 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Vector Quantization
Paper and Code
Jan 16, 2023
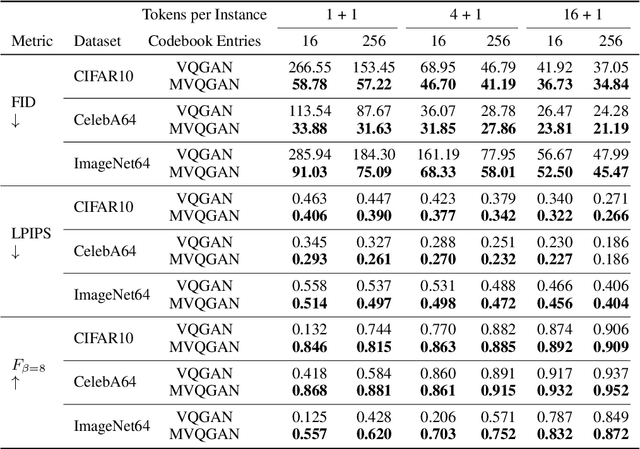


Generative models with discrete latent representations have recently demonstrated an impressive ability to learn complex high-dimensional data distributions. However, their performance relies on a long sequence of tokens per instance and a large number of codebook entries, resulting in long sampling times and considerable computation to fit the categorical posterior. To address these issues, we propose the Masked Vector Quantization (MVQ) framework which increases the representational capacity of each code vector by learning mask configurations via a stochastic winner-takes-all training regime called Multiple Hypothese Dropout (MH-Dropout). On ImageNet 64$\times$64, MVQ reduces FID in existing vector quantization architectures by up to $68\%$ at 2 tokens per instance and $57\%$ at 5 tokens. These improvements widen as codebook entries is reduced and allows for $7\textit{--}45\times$ speed-up in token sampling during inference. As an additional benefit, we find that smaller latent spaces lead to MVQ identifying transferable visual representations where multiple can be smoothly combined.