt injection, data poisoning, and tool misuse, these system centric approaches may fail to capture risks that arise from autonomy, interaction, and emergent behavior. This article introduces the 4C Framework for multi-agent AI security, inspired by societal governance. It organizes agentic risks across four interdependent dimensions: Core (system, infrastructure, and environmental integrity), Connection (communication, coordination, and trust), Cognition (belief, goal, and reasoning integrity), and Compliance (ethical, legal, and institutional governance). By shifting AI security from a narrow focus on system-centric protection to the broader preservation of behavioral integrity and intent, the framework complements existing AI security strategies and offers a principled foundation for building agentic AI systems that are trustworthy, governable, and aligned with human values.
Adversarial Attacks Against Automated Fact-Checking: A Survey
Sep 10, 2025In an era where misinformation spreads freely, fact-checking (FC) plays a crucial role in verifying claims and promoting reliable information. While automated fact-checking (AFC) has advanced significantly, existing systems remain vulnerable to adversarial attacks that manipulate or generate claims, evidence, or claim-evidence pairs. These attacks can distort the truth, mislead decision-makers, and ultimately undermine the reliability of FC models. Despite growing research interest in adversarial attacks against AFC systems, a comprehensive, holistic overview of key challenges remains lacking. These challenges include understanding attack strategies, assessing the resilience of current models, and identifying ways to enhance robustness. This survey provides the first in-depth review of adversarial attacks targeting FC, categorizing existing attack methodologies and evaluating their impact on AFC systems. Additionally, we examine recent advancements in adversary-aware defenses and highlight open research questions that require further exploration. Our findings underscore the urgent need for resilient FC frameworks capable of withstanding adversarial manipulations in pursuit of preserving high verification accuracy.
LLMs Are Not Yet Ready for Deepfake Image Detection
Jun 12, 2025



The growing sophistication of deepfakes presents substantial challenges to the integrity of media and the preservation of public trust. Concurrently, vision-language models (VLMs), large language models enhanced with visual reasoning capabilities, have emerged as promising tools across various domains, sparking interest in their applicability to deepfake detection. This study conducts a structured zero-shot evaluation of four prominent VLMs: ChatGPT, Claude, Gemini, and Grok, focusing on three primary deepfake types: faceswap, reenactment, and synthetic generation. Leveraging a meticulously assembled benchmark comprising authentic and manipulated images from diverse sources, we evaluate each model's classification accuracy and reasoning depth. Our analysis indicates that while VLMs can produce coherent explanations and detect surface-level anomalies, they are not yet dependable as standalone detection systems. We highlight critical failure modes, such as an overemphasis on stylistic elements and vulnerability to misleading visual patterns like vintage aesthetics. Nevertheless, VLMs exhibit strengths in interpretability and contextual analysis, suggesting their potential to augment human expertise in forensic workflows. These insights imply that although general-purpose models currently lack the reliability needed for autonomous deepfake detection, they hold promise as integral components in hybrid or human-in-the-loop detection frameworks.
What is the Cost of Differential Privacy for Deep Learning-Based Trajectory Generation?
Jun 11, 2025While location trajectories offer valuable insights, they also reveal sensitive personal information. Differential Privacy (DP) offers formal protection, but achieving a favourable utility-privacy trade-off remains challenging. Recent works explore deep learning-based generative models to produce synthetic trajectories. However, current models lack formal privacy guarantees and rely on conditional information derived from real data during generation. This work investigates the utility cost of enforcing DP in such models, addressing three research questions across two datasets and eleven utility metrics. (1) We evaluate how DP-SGD, the standard DP training method for deep learning, affects the utility of state-of-the-art generative models. (2) Since DP-SGD is limited to unconditional models, we propose a novel DP mechanism for conditional generation that provides formal guarantees and assess its impact on utility. (3) We analyse how model types - Diffusion, VAE, and GAN - affect the utility-privacy trade-off. Our results show that DP-SGD significantly impacts performance, although some utility remains if the datasets is sufficiently large. The proposed DP mechanism improves training stability, particularly when combined with DP-SGD, for unstable models such as GANs and on smaller datasets. Diffusion models yield the best utility without guarantees, but with DP-SGD, GANs perform best, indicating that the best non-private model is not necessarily optimal when targeting formal guarantees. In conclusion, DP trajectory generation remains a challenging task, and formal guarantees are currently only feasible with large datasets and in constrained use cases.
H-FLTN: A Privacy-Preserving Hierarchical Framework for Electric Vehicle Spatio-Temporal Charge Prediction
Feb 25, 2025The widespread adoption of Electric Vehicles (EVs) poses critical challenges for energy providers, particularly in predicting charging time (temporal prediction), ensuring user privacy, and managing resources efficiently in mobility-driven networks. This paper introduces the Hierarchical Federated Learning Transformer Network (H-FLTN) framework to address these challenges. H-FLTN employs a three-tier hierarchical architecture comprising EVs, community Distributed Energy Resource Management Systems (DERMS), and the Energy Provider Data Centre (EPDC) to enable accurate spatio-temporal predictions of EV charging needs while preserving privacy. Temporal prediction is enhanced using Transformer-based learning, capturing complex dependencies in charging behavior. Privacy is ensured through Secure Aggregation, Additive Secret Sharing, and Peer-to-Peer (P2P) Sharing with Augmentation, which allow only secret shares of model weights to be exchanged while securing all transmissions. To improve training efficiency and resource management, H-FLTN integrates Dynamic Client Capping Mechanism (DCCM) and Client Rotation Management (CRM), ensuring that training remains both computationally and temporally efficient as the number of participating EVs increases. DCCM optimises client participation by limiting excessive computational loads, while CRM balances training contributions across epochs, preventing imbalanced participation. Our simulation results based on large-scale empirical vehicle mobility data reveal that DCCM and CRM reduce the training time complexity with increasing EVs from linear to constant. Its integration into real-world smart city infrastructure enhances energy demand forecasting, resource allocation, and grid stability, ensuring reliability and sustainability in future mobility ecosystems.
ThreatModeling-LLM: Automating Threat Modeling using Large Language Models for Banking System
Nov 26, 2024



Threat modeling is a crucial component of cybersecurity, particularly for industries such as banking, where the security of financial data is paramount. Traditional threat modeling approaches require expert intervention and manual effort, often leading to inefficiencies and human error. The advent of Large Language Models (LLMs) offers a promising avenue for automating these processes, enhancing both efficiency and efficacy. However, this transition is not straightforward due to three main challenges: (1) the lack of publicly available, domain-specific datasets, (2) the need for tailored models to handle complex banking system architectures, and (3) the requirement for real-time, adaptive mitigation strategies that align with compliance standards like NIST 800-53. In this paper, we introduce ThreatModeling-LLM, a novel and adaptable framework that automates threat modeling for banking systems using LLMs. ThreatModeling-LLM operates in three stages: 1) dataset creation, 2) prompt engineering and 3) model fine-tuning. We first generate a benchmark dataset using Microsoft Threat Modeling Tool (TMT). Then, we apply Chain of Thought (CoT) and Optimization by PROmpting (OPRO) on the pre-trained LLMs to optimize the initial prompt. Lastly, we fine-tune the LLM using Low-Rank Adaptation (LoRA) based on the benchmark dataset and the optimized prompt to improve the threat identification and mitigation generation capabilities of pre-trained LLMs.
A Constraint-Enforcing Reward for Adversarial Attacks on Text Classifiers
May 20, 2024Text classifiers are vulnerable to adversarial examples -- correctly-classified examples that are deliberately transformed to be misclassified while satisfying acceptability constraints. The conventional approach to finding adversarial examples is to define and solve a combinatorial optimisation problem over a space of allowable transformations. While effective, this approach is slow and limited by the choice of transformations. An alternate approach is to directly generate adversarial examples by fine-tuning a pre-trained language model, as is commonly done for other text-to-text tasks. This approach promises to be much quicker and more expressive, but is relatively unexplored. For this reason, in this work we train an encoder-decoder paraphrase model to generate a diverse range of adversarial examples. For training, we adopt a reinforcement learning algorithm and propose a constraint-enforcing reward that promotes the generation of valid adversarial examples. Experimental results over two text classification datasets show that our model has achieved a higher success rate than the original paraphrase model, and overall has proved more effective than other competitive attacks. Finally, we show how key design choices impact the generated examples and discuss the strengths and weaknesses of the proposed approach.
An Investigation into Misuse of Java Security APIs by Large Language Models
Apr 04, 2024



The increasing trend of using Large Language Models (LLMs) for code generation raises the question of their capability to generate trustworthy code. While many researchers are exploring the utility of code generation for uncovering software vulnerabilities, one crucial but often overlooked aspect is the security Application Programming Interfaces (APIs). APIs play an integral role in upholding software security, yet effectively integrating security APIs presents substantial challenges. This leads to inadvertent misuse by developers, thereby exposing software to vulnerabilities. To overcome these challenges, developers may seek assistance from LLMs. In this paper, we systematically assess ChatGPT's trustworthiness in code generation for security API use cases in Java. To conduct a thorough evaluation, we compile an extensive collection of 48 programming tasks for 5 widely used security APIs. We employ both automated and manual approaches to effectively detect security API misuse in the code generated by ChatGPT for these tasks. Our findings are concerning: around 70% of the code instances across 30 attempts per task contain security API misuse, with 20 distinct misuse types identified. Moreover, for roughly half of the tasks, this rate reaches 100%, indicating that there is a long way to go before developers can rely on ChatGPT to securely implement security API code.
SoK: Can Trajectory Generation Combine Privacy and Utility?
Mar 12, 2024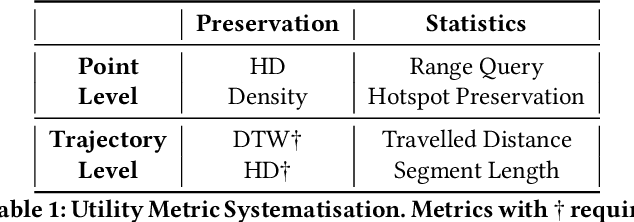
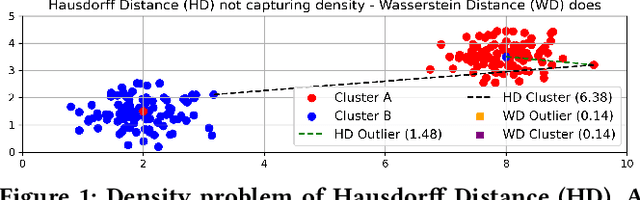
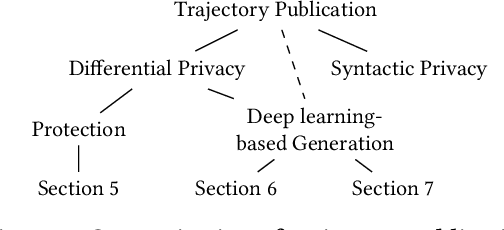
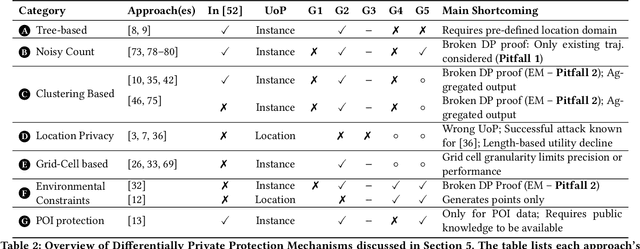
While location trajectories represent a valuable data source for analyses and location-based services, they can reveal sensitive information, such as political and religious preferences. Differentially private publication mechanisms have been proposed to allow for analyses under rigorous privacy guarantees. However, the traditional protection schemes suffer from a limiting privacy-utility trade-off and are vulnerable to correlation and reconstruction attacks. Synthetic trajectory data generation and release represent a promising alternative to protection algorithms. While initial proposals achieve remarkable utility, they fail to provide rigorous privacy guarantees. This paper proposes a framework for designing a privacy-preserving trajectory publication approach by defining five design goals, particularly stressing the importance of choosing an appropriate Unit of Privacy. Based on this framework, we briefly discuss the existing trajectory protection approaches, emphasising their shortcomings. This work focuses on the systematisation of the state-of-the-art generative models for trajectories in the context of the proposed framework. We find that no existing solution satisfies all requirements. Thus, we perform an experimental study evaluating the applicability of six sequential generative models to the trajectory domain. Finally, we conclude that a generative trajectory model providing semantic guarantees remains an open research question and propose concrete next steps for future research.