 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlockchain-based Federated Learning with Secure Aggregation in Trusted Execution Environment for Internet-of-Things
Apr 25, 2023



This paper proposes a blockchain-based Federated Learning (FL) framework with Intel Software Guard Extension (SGX)-based Trusted Execution Environment (TEE) to securely aggregate local models in Industrial Internet-of-Things (IIoTs). In FL, local models can be tampered with by attackers. Hence, a global model generated from the tampered local models can be erroneous. Therefore, the proposed framework leverages a blockchain network for secure model aggregation. Each blockchain node hosts an SGX-enabled processor that securely performs the FL-based aggregation tasks to generate a global model. Blockchain nodes can verify the authenticity of the aggregated model, run a blockchain consensus mechanism to ensure the integrity of the model, and add it to the distributed ledger for tamper-proof storage. Each cluster can obtain the aggregated model from the blockchain and verify its integrity before using it. We conducted several experiments with different CNN models and datasets to evaluate the performance of the proposed framework.
PhishClone: Measuring the Efficacy of Cloning Evasion Attacks
Sep 04, 2022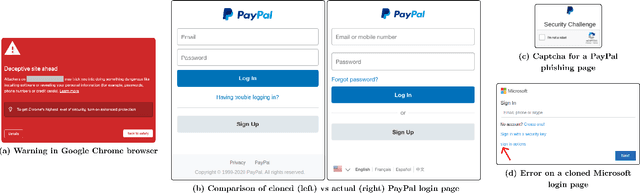
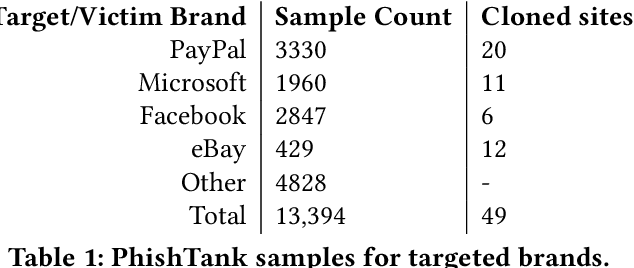

Web-based phishing accounts for over 90% of data breaches, and most web-browsers and security vendors rely on machine-learning (ML) models as mitigation. Despite this, links posted regularly on anti-phishing aggregators such as PhishTank and VirusTotal are shown to easily bypass existing detectors. Prior art suggests that automated website cloning, with light mutations, is gaining traction with attackers. This has limited exposure in current literature and leads to sub-optimal ML-based countermeasures. The work herein conducts the first empirical study that compiles and evaluates a variety of state-of-the-art cloning techniques in wide circulation. We collected 13,394 samples and found 8,566 confirmed phishing pages targeting 4 popular websites using 7 distinct cloning mechanisms. These samples were replicated with malicious code removed within a controlled platform fortified with precautions that prevent accidental access. We then reported our sites to VirusTotal and other platforms, with regular polling of results for 7 days, to ascertain the efficacy of each cloning technique. Results show that no security vendor detected our clones, proving the urgent need for more effective detectors. Finally, we posit 4 recommendations to aid web developers and ML-based defences to alleviate the risks of cloning attacks.
Towards Web Phishing Detection Limitations and Mitigation
Apr 03, 2022



Web phishing remains a serious cyber threat responsible for most data breaches. Machine Learning (ML)-based anti-phishing detectors are seen as an effective countermeasure, and are increasingly adopted by web-browsers and software products. However, with an average of 10K phishing links reported per hour to platforms such as PhishTank and VirusTotal (VT), the deficiencies of such ML-based solutions are laid bare. We first explore how phishing sites bypass ML-based detection with a deep dive into 13K phishing pages targeting major brands such as Facebook. Results show successful evasion is caused by: (1) use of benign services to obscure phishing URLs; (2) high similarity between the HTML structures of phishing and benign pages; (3) hiding the ultimate phishing content within Javascript and running such scripts only on the client; (4) looking beyond typical credentials and credit cards for new content such as IDs and documents; (5) hiding phishing content until after human interaction. We attribute the root cause to the dependency of ML-based models on the vertical feature space (webpage content). These solutions rely only on what phishers present within the page itself. Thus, we propose Anti-SubtlePhish, a more resilient model based on logistic regression. The key augmentation is the inclusion of a horizontal feature space, which examines correlation variables between the final render of suspicious pages against what trusted services have recorded (e.g., PageRank). To defeat (1) and (2), we correlate information between WHOIS, PageRank, and page analytics. To combat (3), (4) and (5), we correlate features after rendering the page. Experiments with 100K phishing/benign sites show promising accuracy (98.8%). We also obtained 100% accuracy against 0-day phishing pages that were manually crafted, comparing well to the 0% recorded by VT vendors over the first four days.
Resurrecting Trust in Facial Recognition: Mitigating Backdoor Attacks in Face Recognition to Prevent Potential Privacy Breaches
Feb 18, 2022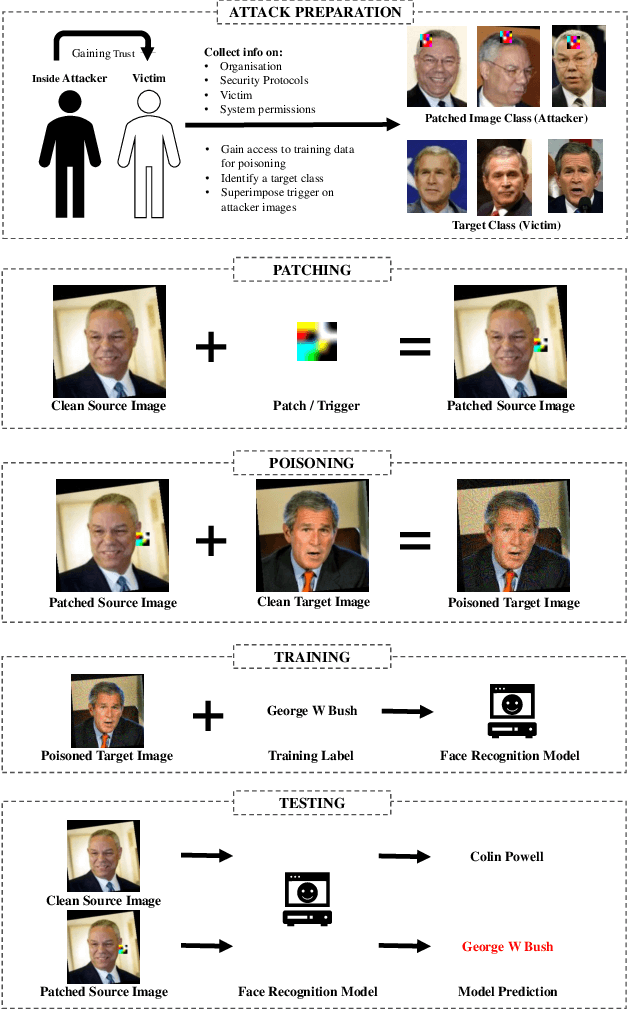
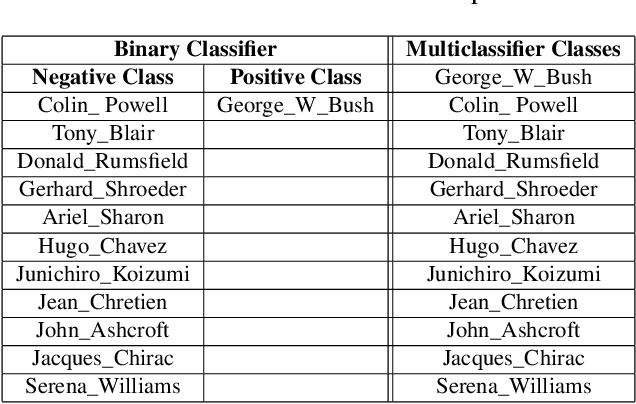
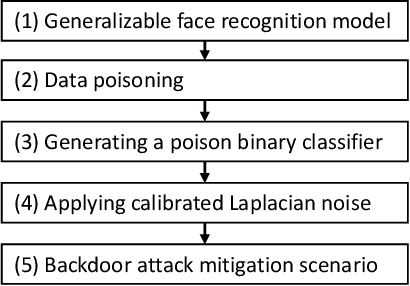
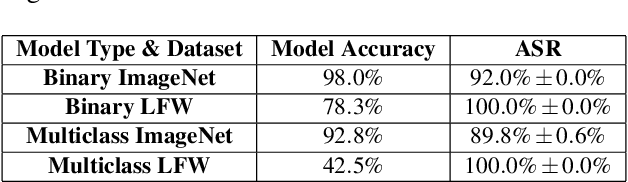
Biometric data, such as face images, are often associated with sensitive information (e.g medical, financial, personal government records). Hence, a data breach in a system storing such information can have devastating consequences. Deep learning is widely utilized for face recognition (FR); however, such models are vulnerable to backdoor attacks executed by malicious parties. Backdoor attacks cause a model to misclassify a particular class as a target class during recognition. This vulnerability can allow adversaries to gain access to highly sensitive data protected by biometric authentication measures or allow the malicious party to masquerade as an individual with higher system permissions. Such breaches pose a serious privacy threat. Previous methods integrate noise addition mechanisms into face recognition models to mitigate this issue and improve the robustness of classification against backdoor attacks. However, this can drastically affect model accuracy. We propose a novel and generalizable approach (named BA-BAM: Biometric Authentication - Backdoor Attack Mitigation), that aims to prevent backdoor attacks on face authentication deep learning models through transfer learning and selective image perturbation. The empirical evidence shows that BA-BAM is highly robust and incurs a maximal accuracy drop of 2.4%, while reducing the attack success rate to a maximum of 20%. Comparisons with existing approaches show that BA-BAM provides a more practical backdoor mitigation approach for face recognition.
Characterizing Malicious URL Campaigns
Aug 29, 2021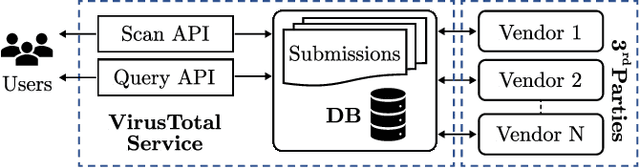

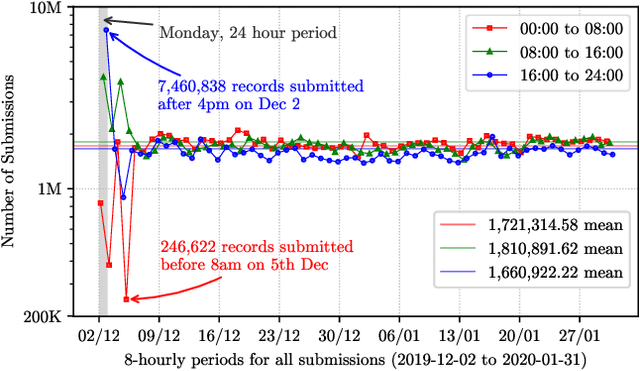
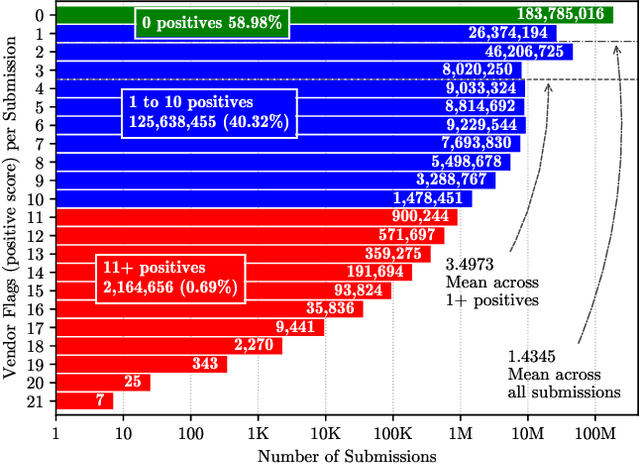
URLs are central to a myriad of cyber-security threats, from phishing to the distribution of malware. Their inherent ease of use and familiarity is continuously abused by attackers to evade defences and deceive end-users. Seemingly dissimilar URLs are being used in an organized way to perform phishing attacks and distribute malware. We refer to such behaviours as campaigns, with the hypothesis being that attacks are often coordinated to maximize success rates and develop evasion tactics. The aim is to gain better insights into campaigns, bolster our grasp of their characteristics, and thus aid the community devise more robust solutions. To this end, we performed extensive research and analysis into 311M records containing 77M unique real-world URLs that were submitted to VirusTotal from Dec 2019 to Jan 2020. From this dataset, 2.6M suspicious campaigns were identified based on their attached metadata, of which 77,810 were doubly verified as malicious. Using the 38.1M records and 9.9M URLs within these malicious campaigns, we provide varied insights such as their targeted victim brands as well as URL sizes and heterogeneity. Some surprising findings were observed, such as detection rates falling to just 13.27% for campaigns that employ more than 100 unique URLs. The paper concludes with several case-studies that illustrate the common malicious techniques employed by attackers to imperil users and circumvent defences.
FedEmail: Performance Measurement of Privacy-friendly Phishing Detection Enabled by Federated Learning
Jul 27, 2020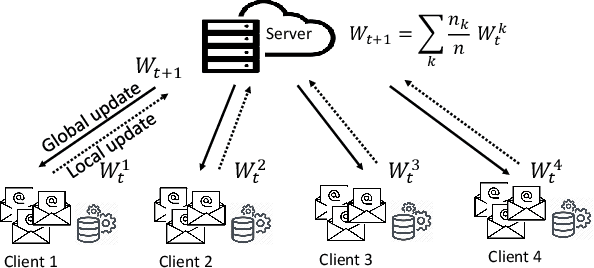

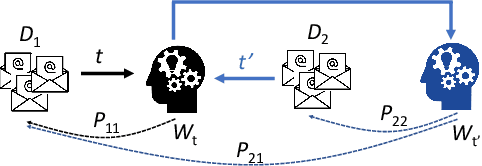

Artificial intelligence (AI) has been applied in phishing email detection. Typically, it requires rich email data from a collection of sources, and the data usually contains private information that needs to be preserved. So far, AI techniques are solely focusing on centralized data training that eventually accesses sensitive raw email data from the collected data repository. Thus, a privacy-friendly AI technique such as federated learning (FL) is a desideratum. FL enables learning over distributed email datasets to protect their privacy without the requirement of accessing them during the learning in a distributed computing framework. This work, to the best of our knowledge, is the first to investigate the applicability of training email anti-phishing model via FL. Building upon the Recurrent Convolutional Neural Network for phishing email detection, we comprehensively measure and evaluate the FL-entangled learning performance under various settings, including balanced and imbalanced data distribution among clients, scalability, communication overhead, and transfer learning. Our results positively corroborate comparable performance statistics of FL in phishing email detection to centralized learning. As a trade-off to privacy and distributed learning, FL has a communication overhead of 0.179 GB per global epoch per its clients. Our measurement-based results find that FL is suitable for practical scenarios, where data size variation, including the ratio of phishing to legitimate email samples, among the clients, are present. In all these scenarios, FL shows a similar performance of testing accuracy of around 98%. Besides, we demonstrate the integration of the newly joined clients with time in FL via transfer learning to improve the client-level performance. The transfer learning-enabled training results in the improvement of the testing accuracy by up to 2.6% and fast convergence.