 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulVuln: Enhancing Pre-trained LMs with Shared and Language-Specific Knowledge for Multilingual Vulnerability Detection
Oct 05, 2025Software vulnerabilities (SVs) pose a critical threat to safety-critical systems, driving the adoption of AI-based approaches such as machine learning and deep learning for software vulnerability detection. Despite promising results, most existing methods are limited to a single programming language. This is problematic given the multilingual nature of modern software, which is often complex and written in multiple languages. Current approaches often face challenges in capturing both shared and language-specific knowledge of source code, which can limit their performance on diverse programming languages and real-world codebases. To address this gap, we propose MULVULN, a novel multilingual vulnerability detection approach that learns from source code across multiple languages. MULVULN captures both the shared knowledge that generalizes across languages and the language-specific knowledge that reflects unique coding conventions. By integrating these aspects, it achieves more robust and effective detection of vulnerabilities in real-world multilingual software systems. The rigorous and extensive experiments on the real-world and diverse REEF dataset, consisting of 4,466 CVEs with 30,987 patches across seven programming languages, demonstrate the superiority of MULVULN over thirteen effective and state-of-the-art baselines. Notably, MULVULN achieves substantially higher F1-score, with improvements ranging from 1.45% to 23.59% compared to the baseline methods.
LLMs Are Not Yet Ready for Deepfake Image Detection
Jun 12, 2025



The growing sophistication of deepfakes presents substantial challenges to the integrity of media and the preservation of public trust. Concurrently, vision-language models (VLMs), large language models enhanced with visual reasoning capabilities, have emerged as promising tools across various domains, sparking interest in their applicability to deepfake detection. This study conducts a structured zero-shot evaluation of four prominent VLMs: ChatGPT, Claude, Gemini, and Grok, focusing on three primary deepfake types: faceswap, reenactment, and synthetic generation. Leveraging a meticulously assembled benchmark comprising authentic and manipulated images from diverse sources, we evaluate each model's classification accuracy and reasoning depth. Our analysis indicates that while VLMs can produce coherent explanations and detect surface-level anomalies, they are not yet dependable as standalone detection systems. We highlight critical failure modes, such as an overemphasis on stylistic elements and vulnerability to misleading visual patterns like vintage aesthetics. Nevertheless, VLMs exhibit strengths in interpretability and contextual analysis, suggesting their potential to augment human expertise in forensic workflows. These insights imply that although general-purpose models currently lack the reliability needed for autonomous deepfake detection, they hold promise as integral components in hybrid or human-in-the-loop detection frameworks.
ThreatModeling-LLM: Automating Threat Modeling using Large Language Models for Banking System
Nov 26, 2024



Threat modeling is a crucial component of cybersecurity, particularly for industries such as banking, where the security of financial data is paramount. Traditional threat modeling approaches require expert intervention and manual effort, often leading to inefficiencies and human error. The advent of Large Language Models (LLMs) offers a promising avenue for automating these processes, enhancing both efficiency and efficacy. However, this transition is not straightforward due to three main challenges: (1) the lack of publicly available, domain-specific datasets, (2) the need for tailored models to handle complex banking system architectures, and (3) the requirement for real-time, adaptive mitigation strategies that align with compliance standards like NIST 800-53. In this paper, we introduce ThreatModeling-LLM, a novel and adaptable framework that automates threat modeling for banking systems using LLMs. ThreatModeling-LLM operates in three stages: 1) dataset creation, 2) prompt engineering and 3) model fine-tuning. We first generate a benchmark dataset using Microsoft Threat Modeling Tool (TMT). Then, we apply Chain of Thought (CoT) and Optimization by PROmpting (OPRO) on the pre-trained LLMs to optimize the initial prompt. Lastly, we fine-tune the LLM using Low-Rank Adaptation (LoRA) based on the benchmark dataset and the optimized prompt to improve the threat identification and mitigation generation capabilities of pre-trained LLMs.
Copyright Protection and Accountability of Generative AI:Attack, Watermarking and Attribution
Mar 15, 2023



Generative AI (e.g., Generative Adversarial Networks - GANs) has become increasingly popular in recent years. However, Generative AI introduces significant concerns regarding the protection of Intellectual Property Rights (IPR) (resp. model accountability) pertaining to images (resp. toxic images) and models (resp. poisoned models) generated. In this paper, we propose an evaluation framework to provide a comprehensive overview of the current state of the copyright protection measures for GANs, evaluate their performance across a diverse range of GAN architectures, and identify the factors that affect their performance and future research directions. Our findings indicate that the current IPR protection methods for input images, model watermarking, and attribution networks are largely satisfactory for a wide range of GANs. We highlight that further attention must be directed towards protecting training sets, as the current approaches fail to provide robust IPR protection and provenance tracing on training sets.
Profiler: Profile-Based Model to Detect Phishing Emails
Aug 18, 2022
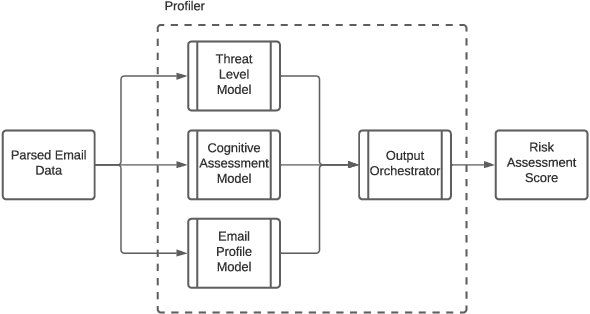
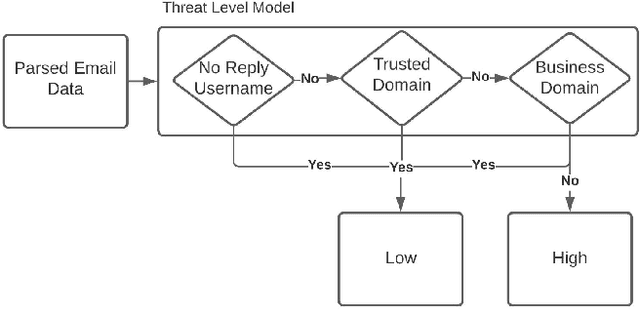
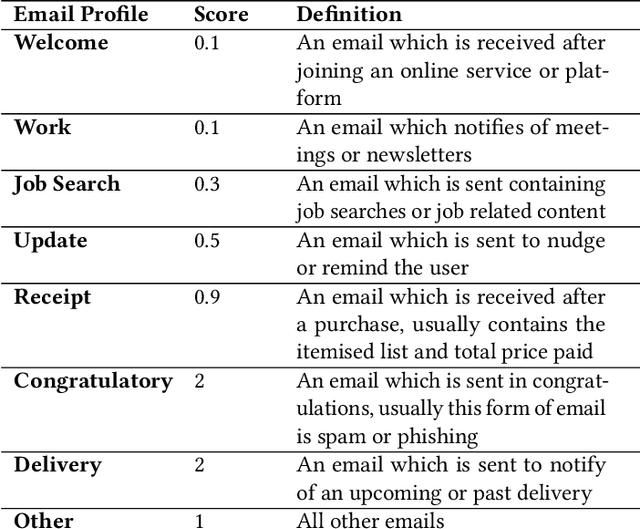
Email phishing has become more prevalent and grows more sophisticated over time. To combat this rise, many machine learning (ML) algorithms for detecting phishing emails have been developed. However, due to the limited email data sets on which these algorithms train, they are not adept at recognising varied attacks and, thus, suffer from concept drift; attackers can introduce small changes in the statistical characteristics of their emails or websites to successfully bypass detection. Over time, a gap develops between the reported accuracy from literature and the algorithm's actual effectiveness in the real world. This realises itself in frequent false positive and false negative classifications. To this end, we propose a multidimensional risk assessment of emails to reduce the feasibility of an attacker adapting their email and avoiding detection. This horizontal approach to email phishing detection profiles an incoming email on its main features. We develop a risk assessment framework that includes three models which analyse an email's (1) threat level, (2) cognitive manipulation, and (3) email type, which we combine to return the final risk assessment score. The Profiler does not require large data sets to train on to be effective and its analysis of varied email features reduces the impact of concept drift. Our Profiler can be used in conjunction with ML approaches, to reduce their misclassifications or as a labeller for large email data sets in the training stage. We evaluate the efficacy of the Profiler against a machine learning ensemble using state-of-the-art ML algorithms on a data set of 9000 legitimate and 900 phishing emails from a large Australian research organisation. Our results indicate that the Profiler's mitigates the impact of concept drift, and delivers 30% less false positive and 25% less false negative email classifications over the ML ensemble's approach.
* 12 pages
Email Summarization to Assist Users in Phishing Identification
Mar 24, 2022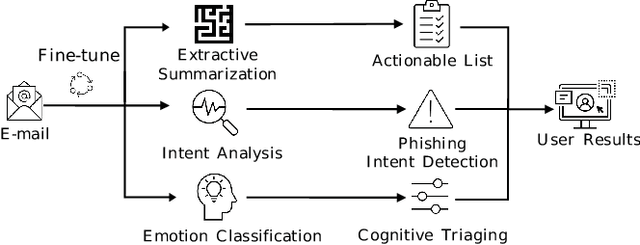

Cyber-phishing attacks recently became more precise, targeted, and tailored by training data to activate only in the presence of specific information or cues. They are adaptable to a much greater extent than traditional phishing detection. Hence, automated detection systems cannot always be 100% accurate, increasing the uncertainty around expected behavior when faced with a potential phishing email. On the other hand, human-centric defence approaches focus extensively on user training but face the difficulty of keeping users up to date with continuously emerging patterns. Therefore, advances in analyzing the content of an email in novel ways along with summarizing the most pertinent content to the recipients of emails is a prospective gateway to furthering how to combat these threats. Addressing this gap, this work leverages transformer-based machine learning to (i) analyze prospective psychological triggers, to (ii) detect possible malicious intent, and (iii) create representative summaries of emails. We then amalgamate this information and present it to the user to allow them to (i) easily decide whether the email is "phishy" and (ii) self-learn advanced malicious patterns.
RAIDER: Reinforcement-aided Spear Phishing Detector
May 17, 2021



Spear Phishing is a harmful cyber-attack facing business and individuals worldwide. Considerable research has been conducted recently into the use of Machine Learning (ML) techniques to detect spear-phishing emails. ML-based solutions may suffer from zero-day attacks; unseen attacks unaccounted for in the training data. As new attacks emerge, classifiers trained on older data are unable to detect these new varieties of attacks resulting in increasingly inaccurate predictions. Spear Phishing detection also faces scalability challenges due to the growth of the required features which is proportional to the number of the senders within a receiver mailbox. This differs from traditional phishing attacks which typically perform only a binary classification between phishing and benign emails. Therefore, we devise a possible solution to these problems, named RAIDER: Reinforcement AIded Spear Phishing DEtectoR. A reinforcement-learning based feature evaluation system that can automatically find the optimum features for detecting different types of attacks. By leveraging a reward and penalty system, RAIDER allows for autonomous features selection. RAIDER also keeps the number of features to a minimum by selecting only the significant features to represent phishing emails and detect spear-phishing attacks. After extensive evaluation of RAIDER over 11,000 emails and across 3 attack scenarios, our results suggest that using reinforcement learning to automatically identify the significant features could reduce the dimensions of the required features by 55% in comparison to existing ML-based systems. It also improves the accuracy of detecting spoofing attacks by 4% from 90% to 94%. In addition, RAIDER demonstrates reasonable detection accuracy even against a sophisticated attack named Known Sender in which spear-phishing emails greatly resemble those of the impersonated sender.