 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancements of federated learning towards privacy preservation: from federated learning to split learning
Paper and Code
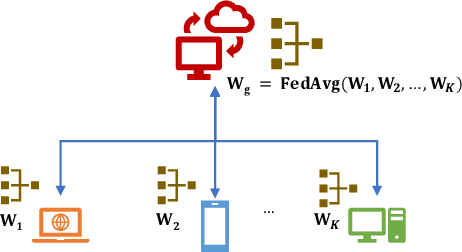

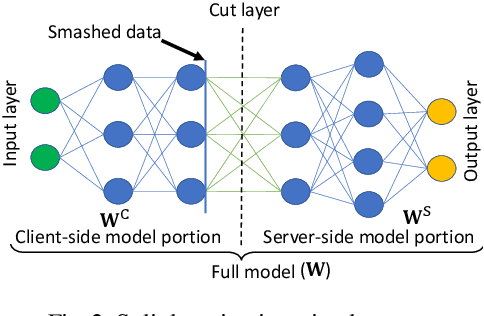
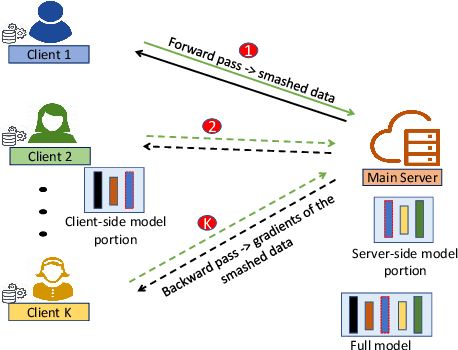
In the distributed collaborative machine learning (DCML) paradigm, federated learning (FL) recently attracted much attention due to its applications in health, finance, and the latest innovations such as industry 4.0 and smart vehicles. FL provides privacy-by-design. It trains a machine learning model collaboratively over several distributed clients (ranging from two to millions) such as mobile phones, without sharing their raw data with any other participant. In practical scenarios, all clients do not have sufficient computing resources (e.g., Internet of Things), the machine learning model has millions of parameters, and its privacy between the server and the clients while training/testing is a prime concern (e.g., rival parties). In this regard, FL is not sufficient, so split learning (SL) is introduced. SL is reliable in these scenarios as it splits a model into multiple portions, distributes them among clients and server, and trains/tests their respective model portions to accomplish the full model training/testing. In SL, the participants do not share both data and their model portions to any other parties, and usually, a smaller network portion is assigned to the clients where data resides. Recently, a hybrid of FL and SL, called splitfed learning, is introduced to elevate the benefits of both FL (faster training/testing time) and SL (model split and training). Following the developments from FL to SL, and considering the importance of SL, this chapter is designed to provide extensive coverage in SL and its variants. The coverage includes fundamentals, existing findings, integration with privacy measures such as differential privacy, open problems, and code implementation.