 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFree Lunch for Pass@$k$? Low Cost Diverse Sampling for Diffusion Language Models
Mar 05, 2026Diverse outputs in text generation are necessary for effective exploration in complex reasoning tasks, such as code generation and mathematical problem solving. Such Pass@$k$ problems benefit from distinct candidates covering the solution space. However, traditional sampling approaches often waste computational resources on repetitive failure modes. While Diffusion Language Models have emerged as a competitive alternative to the prevailing Autoregressive paradigm, they remain susceptible to this redundancy, with independent samples frequently collapsing into similar modes. To address this, we propose a training free, low cost intervention to enhance generative diversity in Diffusion Language Models. Our approach modifies intermediate samples in a batch sequentially, where each sample is repelled from the feature space of previous samples, actively penalising redundancy. Unlike prior methods that require retraining or beam search, our strategy incurs negligible computational overhead, while ensuring that each sample contributes a unique perspective to the batch. We evaluate our method on the HumanEval and GSM8K benchmarks using the LLaDA-8B-Instruct model. Our results demonstrate significantly improved diversity and Pass@$k$ performance across various temperature settings. As a simple modification to the sampling process, our method offers an immediate, low-cost improvement for current and future Diffusion Language Models in tasks that benefit from diverse solution search. We make our code available at https://github.com/sean-lamont/odd.
Pass@K Policy Optimization: Solving Harder Reinforcement Learning Problems
May 21, 2025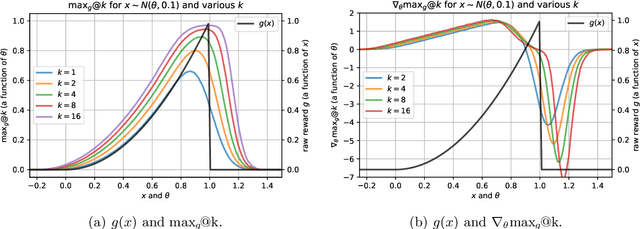
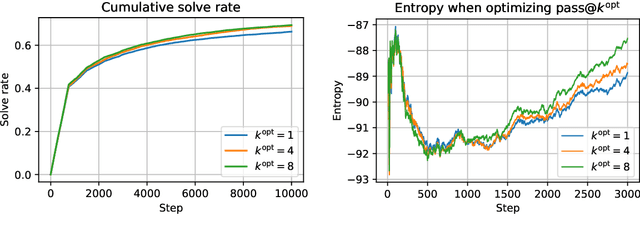
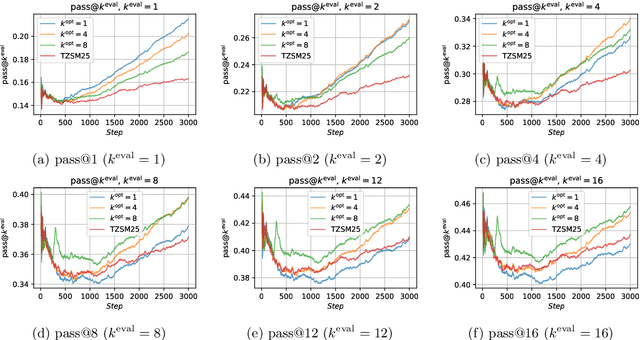
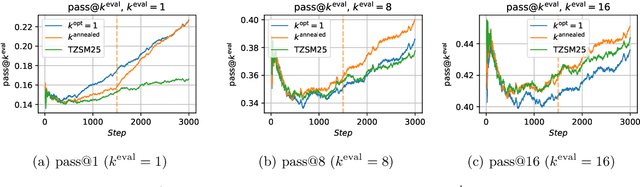
Reinforcement Learning (RL) algorithms sample multiple n>1 solution attempts for each problem and reward them independently. This optimizes for pass@1 performance and prioritizes the strength of isolated samples at the expense of the diversity and collective utility of sets of samples. This under-utilizes the sampling capacity, limiting exploration and eventual improvement on harder examples. As a fix, we propose Pass-at-k Policy Optimization (PKPO), a transformation on the final rewards which leads to direct optimization of pass@k performance, thus optimizing for sets of samples that maximize reward when considered jointly. Our contribution is to derive novel low variance unbiased estimators for pass@k and its gradient, in both the binary and continuous reward settings. We show optimization with our estimators reduces to standard RL with rewards that have been jointly transformed by a stable and efficient transformation function. While previous efforts are restricted to k=n, ours is the first to enable robust optimization of pass@k for any arbitrary k <= n. Moreover, instead of trading off pass@1 performance for pass@k gains, our method allows annealing k during training, optimizing both metrics and often achieving strong pass@1 numbers alongside significant pass@k gains. We validate our reward transformations on toy experiments, which reveal the variance reducing properties of our formulations. We also include real-world examples using the open-source LLM, GEMMA-2. We find that our transformation effectively optimizes for the target k. Furthermore, higher k values enable solving more and harder problems, while annealing k boosts both the pass@1 and pass@k . Crucially, for challenging task sets where conventional pass@1 optimization stalls, our pass@k approach unblocks learning, likely due to better exploration by prioritizing joint utility over the utility of individual samples.
A Universal Sets-level Optimization Framework for Next Set Recommendation
Oct 30, 2024Next Set Recommendation (NSRec), encompassing related tasks such as next basket recommendation and temporal sets prediction, stands as a trending research topic. Although numerous attempts have been made on this topic, there are certain drawbacks: (i) Existing studies are still confined to utilizing objective functions commonly found in Next Item Recommendation (NIRec), such as binary cross entropy and BPR, which are calculated based on individual item comparisons; (ii) They place emphasis on building sophisticated learning models to capture intricate dependency relationships across sequential sets, but frequently overlook pivotal dependency in their objective functions; (iii) Diversity factor within sequential sets is frequently overlooked. In this research, we endeavor to unveil a universal and S ets-level optimization framework for N ext Set Recommendation (SNSRec), offering a holistic fusion of diversity distribution and intricate dependency relationships within temporal sets. To realize this, the following contributions are made: (i) We directly model the temporal set in a sequence as a cohesive entity, leveraging the Structured Determinantal Point Process (SDPP), wherein the probabilistic DPP distribution prioritizes collections of structures (sequential sets) instead of individual items; (ii) We introduce a co-occurrence representation to discern and acknowledge the importance of different sets; (iii) We propose a sets-level optimization criterion, which integrates the diversity distribution and dependency relations across the entire sequence of sets, guiding the model to recommend relevant and diversified set. Extensive experiments on real-world datasets show that our approach consistently outperforms previous methods on both relevance and diversity.
3D-Prover: Diversity Driven Theorem Proving With Determinantal Point Processes
Oct 14, 2024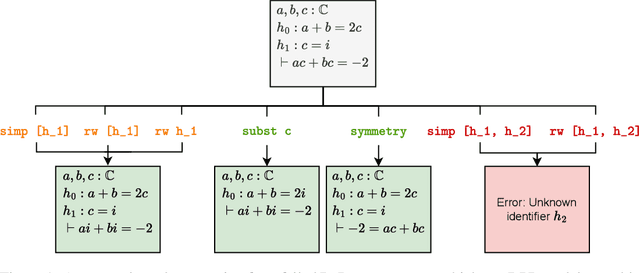

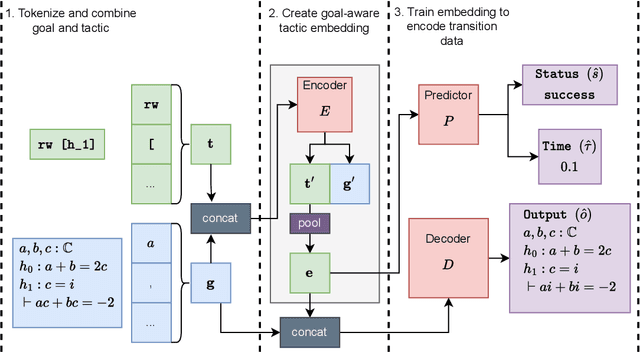

A key challenge in automated formal reasoning is the intractable search space, which grows exponentially with the depth of the proof. This branching is caused by the large number of candidate proof tactics which can be applied to a given goal. Nonetheless, many of these tactics are semantically similar or lead to an execution error, wasting valuable resources in both cases. We address the problem of effectively pruning this search, using only synthetic data generated from previous proof attempts. We first demonstrate that it is possible to generate semantically aware tactic representations which capture the effect on the proving environment, likelihood of success and execution time. We then propose a novel filtering mechanism which leverages these representations to select semantically diverse and high quality tactics, using Determinantal Point Processes. Our approach, 3D-Prover, is designed to be general, and to augment any underlying tactic generator. We demonstrate the effectiveness of 3D-Prover on the miniF2F-valid and miniF2F-test benchmarks by augmenting the ReProver LLM. We show that our approach leads to an increase in the overall proof rate, as well as a significant improvement in the tactic success rate, execution time and diversity.
Learning k-Determinantal Point Processes for Personalized Ranking
Jun 23, 2024The key to personalized recommendation is to predict a personalized ranking on a catalog of items by modeling the user's preferences. There are many personalized ranking approaches for item recommendation from implicit feedback like Bayesian Personalized Ranking (BPR) and listwise ranking. Despite these methods have shown performance benefits, there are still limitations affecting recommendation performance. First, none of them directly optimize ranking of sets, causing inadequate exploitation of correlations among multiple items. Second, the diversity aspect of recommendations is insufficiently addressed compared to relevance. In this work, we present a new optimization criterion LkP based on set probability comparison for personalized ranking that moves beyond traditional ranking-based methods. It formalizes set-level relevance and diversity ranking comparisons through a Determinantal Point Process (DPP) kernel decomposition. To confer ranking interpretability to the DPP set probabilities and prioritize the practicality of LkP, we condition the standard DPP on the cardinality k of the DPP-distributed set, known as k-DPP, a less-explored extension of DPP. The generic stochastic gradient descent based technique can be directly applied to optimizing models that employ LkP. We implement LkP in the context of both Matrix Factorization (MF) and neural networks approaches, on three real-world datasets, obtaining improved relevance and diversity performances. LkP is broadly applicable, and when applied to existing recommendation models it also yields strong performance improvements, suggesting that LkP holds significant value to the field of recommender systems.
SoundLoCD: An Efficient Conditional Discrete Contrastive Latent Diffusion Model for Text-to-Sound Generation
May 24, 2024
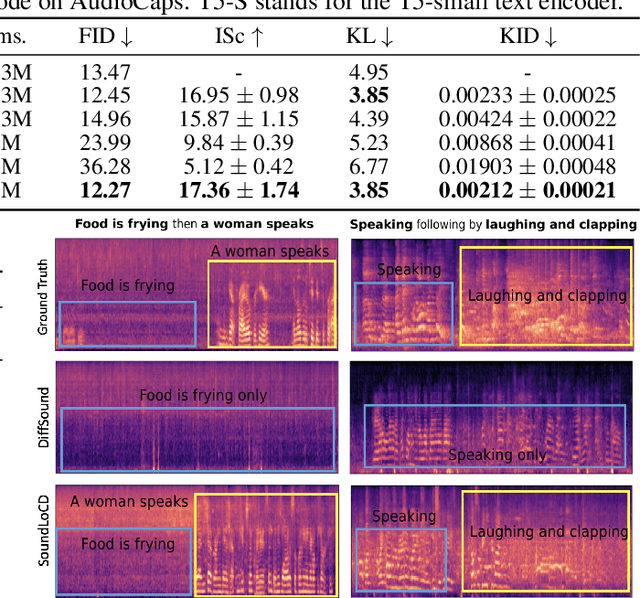

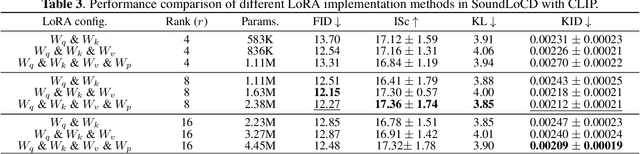
We present SoundLoCD, a novel text-to-sound generation framework, which incorporates a LoRA-based conditional discrete contrastive latent diffusion model. Unlike recent large-scale sound generation models, our model can be efficiently trained under limited computational resources. The integration of a contrastive learning strategy further enhances the connection between text conditions and the generated outputs, resulting in coherent and high-fidelity performance. Our experiments demonstrate that SoundLoCD outperforms the baseline with greatly reduced computational resources. A comprehensive ablation study further validates the contribution of each component within SoundLoCD. Demo page: \url{https://XinleiNIU.github.io/demo-SoundLoCD/}.
BAIT: Benchmarking (Embedding) Architectures for Interactive Theorem-Proving
Mar 06, 2024Artificial Intelligence for Theorem Proving has given rise to a plethora of benchmarks and methodologies, particularly in Interactive Theorem Proving (ITP). Research in the area is fragmented, with a diverse set of approaches being spread across several ITP systems. This presents a significant challenge to the comparison of methods, which are often complex and difficult to replicate. Addressing this, we present BAIT, a framework for fair and streamlined comparison of learning approaches in ITP. We demonstrate BAIT's capabilities with an in-depth comparison, across several ITP benchmarks, of state-of-the-art architectures applied to the problem of formula embedding. We find that Structure Aware Transformers perform particularly well, improving on techniques associated with the original problem sets. BAIT also allows us to assess the end-to-end proving performance of systems built on interactive environments. This unified perspective reveals a novel end-to-end system that improves on prior work. We also provide a qualitative analysis, illustrating that improved performance is associated with more semantically-aware embeddings. By streamlining the implementation and comparison of Machine Learning algorithms in the ITP context, we anticipate BAIT will be a springboard for future research.
Latent Optimal Paths by Gumbel Propagation for Variational Bayesian Dynamic Programming
Jun 05, 2023
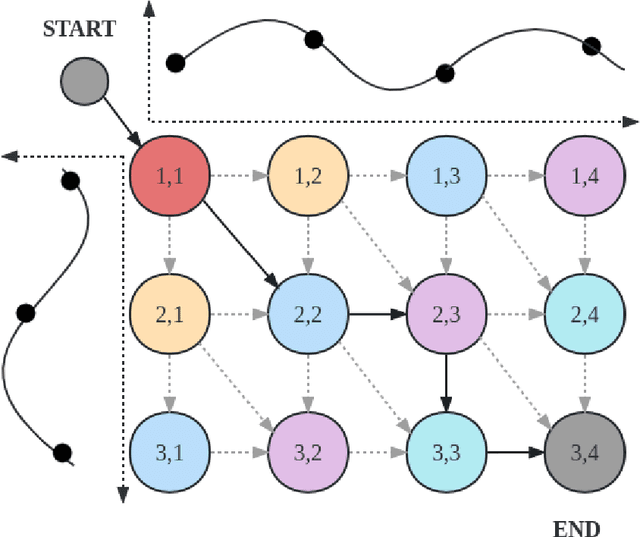


We propose a unified approach to obtain structured sparse optimal paths in the latent space of a variational autoencoder (VAE) using dynamic programming and Gumbel propagation. We solve the classical optimal path problem by a probability softening solution, called the stochastic optimal path, and transform a wide range of DP problems into directed acyclic graphs in which all possible paths follow a Gibbs distribution. We show the equivalence of the Gibbs distribution to a message-passing algorithm by the properties of the Gumbel distribution and give all the ingredients required for variational Bayesian inference. Our approach obtaining latent optimal paths enables end-to-end training for generative tasks in which models rely on the information of unobserved structural features. We validate the behavior of our approach and showcase its applicability in two real-world applications: text-to-speech and singing voice synthesis.
DualVAE: Controlling Colours of Generated and Real Images
May 30, 2023


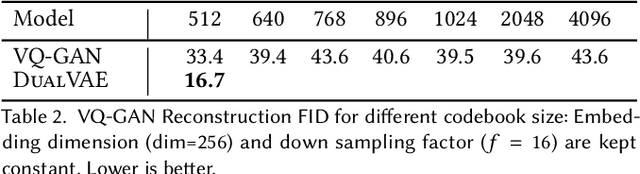
Colour controlled image generation and manipulation are of interest to artists and graphic designers. Vector Quantised Variational AutoEncoders (VQ-VAEs) with autoregressive (AR) prior are able to produce high quality images, but lack an explicit representation mechanism to control colour attributes. We introduce DualVAE, a hybrid representation model that provides such control by learning disentangled representations for colour and geometry. The geometry is represented by an image intensity mapping that identifies structural features. The disentangled representation is obtained by two novel mechanisms: (i) a dual branch architecture that separates image colour attributes from geometric attributes, and (ii) a new ELBO that trains the combined colour and geometry representations. DualVAE can control the colour of generated images, and recolour existing images by transferring the colour latent representation obtained from an exemplar image. We demonstrate that DualVAE generates images with FID nearly two times better than VQ-GAN on a diverse collection of datasets, including animated faces, logos and artistic landscapes.
R-U-SURE? Uncertainty-Aware Code Suggestions By Maximizing Utility Across Random User Intents
Mar 01, 2023



Large language models show impressive results at predicting structured text such as code, but also commonly introduce errors and hallucinations in their output. When used to assist software developers, these models may make mistakes that users must go back and fix, or worse, introduce subtle bugs that users may miss entirely. We propose Randomized Utility-driven Synthesis of Uncertain REgions (R-U-SURE), an approach for building uncertainty-aware suggestions based on a decision-theoretic model of goal-conditioned utility, using random samples from a generative model as a proxy for the unobserved possible intents of the end user. Our technique combines minimum-Bayes-risk decoding, dual decomposition, and decision diagrams in order to efficiently produce structured uncertainty summaries, given only sample access to an arbitrary generative model of code and an optional AST parser. We demonstrate R-U-SURE on three developer-assistance tasks, and show that it can be applied different user interaction patterns without retraining the model and leads to more accurate uncertainty estimates than token-probability baselines.