 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Detection to Correction: Backdoor-Resilient Face Recognition via Vision-Language Trigger Detection and Noise-Based Neutralization
Aug 07, 2025Biometric systems, such as face recognition systems powered by deep neural networks (DNNs), rely on large and highly sensitive datasets. Backdoor attacks can subvert these systems by manipulating the training process. By inserting a small trigger, such as a sticker, make-up, or patterned mask, into a few training images, an adversary can later present the same trigger during authentication to be falsely recognized as another individual, thereby gaining unauthorized access. Existing defense mechanisms against backdoor attacks still face challenges in precisely identifying and mitigating poisoned images without compromising data utility, which undermines the overall reliability of the system. We propose a novel and generalizable approach, TrueBiometric: Trustworthy Biometrics, which accurately detects poisoned images using a majority voting mechanism leveraging multiple state-of-the-art large vision language models. Once identified, poisoned samples are corrected using targeted and calibrated corrective noise. Our extensive empirical results demonstrate that TrueBiometric detects and corrects poisoned images with 100\% accuracy without compromising accuracy on clean images. Compared to existing state-of-the-art approaches, TrueBiometric offers a more practical, accurate, and effective solution for mitigating backdoor attacks in face recognition systems.
LLMs Are Not Yet Ready for Deepfake Image Detection
Jun 12, 2025



The growing sophistication of deepfakes presents substantial challenges to the integrity of media and the preservation of public trust. Concurrently, vision-language models (VLMs), large language models enhanced with visual reasoning capabilities, have emerged as promising tools across various domains, sparking interest in their applicability to deepfake detection. This study conducts a structured zero-shot evaluation of four prominent VLMs: ChatGPT, Claude, Gemini, and Grok, focusing on three primary deepfake types: faceswap, reenactment, and synthetic generation. Leveraging a meticulously assembled benchmark comprising authentic and manipulated images from diverse sources, we evaluate each model's classification accuracy and reasoning depth. Our analysis indicates that while VLMs can produce coherent explanations and detect surface-level anomalies, they are not yet dependable as standalone detection systems. We highlight critical failure modes, such as an overemphasis on stylistic elements and vulnerability to misleading visual patterns like vintage aesthetics. Nevertheless, VLMs exhibit strengths in interpretability and contextual analysis, suggesting their potential to augment human expertise in forensic workflows. These insights imply that although general-purpose models currently lack the reliability needed for autonomous deepfake detection, they hold promise as integral components in hybrid or human-in-the-loop detection frameworks.
Local Differential Privacy for Smart Meter Data Sharing
Nov 08, 2023



Energy disaggregation techniques, which use smart meter data to infer appliance energy usage, can provide consumers and energy companies valuable insights into energy management. However, these techniques also present privacy risks, such as the potential for behavioral profiling. Local differential privacy (LDP) methods provide strong privacy guarantees with high efficiency in addressing privacy concerns. However, existing LDP methods focus on protecting aggregated energy consumption data rather than individual appliances. Furthermore, these methods do not consider the fact that smart meter data are a form of streaming data, and its processing methods should account for time windows. In this paper, we propose a novel LDP approach (named LDP-SmartEnergy) that utilizes randomized response techniques with sliding windows to facilitate the sharing of appliance-level energy consumption data over time while not revealing individual users' appliance usage patterns. Our evaluations show that LDP-SmartEnergy runs efficiently compared to baseline methods. The results also demonstrate that our solution strikes a balance between protecting privacy and maintaining the utility of data for effective analysis.
Resurrecting Trust in Facial Recognition: Mitigating Backdoor Attacks in Face Recognition to Prevent Potential Privacy Breaches
Feb 18, 2022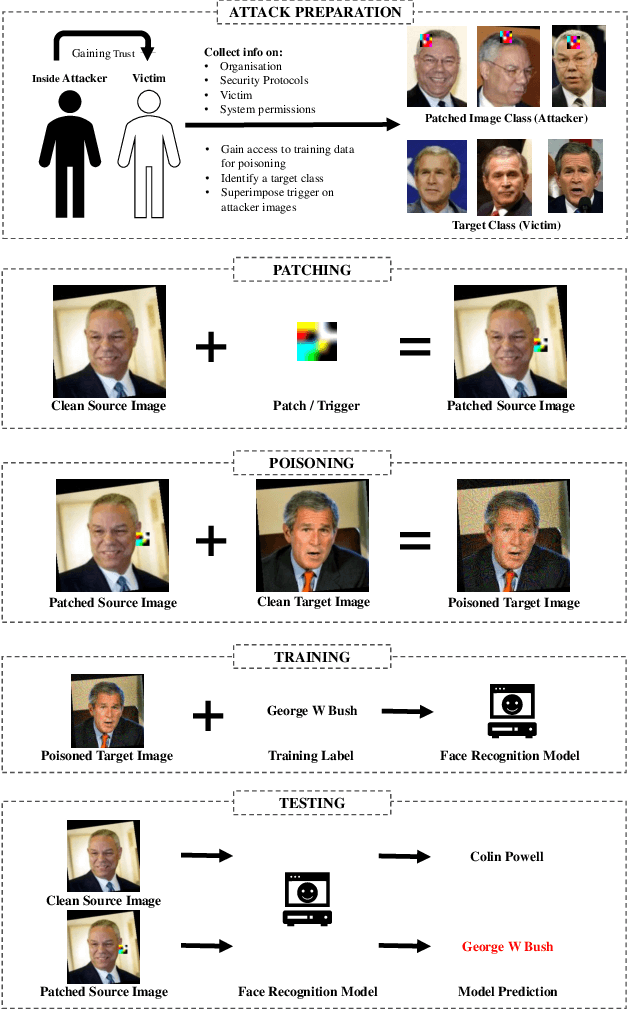
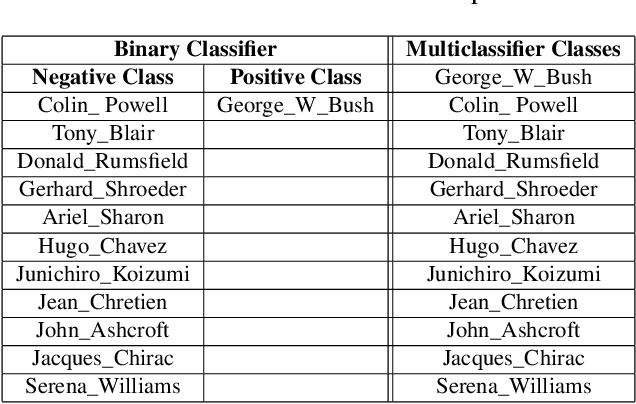
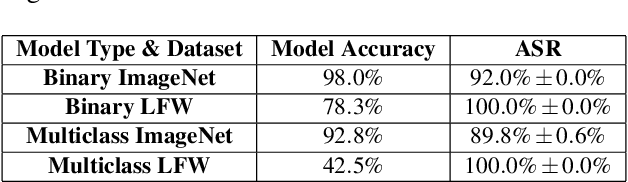
Biometric data, such as face images, are often associated with sensitive information (e.g medical, financial, personal government records). Hence, a data breach in a system storing such information can have devastating consequences. Deep learning is widely utilized for face recognition (FR); however, such models are vulnerable to backdoor attacks executed by malicious parties. Backdoor attacks cause a model to misclassify a particular class as a target class during recognition. This vulnerability can allow adversaries to gain access to highly sensitive data protected by biometric authentication measures or allow the malicious party to masquerade as an individual with higher system permissions. Such breaches pose a serious privacy threat. Previous methods integrate noise addition mechanisms into face recognition models to mitigate this issue and improve the robustness of classification against backdoor attacks. However, this can drastically affect model accuracy. We propose a novel and generalizable approach (named BA-BAM: Biometric Authentication - Backdoor Attack Mitigation), that aims to prevent backdoor attacks on face authentication deep learning models through transfer learning and selective image perturbation. The empirical evidence shows that BA-BAM is highly robust and incurs a maximal accuracy drop of 2.4%, while reducing the attack success rate to a maximum of 20%. Comparisons with existing approaches show that BA-BAM provides a more practical backdoor mitigation approach for face recognition.
Advancements of federated learning towards privacy preservation: from federated learning to split learning
Nov 25, 2020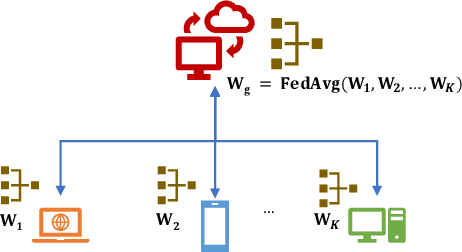

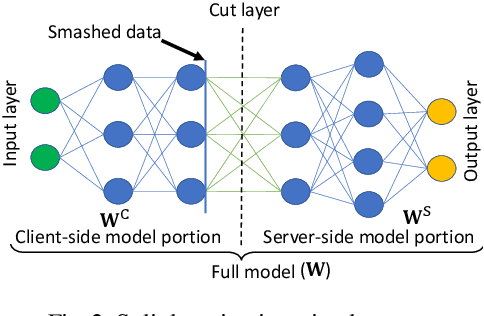
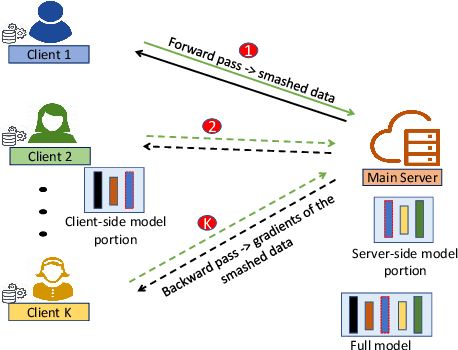
In the distributed collaborative machine learning (DCML) paradigm, federated learning (FL) recently attracted much attention due to its applications in health, finance, and the latest innovations such as industry 4.0 and smart vehicles. FL provides privacy-by-design. It trains a machine learning model collaboratively over several distributed clients (ranging from two to millions) such as mobile phones, without sharing their raw data with any other participant. In practical scenarios, all clients do not have sufficient computing resources (e.g., Internet of Things), the machine learning model has millions of parameters, and its privacy between the server and the clients while training/testing is a prime concern (e.g., rival parties). In this regard, FL is not sufficient, so split learning (SL) is introduced. SL is reliable in these scenarios as it splits a model into multiple portions, distributes them among clients and server, and trains/tests their respective model portions to accomplish the full model training/testing. In SL, the participants do not share both data and their model portions to any other parties, and usually, a smaller network portion is assigned to the clients where data resides. Recently, a hybrid of FL and SL, called splitfed learning, is introduced to elevate the benefits of both FL (faster training/testing time) and SL (model split and training). Following the developments from FL to SL, and considering the importance of SL, this chapter is designed to provide extensive coverage in SL and its variants. The coverage includes fundamentals, existing findings, integration with privacy measures such as differential privacy, open problems, and code implementation.
SplitFed: When Federated Learning Meets Split Learning
Apr 25, 2020

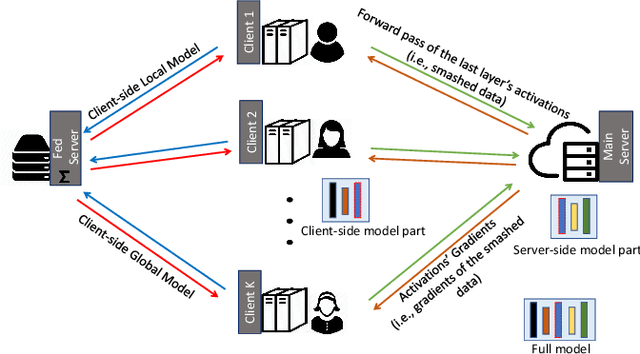

Federated learning (FL) and split learning (SL) are two recent distributed machine learning (ML) approaches that have gained attention due to their inherent privacy-preserving capabilities. Both approaches follow a model-to-data scenario, in that an ML model is sent to clients for network training and testing. However, FL and SL show contrasting strengths and weaknesses. For example, while FL performs faster than SL due to its parallel client-side model generation strategy, SL provides better privacy than FL due to the split of the ML model architecture between clients and the server. In contrast to FL, SL enables ML training with clients having low computing resources as the client trains only the first few layers of the split ML network model. In this paper, we present a novel approach, named splitfed (SFL), that amalgamates the two approaches eliminating their inherent drawbacks. SFL splits the network architecture between the clients and server as in SL to provide a higher level of privacy than FL. Moreover, it offers better efficiency than SL by incorporating the parallel ML model update paradigm of FL. Our empirical results considering uniformly distributed horizontally partitioned datasets and multiple clients show that SFL provides similar communication efficiency and test accuracies as SL, while significantly reducing - around five times - its computation time per global epoch. Furthermore, as in SL, its communication efficiency over FL improves with the increase in the number of clients.
Local Differential Privacy for Deep Learning
Aug 08, 2019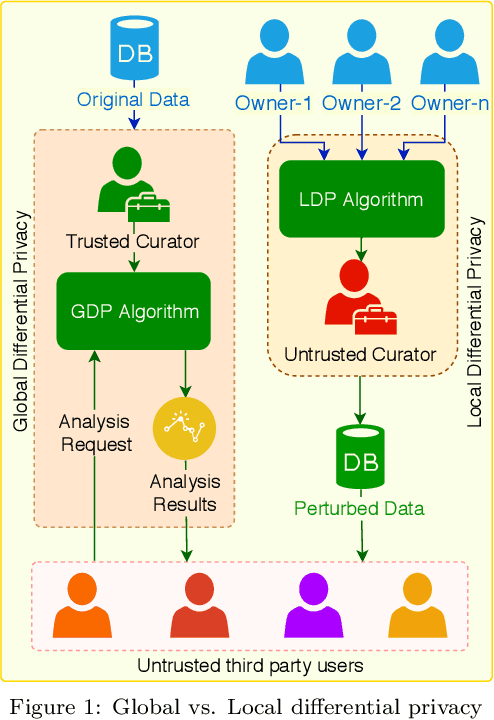

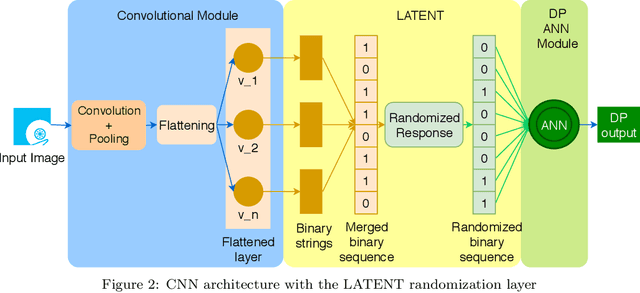
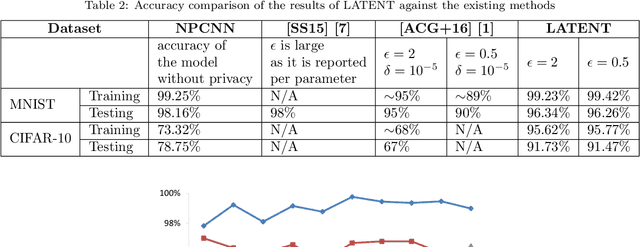
Deep learning (DL) is a promising area of machine learning which is becoming popular due to its remarkable accuracy when trained with a massive amount of data. Often, these datasets are highly sensitive crowd-sourced data such as medical data, financial data, or image data, and the DL models trained on these data tend to leak privacy. We propose a new local differentially private (LDP) algorithm (named LATENT) which redesigns the training process in a way that a data owner can add a randomization layer before data leave data owners' devices and reach to a potentially untrusted machine learning service. This way LATENT prevents privacy leaks of DL models, e.g., due to membership inference and memorizing model attacks, while providing excellent accuracy. By not requiring a trusted party, LATENT can be more practical for cloud-based machine learning services in comparison to existing differentially private approaches. Our experimental evaluation of LATENT on convolutional deep neural networks demonstrates excellent accuracy (e.g. 91\%- 96\%) with high model quality even under very low privacy budgets (e.g. $\epsilon=0.5$), outperforming existing differentially private approaches for deep learning.
A Fuzzy Based Model to Identify Printed Sinhala Characters
Dec 24, 2014
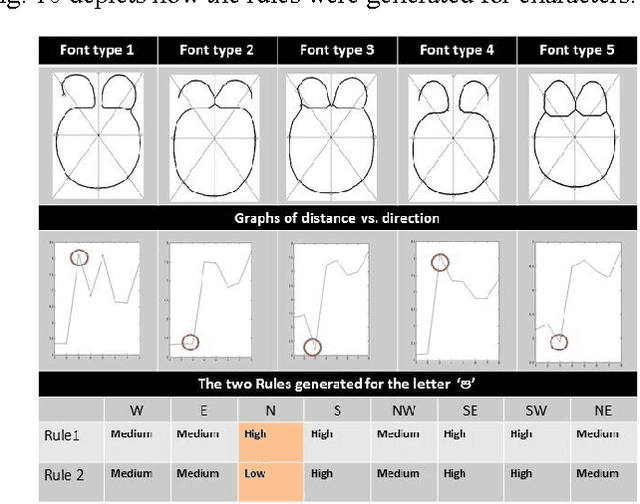
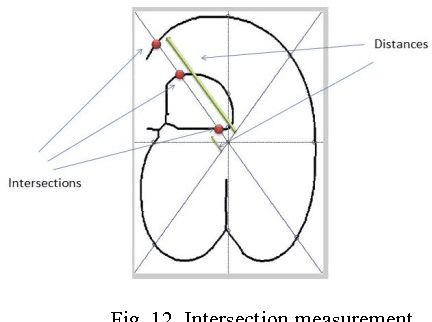
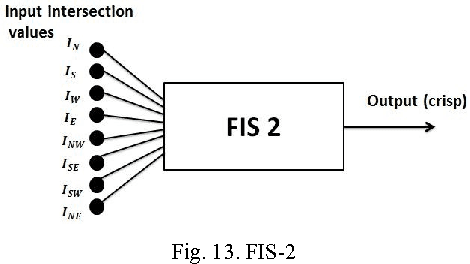
Character recognition techniques for printed documents are widely used for English language. However, the systems that are implemented to recognize Asian languages struggle to increase the accuracy of recognition. Among other Asian languages (such as Arabic, Tamil, Chinese), Sinhala characters are unique, mainly because they are round in shape. This unique feature makes it a challenge to extend the prevailing techniques to improve recognition of Sinhala characters. Therefore, a little attention has been given to improve the accuracy of Sinhala character recognition. A novel method, which makes use of this unique feature, could be advantageous over other methods. This paper describes the use of a fuzzy inference system to recognize Sinhala characters. Feature extraction is mainly focused on distance and intersection measurements in different directions from the center of the letter making use of the round shape of characters. The results showed an overall accuracy of 90.7% for 140 instances of letters tested, much better than similar systems.