 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGETA: Generalized Encrypted Traffic Analysis
May 29, 2026Traditional traffic analysis is being fundamentally challenged by the rapid adoption of encryption, tunnelling, and privacy-preserving protocols, which increasingly obscure packet payloads and limit the usefulness of Deep Packet Inspection (DPI). Although machine learning has advanced encrypted traffic analysis, existing approaches often remain tied to protocol-specific header features, depend on large labelled datasets, and degrade when deployed across heterogeneous network environments. We present GETA, a protocol-agnostic framework for encrypted traffic analysis that models network flows as multivariate time series using only traffic metadata, thereby avoiding reliance on packet payloads or header semantics. GETA combines meta-learning, embedding refinement, and self-attention to support few-shot adaptation to previously unseen domains with minimal labelled data. Across nine public datasets spanning application identification, VPN traffic classification, IoT device fingerprinting, and attack detection, GETA consistently outperforms state-of-the-art baselines. These results show that GETA offers a practical and generalisable foundation for robust traffic analysis in modern encrypted networks.
PhishClone: Measuring the Efficacy of Cloning Evasion Attacks
Sep 04, 2022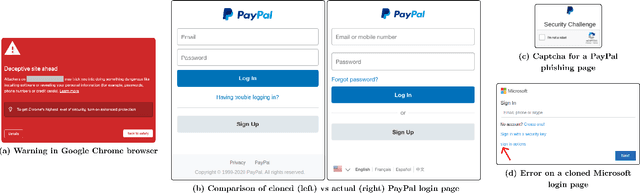
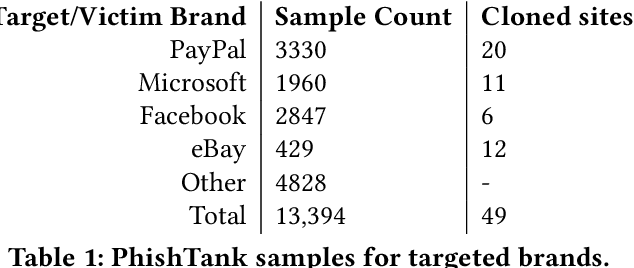
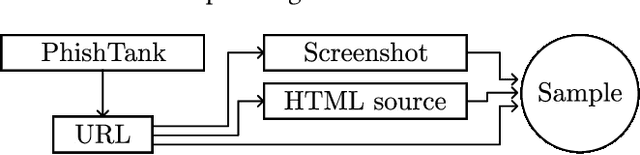

Web-based phishing accounts for over 90% of data breaches, and most web-browsers and security vendors rely on machine-learning (ML) models as mitigation. Despite this, links posted regularly on anti-phishing aggregators such as PhishTank and VirusTotal are shown to easily bypass existing detectors. Prior art suggests that automated website cloning, with light mutations, is gaining traction with attackers. This has limited exposure in current literature and leads to sub-optimal ML-based countermeasures. The work herein conducts the first empirical study that compiles and evaluates a variety of state-of-the-art cloning techniques in wide circulation. We collected 13,394 samples and found 8,566 confirmed phishing pages targeting 4 popular websites using 7 distinct cloning mechanisms. These samples were replicated with malicious code removed within a controlled platform fortified with precautions that prevent accidental access. We then reported our sites to VirusTotal and other platforms, with regular polling of results for 7 days, to ascertain the efficacy of each cloning technique. Results show that no security vendor detected our clones, proving the urgent need for more effective detectors. Finally, we posit 4 recommendations to aid web developers and ML-based defences to alleviate the risks of cloning attacks.
Integrity Fingerprinting of DNN with Double Black-box Design and Verification
Mar 23, 2022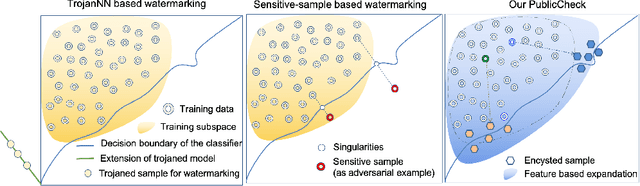

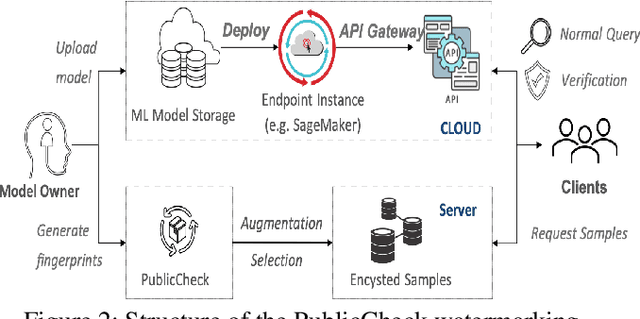

Cloud-enabled Machine Learning as a Service (MLaaS) has shown enormous promise to transform how deep learning models are developed and deployed. Nonetheless, there is a potential risk associated with the use of such services since a malicious party can modify them to achieve an adverse result. Therefore, it is imperative for model owners, service providers, and end-users to verify whether the deployed model has not been tampered with or not. Such verification requires public verifiability (i.e., fingerprinting patterns are available to all parties, including adversaries) and black-box access to the deployed model via APIs. Existing watermarking and fingerprinting approaches, however, require white-box knowledge (such as gradient) to design the fingerprinting and only support private verifiability, i.e., verification by an honest party. In this paper, we describe a practical watermarking technique that enables black-box knowledge in fingerprint design and black-box queries during verification. The service ensures the integrity of cloud-based services through public verification (i.e. fingerprinting patterns are available to all parties, including adversaries). If an adversary manipulates a model, this will result in a shift in the decision boundary. Thus, the underlying principle of double-black watermarking is that a model's decision boundary could serve as an inherent fingerprint for watermarking. Our approach captures the decision boundary by generating a limited number of encysted sample fingerprints, which are a set of naturally transformed and augmented inputs enclosed around the model's decision boundary in order to capture the inherent fingerprints of the model. We evaluated our watermarking approach against a variety of model integrity attacks and model compression attacks.
TSM: Measuring the Enticement of Honeyfiles with Natural Language Processing
Mar 15, 2022

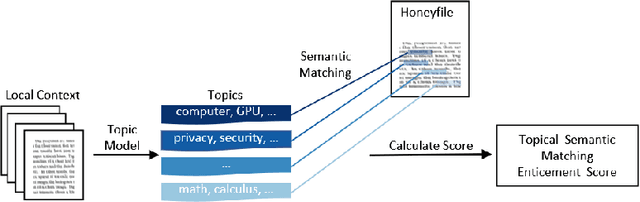

Honeyfile deployment is a useful breach detection method in cyber deception that can also inform defenders about the intent and interests of intruders and malicious insiders. A key property of a honeyfile, enticement, is the extent to which the file can attract an intruder to interact with it. We introduce a novel metric, Topic Semantic Matching (TSM), which uses topic modelling to represent files in the repository and semantic matching in an embedding vector space to compare honeyfile text and topic words robustly. We also present a honeyfile corpus created with different Natural Language Processing (NLP) methods. Experiments show that TSM is effective in inter-corpus comparisons and is a promising tool to measure the enticement of honeyfiles. TSM is the first measure to use NLP techniques to quantify the enticement of honeyfile content that compares the essential topical content of local contexts to honeyfiles and is robust to paraphrasing.