 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoneyfile Camouflage: Hiding Fake Files in Plain Sight
May 08, 2024Honeyfiles are a particularly useful type of honeypot: fake files deployed to detect and infer information from malicious behaviour. This paper considers the challenge of naming honeyfiles so they are camouflaged when placed amongst real files in a file system. Based on cosine distances in semantic vector spaces, we develop two metrics for filename camouflage: one based on simple averaging and one on clustering with mixture fitting. We evaluate and compare the metrics, showing that both perform well on a publicly available GitHub software repository dataset.
Contextual Chart Generation for Cyber Deception
Apr 07, 2024Honeyfiles are security assets designed to attract and detect intruders on compromised systems. Honeyfiles are a type of honeypot that mimic real, sensitive documents, creating the illusion of the presence of valuable data. Interaction with a honeyfile reveals the presence of an intruder, and can provide insights into their goals and intentions. Their practical use, however, is limited by the time, cost and effort associated with manually creating realistic content. The introduction of large language models has made high-quality text generation accessible, but honeyfiles contain a variety of content including charts, tables and images. This content needs to be plausible and realistic, as well as semantically consistent both within honeyfiles and with the real documents they mimic, to successfully deceive an intruder. In this paper, we focus on an important component of the honeyfile content generation problem: document charts. Charts are ubiquitous in corporate documents and are commonly used to communicate quantitative and scientific data. Existing image generation models, such as DALL-E, are rather prone to generating charts with incomprehensible text and unconvincing data. We take a multi-modal approach to this problem by combining two purpose-built generative models: a multitask Transformer and a specialized multi-head autoencoder. The Transformer generates realistic captions and plot text, while the autoencoder generates the underlying tabular data for the plot. To advance the field of automated honeyplot generation, we also release a new document-chart dataset and propose a novel metric Keyword Semantic Matching (KSM). This metric measures the semantic consistency between keywords of a corpus and a smaller bag of words. Extensive experiments demonstrate excellent performance against multiple large language models, including ChatGPT and GPT4.
Multiple Hypothesis Dropout: Estimating the Parameters of Multi-Modal Output Distributions
Dec 18, 2023



In many real-world applications, from robotics to pedestrian trajectory prediction, there is a need to predict multiple real-valued outputs to represent several potential scenarios. Current deep learning techniques to address multiple-output problems are based on two main methodologies: (1) mixture density networks, which suffer from poor stability at high dimensions, or (2) multiple choice learning (MCL), an approach that uses $M$ single-output functions, each only producing a point estimate hypothesis. This paper presents a Mixture of Multiple-Output functions (MoM) approach using a novel variant of dropout, Multiple Hypothesis Dropout. Unlike traditional MCL-based approaches, each multiple-output function not only estimates the mean but also the variance for its hypothesis. This is achieved through a novel stochastic winner-take-all loss which allows each multiple-output function to estimate variance through the spread of its subnetwork predictions. Experiments on supervised learning problems illustrate that our approach outperforms existing solutions for reconstructing multimodal output distributions. Additional studies on unsupervised learning problems show that estimating the parameters of latent posterior distributions within a discrete autoencoder significantly improves codebook efficiency, sample quality, precision and recall.
DualVAE: Controlling Colours of Generated and Real Images
May 30, 2023


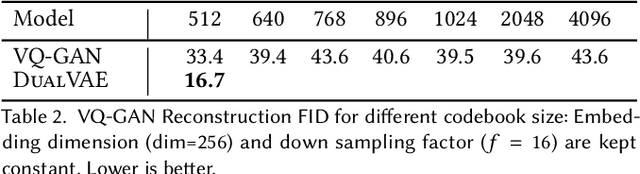
Colour controlled image generation and manipulation are of interest to artists and graphic designers. Vector Quantised Variational AutoEncoders (VQ-VAEs) with autoregressive (AR) prior are able to produce high quality images, but lack an explicit representation mechanism to control colour attributes. We introduce DualVAE, a hybrid representation model that provides such control by learning disentangled representations for colour and geometry. The geometry is represented by an image intensity mapping that identifies structural features. The disentangled representation is obtained by two novel mechanisms: (i) a dual branch architecture that separates image colour attributes from geometric attributes, and (ii) a new ELBO that trains the combined colour and geometry representations. DualVAE can control the colour of generated images, and recolour existing images by transferring the colour latent representation obtained from an exemplar image. We demonstrate that DualVAE generates images with FID nearly two times better than VQ-GAN on a diverse collection of datasets, including animated faces, logos and artistic landscapes.
Deception for Cyber Defence: Challenges and Opportunities
Aug 15, 2022
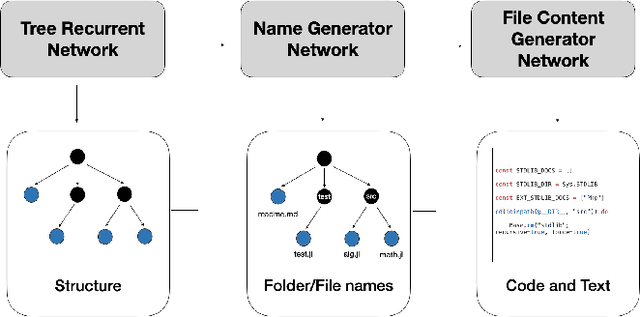
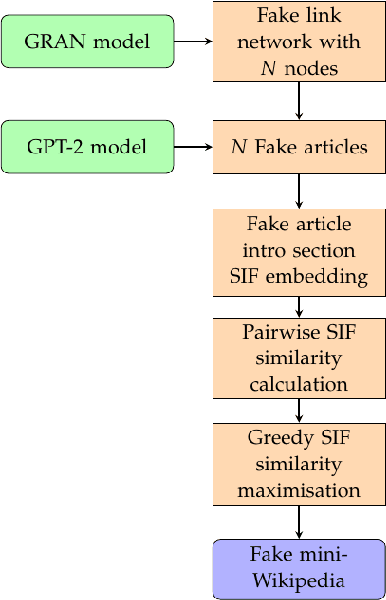
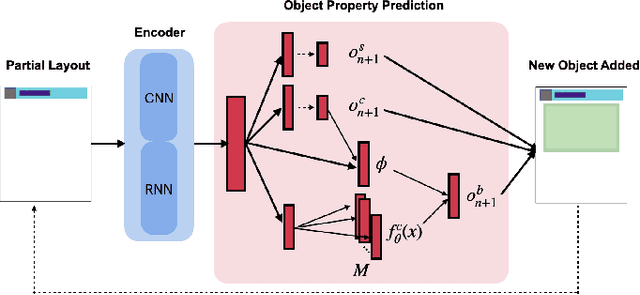
Deception is rapidly growing as an important tool for cyber defence, complementing existing perimeter security measures to rapidly detect breaches and data theft. One of the factors limiting the use of deception has been the cost of generating realistic artefacts by hand. Recent advances in Machine Learning have, however, created opportunities for scalable, automated generation of realistic deceptions. This vision paper describes the opportunities and challenges involved in developing models to mimic many common elements of the IT stack for deception effects.
TSM: Measuring the Enticement of Honeyfiles with Natural Language Processing
Mar 15, 2022

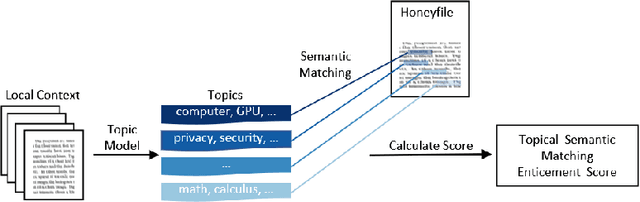

Honeyfile deployment is a useful breach detection method in cyber deception that can also inform defenders about the intent and interests of intruders and malicious insiders. A key property of a honeyfile, enticement, is the extent to which the file can attract an intruder to interact with it. We introduce a novel metric, Topic Semantic Matching (TSM), which uses topic modelling to represent files in the repository and semantic matching in an embedding vector space to compare honeyfile text and topic words robustly. We also present a honeyfile corpus created with different Natural Language Processing (NLP) methods. Experiments show that TSM is effective in inter-corpus comparisons and is a promising tool to measure the enticement of honeyfiles. TSM is the first measure to use NLP techniques to quantify the enticement of honeyfile content that compares the essential topical content of local contexts to honeyfiles and is robust to paraphrasing.
Can pre-trained Transformers be used in detecting complex sensitive sentences? -- A Monsanto case study
Mar 14, 2022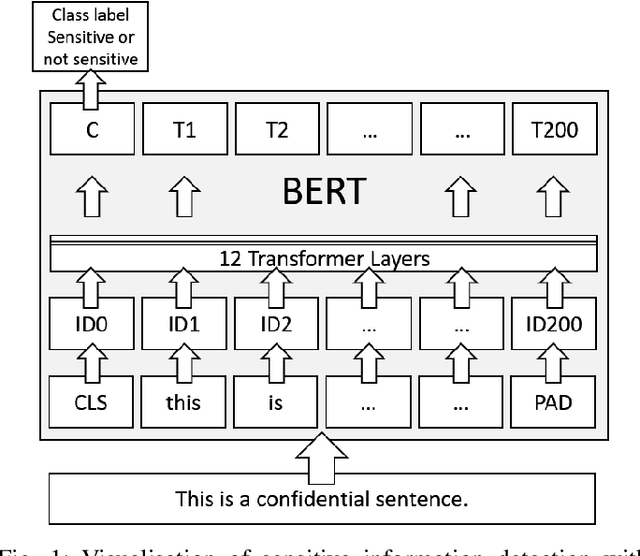
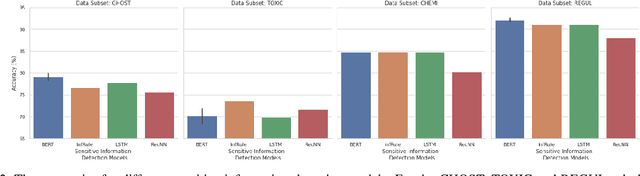
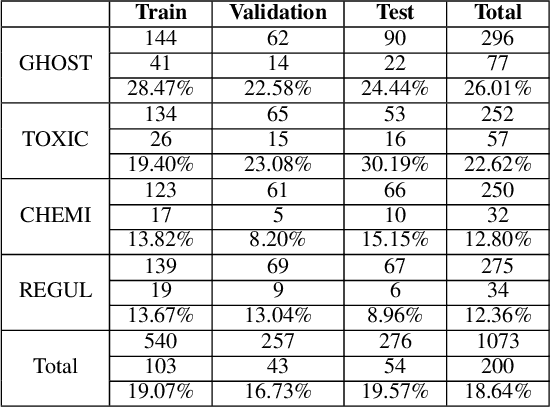
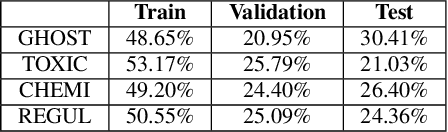
Each and every organisation releases information in a variety of forms ranging from annual reports to legal proceedings. Such documents may contain sensitive information and releasing them openly may lead to the leakage of confidential information. Detection of sentences that contain sensitive information in documents can help organisations prevent the leakage of valuable confidential information. This is especially challenging when such sentences contain a substantial amount of information or are paraphrased versions of known sensitive content. Current approaches to sensitive information detection in such complex settings are based on keyword-based approaches or standard machine learning models. In this paper, we wish to explore whether pre-trained transformer models are well suited to detect complex sensitive information. Pre-trained transformers are typically trained on an enormous amount of text and therefore readily learn grammar, structure and other linguistic features, making them particularly attractive for this task. Through our experiments on the Monsanto trial data set, we observe that the fine-tuned Bidirectional Encoder Representations from Transformers (BERT) transformer model performs better than traditional models. We experimented with four different categories of documents in the Monsanto dataset and observed that BERT achieves better F2 scores by 24.13\% to 65.79\% for GHOST, 30.14\% to 54.88\% for TOXIC, 39.22\% for CHEMI, 53.57\% for REGUL compared to existing sensitive information detection models.
SchemaDB: Structures in Relational Datasets
Nov 24, 2021


In this paper we introduce the SchemaDB data-set; a collection of relational database schemata in both sql and graph formats. Databases are not commonly shared publicly for reasons of privacy and security, so schemata are not available for study. Consequently, an understanding of database structures in the wild is lacking, and most examples found publicly belong to common development frameworks or are derived from textbooks or engine benchmark designs. SchemaDB contains 2,500 samples of relational schemata found in public repositories which we have standardised to MySQL syntax. We provide our gathering and transformation methodology, summary statistics, and structural analysis, and discuss potential downstream research tasks in several domains.
Modelling Direct Messaging Networks with Multiple Recipients for Cyber Deception
Nov 21, 2021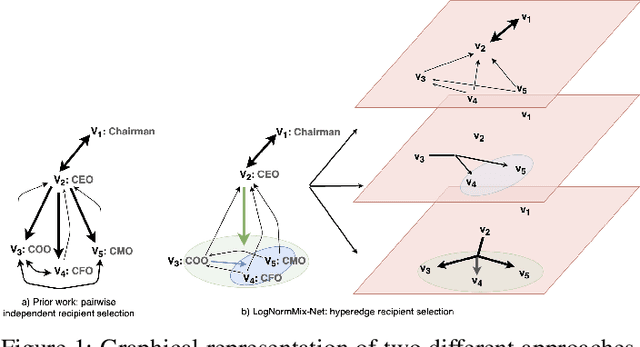

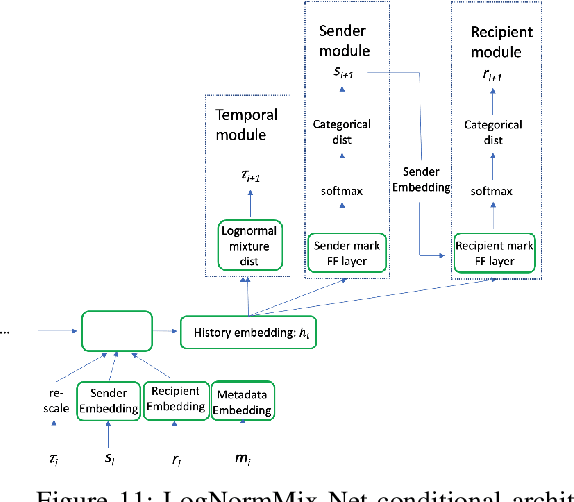
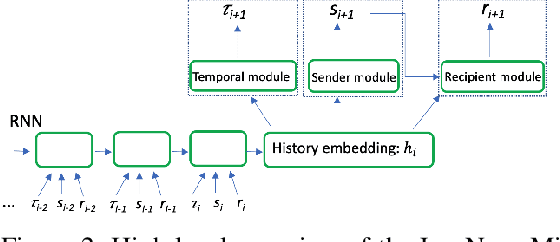
Cyber deception is emerging as a promising approach to defending networks and systems against attackers and data thieves. However, despite being relatively cheap to deploy, the generation of realistic content at scale is very costly, due to the fact that rich, interactive deceptive technologies are largely hand-crafted. With recent improvements in Machine Learning, we now have the opportunity to bring scale and automation to the creation of realistic and enticing simulated content. In this work, we propose a framework to automate the generation of email and instant messaging-style group communications at scale. Such messaging platforms within organisations contain a lot of valuable information inside private communications and document attachments, making them an enticing target for an adversary. We address two key aspects of simulating this type of system: modelling when and with whom participants communicate, and generating topical, multi-party text to populate simulated conversation threads. We present the LogNormMix-Net Temporal Point Process as an approach to the first of these, building upon the intensity-free modeling approach of Shchur et al.~\cite{shchur2019intensity} to create a generative model for unicast and multi-cast communications. We demonstrate the use of fine-tuned, pre-trained language models to generate convincing multi-party conversation threads. A live email server is simulated by uniting our LogNormMix-Net TPP (to generate the communication timestamp, sender and recipients) with the language model, which generates the contents of the multi-party email threads. We evaluate the generated content with respect to a number of realism-based properties, that encourage a model to learn to generate content that will engage the attention of an adversary to achieve a deception outcome.