 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat is the Cost of Differential Privacy for Deep Learning-Based Trajectory Generation?
Jun 11, 2025While location trajectories offer valuable insights, they also reveal sensitive personal information. Differential Privacy (DP) offers formal protection, but achieving a favourable utility-privacy trade-off remains challenging. Recent works explore deep learning-based generative models to produce synthetic trajectories. However, current models lack formal privacy guarantees and rely on conditional information derived from real data during generation. This work investigates the utility cost of enforcing DP in such models, addressing three research questions across two datasets and eleven utility metrics. (1) We evaluate how DP-SGD, the standard DP training method for deep learning, affects the utility of state-of-the-art generative models. (2) Since DP-SGD is limited to unconditional models, we propose a novel DP mechanism for conditional generation that provides formal guarantees and assess its impact on utility. (3) We analyse how model types - Diffusion, VAE, and GAN - affect the utility-privacy trade-off. Our results show that DP-SGD significantly impacts performance, although some utility remains if the datasets is sufficiently large. The proposed DP mechanism improves training stability, particularly when combined with DP-SGD, for unstable models such as GANs and on smaller datasets. Diffusion models yield the best utility without guarantees, but with DP-SGD, GANs perform best, indicating that the best non-private model is not necessarily optimal when targeting formal guarantees. In conclusion, DP trajectory generation remains a challenging task, and formal guarantees are currently only feasible with large datasets and in constrained use cases.
Contextual Chart Generation for Cyber Deception
Apr 07, 2024Honeyfiles are security assets designed to attract and detect intruders on compromised systems. Honeyfiles are a type of honeypot that mimic real, sensitive documents, creating the illusion of the presence of valuable data. Interaction with a honeyfile reveals the presence of an intruder, and can provide insights into their goals and intentions. Their practical use, however, is limited by the time, cost and effort associated with manually creating realistic content. The introduction of large language models has made high-quality text generation accessible, but honeyfiles contain a variety of content including charts, tables and images. This content needs to be plausible and realistic, as well as semantically consistent both within honeyfiles and with the real documents they mimic, to successfully deceive an intruder. In this paper, we focus on an important component of the honeyfile content generation problem: document charts. Charts are ubiquitous in corporate documents and are commonly used to communicate quantitative and scientific data. Existing image generation models, such as DALL-E, are rather prone to generating charts with incomprehensible text and unconvincing data. We take a multi-modal approach to this problem by combining two purpose-built generative models: a multitask Transformer and a specialized multi-head autoencoder. The Transformer generates realistic captions and plot text, while the autoencoder generates the underlying tabular data for the plot. To advance the field of automated honeyplot generation, we also release a new document-chart dataset and propose a novel metric Keyword Semantic Matching (KSM). This metric measures the semantic consistency between keywords of a corpus and a smaller bag of words. Extensive experiments demonstrate excellent performance against multiple large language models, including ChatGPT and GPT4.
Multiple Hypothesis Dropout: Estimating the Parameters of Multi-Modal Output Distributions
Dec 18, 2023



In many real-world applications, from robotics to pedestrian trajectory prediction, there is a need to predict multiple real-valued outputs to represent several potential scenarios. Current deep learning techniques to address multiple-output problems are based on two main methodologies: (1) mixture density networks, which suffer from poor stability at high dimensions, or (2) multiple choice learning (MCL), an approach that uses $M$ single-output functions, each only producing a point estimate hypothesis. This paper presents a Mixture of Multiple-Output functions (MoM) approach using a novel variant of dropout, Multiple Hypothesis Dropout. Unlike traditional MCL-based approaches, each multiple-output function not only estimates the mean but also the variance for its hypothesis. This is achieved through a novel stochastic winner-take-all loss which allows each multiple-output function to estimate variance through the spread of its subnetwork predictions. Experiments on supervised learning problems illustrate that our approach outperforms existing solutions for reconstructing multimodal output distributions. Additional studies on unsupervised learning problems show that estimating the parameters of latent posterior distributions within a discrete autoencoder significantly improves codebook efficiency, sample quality, precision and recall.
Diverse Multimedia Layout Generation with Multi Choice Learning
Jan 16, 2023

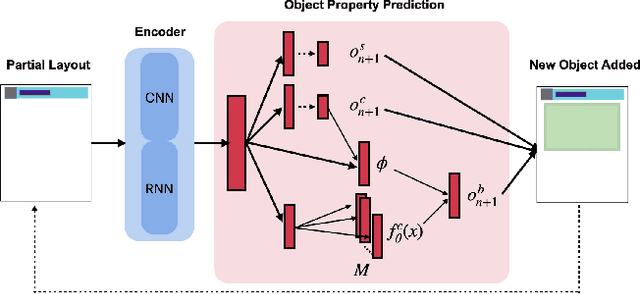

Designing visually appealing layouts for multimedia documents containing text, graphs and images requires a form of creative intelligence. Modelling the generation of layouts has recently gained attention due to its importance in aesthetics and communication style. In contrast to standard prediction tasks, there are a range of acceptable layouts which depend on user preferences. For example, a poster designer may prefer logos on the top-left while another prefers logos on the bottom-right. Both are correct choices yet existing machine learning models treat layouts as a single choice prediction problem. In such situations, these models would simply average over all possible choices given the same input forming a degenerate sample. In the above example, this would form an unacceptable layout with a logo in the centre. In this paper, we present an auto-regressive neural network architecture, called LayoutMCL, that uses multi-choice prediction and winner-takes-all loss to effectively stabilise layout generation. LayoutMCL avoids the averaging problem by using multiple predictors to learn a range of possible options for each layout object. This enables LayoutMCL to generate multiple and diverse layouts from a single input which is in contrast with existing approaches which yield similar layouts with minor variations. Through quantitative benchmarks on real data (magazine, document and mobile app layouts), we demonstrate that LayoutMCL reduces Fr\'echet Inception Distance (FID) by 83-98% and generates significantly more diversity in comparison to existing approaches.
* 9 pages
Masked Vector Quantization
Jan 16, 2023
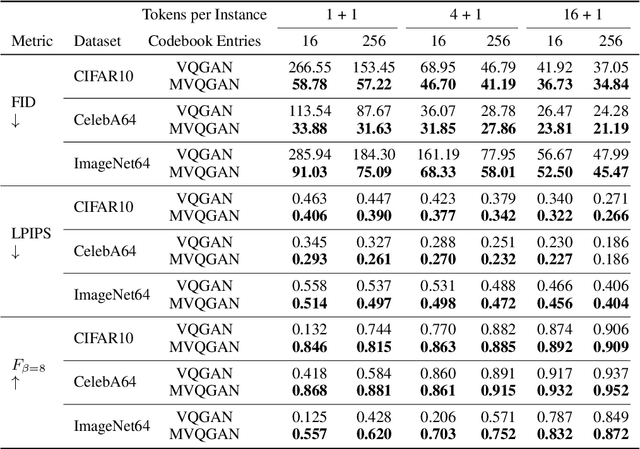


Generative models with discrete latent representations have recently demonstrated an impressive ability to learn complex high-dimensional data distributions. However, their performance relies on a long sequence of tokens per instance and a large number of codebook entries, resulting in long sampling times and considerable computation to fit the categorical posterior. To address these issues, we propose the Masked Vector Quantization (MVQ) framework which increases the representational capacity of each code vector by learning mask configurations via a stochastic winner-takes-all training regime called Multiple Hypothese Dropout (MH-Dropout). On ImageNet 64$\times$64, MVQ reduces FID in existing vector quantization architectures by up to $68\%$ at 2 tokens per instance and $57\%$ at 5 tokens. These improvements widen as codebook entries is reduced and allows for $7\textit{--}45\times$ speed-up in token sampling during inference. As an additional benefit, we find that smaller latent spaces lead to MVQ identifying transferable visual representations where multiple can be smoothly combined.
Is this IoT Device Likely to be Secure? Risk Score Prediction for IoT Devices Using Gradient Boosting Machines
Nov 23, 2021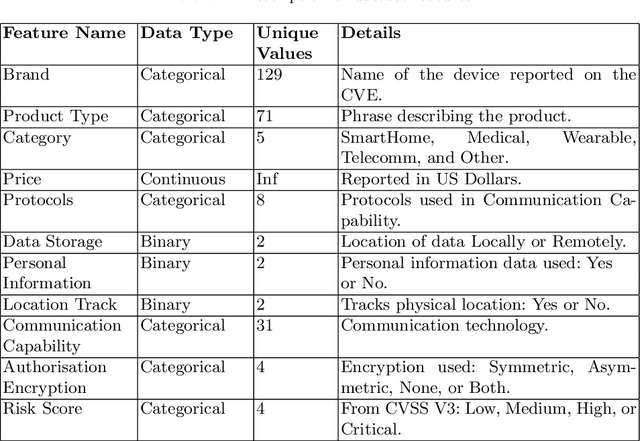
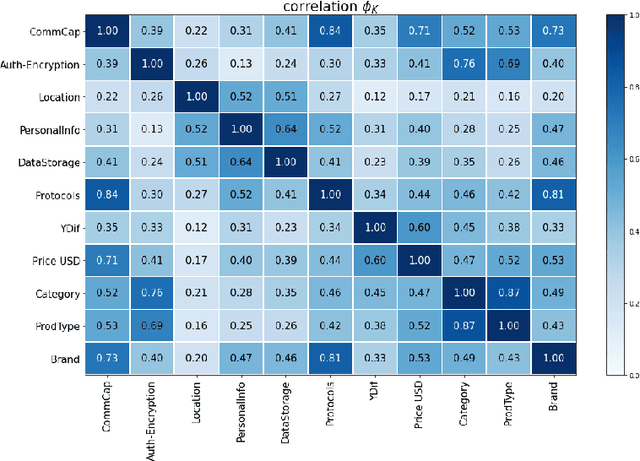
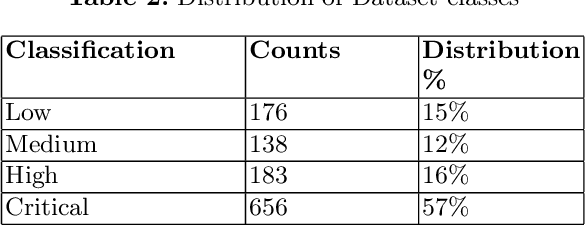

Security risk assessment and prediction are critical for organisations deploying Internet of Things (IoT) devices. An absolute minimum requirement for enterprises is to verify the security risk of IoT devices for the reported vulnerabilities in the National Vulnerability Database (NVD). This paper proposes a novel risk prediction for IoT devices based on publicly available information about them. Our solution provides an easy and cost-efficient solution for enterprises of all sizes to predict the security risk of deploying new IoT devices. After an extensive analysis of the NVD records over the past eight years, we have created a unique, systematic, and balanced dataset for vulnerable IoT devices, including key technical features complemented with functional and descriptive features available from public resources. We then use machine learning classification models such as Gradient Boosting Decision Trees (GBDT) over this dataset and achieve 71% prediction accuracy in classifying the severity of device vulnerability score.