 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Prediction to Explanation: Multimodal, Explainable, and Interactive Deepfake Detection Framework for Non-Expert Users
Aug 11, 2025The proliferation of deepfake technologies poses urgent challenges and serious risks to digital integrity, particularly within critical sectors such as forensics, journalism, and the legal system. While existing detection systems have made significant progress in classification accuracy, they typically function as black-box models, offering limited transparency and minimal support for human reasoning. This lack of interpretability hinders their usability in real-world decision-making contexts, especially for non-expert users. In this paper, we present DF-P2E (Deepfake: Prediction to Explanation), a novel multimodal framework that integrates visual, semantic, and narrative layers of explanation to make deepfake detection interpretable and accessible. The framework consists of three modular components: (1) a deepfake classifier with Grad-CAM-based saliency visualisation, (2) a visual captioning module that generates natural language summaries of manipulated regions, and (3) a narrative refinement module that uses a fine-tuned Large Language Model (LLM) to produce context-aware, user-sensitive explanations. We instantiate and evaluate the framework on the DF40 benchmark, the most diverse deepfake dataset to date. Experiments demonstrate that our system achieves competitive detection performance while providing high-quality explanations aligned with Grad-CAM activations. By unifying prediction and explanation in a coherent, human-aligned pipeline, this work offers a scalable approach to interpretable deepfake detection, advancing the broader vision of trustworthy and transparent AI systems in adversarial media environments.
LLMs Are Not Yet Ready for Deepfake Image Detection
Jun 12, 2025



The growing sophistication of deepfakes presents substantial challenges to the integrity of media and the preservation of public trust. Concurrently, vision-language models (VLMs), large language models enhanced with visual reasoning capabilities, have emerged as promising tools across various domains, sparking interest in their applicability to deepfake detection. This study conducts a structured zero-shot evaluation of four prominent VLMs: ChatGPT, Claude, Gemini, and Grok, focusing on three primary deepfake types: faceswap, reenactment, and synthetic generation. Leveraging a meticulously assembled benchmark comprising authentic and manipulated images from diverse sources, we evaluate each model's classification accuracy and reasoning depth. Our analysis indicates that while VLMs can produce coherent explanations and detect surface-level anomalies, they are not yet dependable as standalone detection systems. We highlight critical failure modes, such as an overemphasis on stylistic elements and vulnerability to misleading visual patterns like vintage aesthetics. Nevertheless, VLMs exhibit strengths in interpretability and contextual analysis, suggesting their potential to augment human expertise in forensic workflows. These insights imply that although general-purpose models currently lack the reliability needed for autonomous deepfake detection, they hold promise as integral components in hybrid or human-in-the-loop detection frameworks.
Exploring the Impact of Moire Pattern on Deepfake Detectors
Jul 15, 2024



Deepfake detection is critical in mitigating the societal threats posed by manipulated videos. While various algorithms have been developed for this purpose, challenges arise when detectors operate externally, such as on smartphones, when users take a photo of deepfake images and upload on the Internet. One significant challenge in such scenarios is the presence of Moir\'e patterns, which degrade image quality and confound conventional classification algorithms, including deep neural networks (DNNs). The impact of Moir\'e patterns remains largely unexplored for deepfake detectors. In this study, we investigate how camera-captured deepfake videos from digital screens affect detector performance. We conducted experiments using two prominent datasets, CelebDF and FF++, comparing the performance of four state-of-the-art detectors on camera-captured deepfake videos with introduced Moir\'e patterns. Our findings reveal a significant decline in detector accuracy, with none achieving above 68% on average. This underscores the critical need to address Moir\'e pattern challenges in real-world deepfake detection scenarios.
A2C: A Modular Multi-stage Collaborative Decision Framework for Human-AI Teams
Jan 25, 2024This paper introduces A2C, a multi-stage collaborative decision framework designed to enable robust decision-making within human-AI teams. Drawing inspiration from concepts such as rejection learning and learning to defer, A2C incorporates AI systems trained to recognise uncertainty in their decisions and defer to human experts when needed. Moreover, A2C caters to scenarios where even human experts encounter limitations, such as in incident detection and response in cyber Security Operations Centres (SOC). In such scenarios, A2C facilitates collaborative explorations, enabling collective resolution of complex challenges. With support for three distinct decision-making modes in human-AI teams: Automated, Augmented, and Collaborative, A2C offers a flexible platform for developing effective strategies for human-AI collaboration. By harnessing the strengths of both humans and AI, it significantly improves the efficiency and effectiveness of complex decision-making in dynamic and evolving environments. To validate A2C's capabilities, we conducted extensive simulative experiments using benchmark datasets. The results clearly demonstrate that all three modes of decision-making can be effectively supported by A2C. Most notably, collaborative exploration by (simulated) human experts and AI achieves superior performance compared to AI in isolation, underscoring the framework's potential to enhance decision-making within human-AI teams.
SoK: Facial Deepfake Detectors
Jan 09, 2024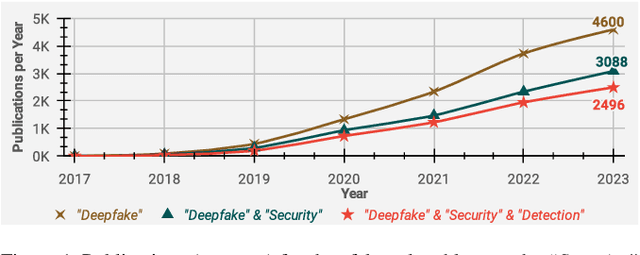

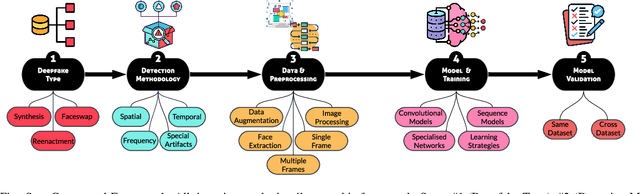
Deepfakes have rapidly emerged as a profound and serious threat to society, primarily due to their ease of creation and dissemination. This situation has triggered an accelerated development of deepfake detection technologies. However, many existing detectors rely heavily on lab-generated datasets for validation, which may not effectively prepare them for novel, emerging, and real-world deepfake techniques. In this paper, we conduct an extensive and comprehensive review and analysis of the latest state-of-the-art deepfake detectors, evaluating them against several critical criteria. These criteria facilitate the categorization of these detectors into 4 high-level groups and 13 fine-grained sub-groups, all aligned with a unified standard conceptual framework. This classification and framework offer deep and practical insights into the factors that affect detector efficacy. We assess the generalizability of 16 leading detectors across various standard attack scenarios, including black-box, white-box, and gray-box settings. Our systematized analysis and experimentation lay the groundwork for a deeper understanding of deepfake detectors and their generalizability, paving the way for future research focused on creating detectors adept at countering various attack scenarios. Additionally, this work offers insights for developing more proactive defenses against deepfakes.
Deepfake in the Metaverse: Security Implications for Virtual Gaming, Meetings, and Offices
Mar 26, 2023
The metaverse has gained significant attention from various industries due to its potential to create a fully immersive and interactive virtual world. However, the integration of deepfakes in the metaverse brings serious security implications, particularly with regard to impersonation. This paper examines the security implications of deepfakes in the metaverse, specifically in the context of gaming, online meetings, and virtual offices. The paper discusses how deepfakes can be used to impersonate in gaming scenarios, how online meetings in the metaverse open the door for impersonation, and how virtual offices in the metaverse lack physical authentication, making it easier for attackers to impersonate someone. The implications of these security concerns are discussed in relation to the confidentiality, integrity, and availability (CIA) triad. The paper further explores related issues such as the darkverse, and digital cloning, as well as regulatory and privacy concerns associated with addressing security threats in the virtual world.
OTJR: Optimal Transport Meets Optimal Jacobian Regularization for Adversarial Robustness
Mar 21, 2023Deep neural networks are widely recognized as being vulnerable to adversarial perturbation. To overcome this challenge, developing a robust classifier is crucial. So far, two well-known defenses have been adopted to improve the learning of robust classifiers, namely adversarial training (AT) and Jacobian regularization. However, each approach behaves differently against adversarial perturbations. First, our work carefully analyzes and characterizes these two schools of approaches, both theoretically and empirically, to demonstrate how each approach impacts the robust learning of a classifier. Next, we propose our novel Optimal Transport with Jacobian regularization method, dubbed OTJR, jointly incorporating the input-output Jacobian regularization into the AT by leveraging the optimal transport theory. In particular, we employ the Sliced Wasserstein (SW) distance that can efficiently push the adversarial samples' representations closer to those of clean samples, regardless of the number of classes within the dataset. The SW distance provides the adversarial samples' movement directions, which are much more informative and powerful for the Jacobian regularization. Our extensive experiments demonstrate the effectiveness of our proposed method, which jointly incorporates Jacobian regularization into AT. Furthermore, we demonstrate that our proposed method consistently enhances the model's robustness with CIFAR-100 dataset under various adversarial attack settings, achieving up to 28.49% under AutoAttack.
Why Do Deepfake Detectors Fail?
Feb 25, 2023



Recent rapid advancements in deepfake technology have allowed the creation of highly realistic fake media, such as video, image, and audio. These materials pose significant challenges to human authentication, such as impersonation, misinformation, or even a threat to national security. To keep pace with these rapid advancements, several deepfake detection algorithms have been proposed, leading to an ongoing arms race between deepfake creators and deepfake detectors. Nevertheless, these detectors are often unreliable and frequently fail to detect deepfakes. This study highlights the challenges they face in detecting deepfakes, including (1) the pre-processing pipeline of artifacts and (2) the fact that generators of new, unseen deepfake samples have not been considered when building the defense models. Our work sheds light on the need for further research and development in this field to create more robust and reliable detectors.
Towards an Awareness of Time Series Anomaly Detection Models' Adversarial Vulnerability
Aug 24, 2022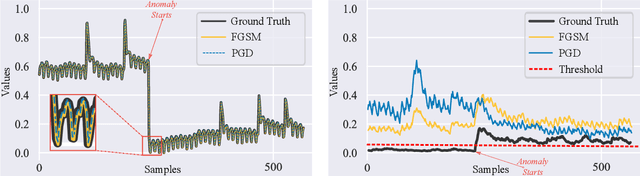
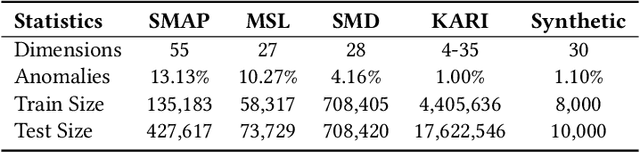
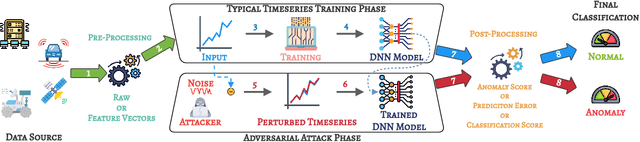
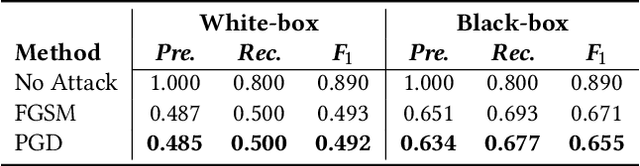
Time series anomaly detection is extensively studied in statistics, economics, and computer science. Over the years, numerous methods have been proposed for time series anomaly detection using deep learning-based methods. Many of these methods demonstrate state-of-the-art performance on benchmark datasets, giving the false impression that these systems are robust and deployable in many practical and industrial real-world scenarios. In this paper, we demonstrate that the performance of state-of-the-art anomaly detection methods is degraded substantially by adding only small adversarial perturbations to the sensor data. We use different scoring metrics such as prediction errors, anomaly, and classification scores over several public and private datasets ranging from aerospace applications, server machines, to cyber-physical systems in power plants. Under well-known adversarial attacks from Fast Gradient Sign Method (FGSM) and Projected Gradient Descent (PGD) methods, we demonstrate that state-of-the-art deep neural networks (DNNs) and graph neural networks (GNNs) methods, which claim to be robust against anomalies and have been possibly integrated in real-life systems, have their performance drop to as low as 0%. To the best of our understanding, we demonstrate, for the first time, the vulnerabilities of anomaly detection systems against adversarial attacks. The overarching goal of this research is to raise awareness towards the adversarial vulnerabilities of time series anomaly detectors.
Evaluation of an Audio-Video Multimodal Deepfake Dataset using Unimodal and Multimodal Detectors
Sep 07, 2021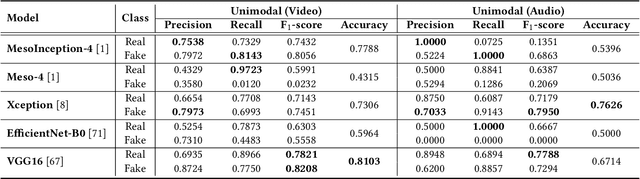
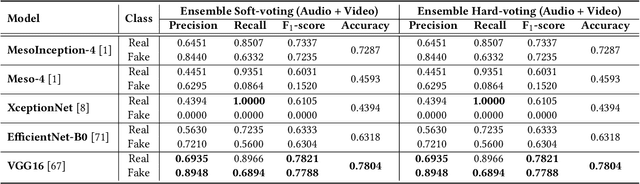
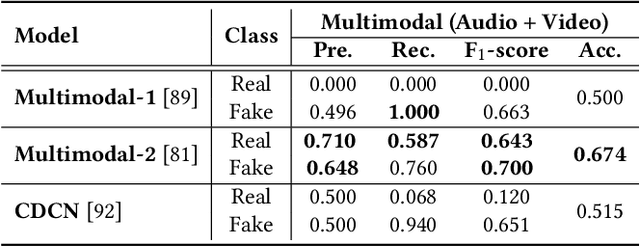
Significant advancements made in the generation of deepfakes have caused security and privacy issues. Attackers can easily impersonate a person's identity in an image by replacing his face with the target person's face. Moreover, a new domain of cloning human voices using deep-learning technologies is also emerging. Now, an attacker can generate realistic cloned voices of humans using only a few seconds of audio of the target person. With the emerging threat of potential harm deepfakes can cause, researchers have proposed deepfake detection methods. However, they only focus on detecting a single modality, i.e., either video or audio. On the other hand, to develop a good deepfake detector that can cope with the recent advancements in deepfake generation, we need to have a detector that can detect deepfakes of multiple modalities, i.e., videos and audios. To build such a detector, we need a dataset that contains video and respective audio deepfakes. We were able to find a most recent deepfake dataset, Audio-Video Multimodal Deepfake Detection Dataset (FakeAVCeleb), that contains not only deepfake videos but synthesized fake audios as well. We used this multimodal deepfake dataset and performed detailed baseline experiments using state-of-the-art unimodal, ensemble-based, and multimodal detection methods to evaluate it. We conclude through detailed experimentation that unimodals, addressing only a single modality, video or audio, do not perform well compared to ensemble-based methods. Whereas purely multimodal-based baselines provide the worst performance.