 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhishClone: Measuring the Efficacy of Cloning Evasion Attacks
Paper and Code
Sep 04, 2022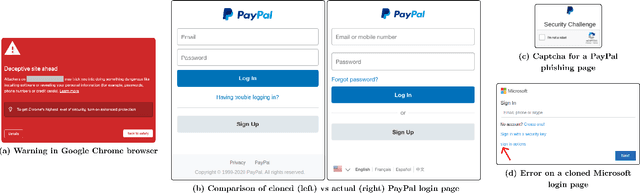
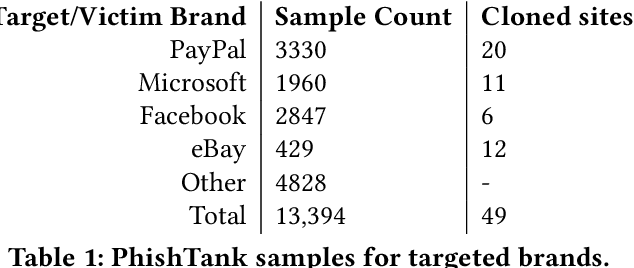

Web-based phishing accounts for over 90% of data breaches, and most web-browsers and security vendors rely on machine-learning (ML) models as mitigation. Despite this, links posted regularly on anti-phishing aggregators such as PhishTank and VirusTotal are shown to easily bypass existing detectors. Prior art suggests that automated website cloning, with light mutations, is gaining traction with attackers. This has limited exposure in current literature and leads to sub-optimal ML-based countermeasures. The work herein conducts the first empirical study that compiles and evaluates a variety of state-of-the-art cloning techniques in wide circulation. We collected 13,394 samples and found 8,566 confirmed phishing pages targeting 4 popular websites using 7 distinct cloning mechanisms. These samples were replicated with malicious code removed within a controlled platform fortified with precautions that prevent accidental access. We then reported our sites to VirusTotal and other platforms, with regular polling of results for 7 days, to ascertain the efficacy of each cloning technique. Results show that no security vendor detected our clones, proving the urgent need for more effective detectors. Finally, we posit 4 recommendations to aid web developers and ML-based defences to alleviate the risks of cloning attacks.