 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOther Vehicle Trajectories Are Also Needed: A Driving World Model Unifies Ego-Other Vehicle Trajectories in Video Latant Space
Mar 12, 2025Advanced end-to-end autonomous driving systems predict other vehicles' motions and plan ego vehicle's trajectory. The world model that can foresee the outcome of the trajectory has been used to evaluate the end-to-end autonomous driving system. However, existing world models predominantly emphasize the trajectory of the ego vehicle and leave other vehicles uncontrollable. This limitation hinders their ability to realistically simulate the interaction between the ego vehicle and the driving scenario. In addition, it remains a challenge to match multiple trajectories with each vehicle in the video to control the video generation. To address above issues, a driving \textbf{W}orld \textbf{M}odel named EOT-WM is proposed in this paper, unifying \textbf{E}go-\textbf{O}ther vehicle \textbf{T}rajectories in videos. Specifically, we first project ego and other vehicle trajectories in the BEV space into the image coordinate to match each trajectory with its corresponding vehicle in the video. Then, trajectory videos are encoded by the Spatial-Temporal Variational Auto Encoder to align with driving video latents spatially and temporally in the unified visual space. A trajectory-injected diffusion Transformer is further designed to denoise the noisy video latents for video generation with the guidance of ego-other vehicle trajectories. In addition, we propose a metric based on control latent similarity to evaluate the controllability of trajectories. Extensive experiments are conducted on the nuScenes dataset, and the proposed model outperforms the state-of-the-art method by 30\% in FID and 55\% in FVD. The model can also predict unseen driving scenes with self-produced trajectories.
CO2: Efficient Distributed Training with Full Communication-Computation Overlap
Jan 29, 2024The fundamental success of large language models hinges upon the efficacious implementation of large-scale distributed training techniques. Nevertheless, building a vast, high-performance cluster featuring high-speed communication interconnectivity is prohibitively costly, and accessible only to prominent entities. In this work, we aim to lower this barrier and democratize large-scale training with limited bandwidth clusters. We propose a new approach called CO2 that introduces local-updating and asynchronous communication to the distributed data-parallel training, thereby facilitating the full overlap of COmunication with COmputation. CO2 is able to attain a high scalability even on extensive multi-node clusters constrained by very limited communication bandwidth. We further propose the staleness gap penalty and outer momentum clipping techniques together with CO2 to bolster its convergence and training stability. Besides, CO2 exhibits seamless integration with well-established ZeRO-series optimizers which mitigate memory consumption of model states with large model training. We also provide a mathematical proof of convergence, accompanied by the establishment of a stringent upper bound. Furthermore, we validate our findings through an extensive set of practical experiments encompassing a wide range of tasks in the fields of computer vision and natural language processing. These experiments serve to demonstrate the capabilities of CO2 in terms of convergence, generalization, and scalability when deployed across configurations comprising up to 128 A100 GPUs. The outcomes emphasize the outstanding capacity of CO2 to hugely improve scalability, no matter on clusters with 800Gbps RDMA or 80Gbps TCP/IP inter-node connections.
Sampled Transformer for Point Sets
Feb 28, 2023The sparse transformer can reduce the computational complexity of the self-attention layers to $O(n)$, whilst still being a universal approximator of continuous sequence-to-sequence functions. However, this permutation variant operation is not appropriate for direct application to sets. In this paper, we proposed an $O(n)$ complexity sampled transformer that can process point set elements directly without any additional inductive bias. Our sampled transformer introduces random element sampling, which randomly splits point sets into subsets, followed by applying a shared Hamiltonian self-attention mechanism to each subset. The overall attention mechanism can be viewed as a Hamiltonian cycle in the complete attention graph, and the permutation of point set elements is equivalent to randomly sampling Hamiltonian cycles. This mechanism implements a Monte Carlo simulation of the $O(n^2)$ dense attention connections. We show that it is a universal approximator for continuous set-to-set functions. Experimental results on point-clouds show comparable or better accuracy with significantly reduced computational complexity compared to the dense transformer or alternative sparse attention schemes.
SPA-VAE: Similar-Parts-Assignment for Unsupervised 3D Point Cloud Generation
Mar 15, 2022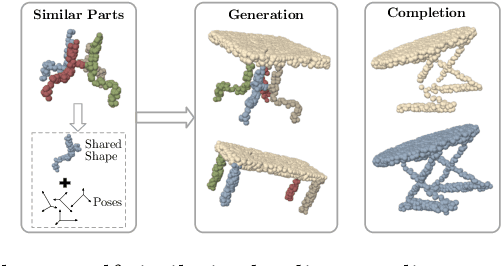
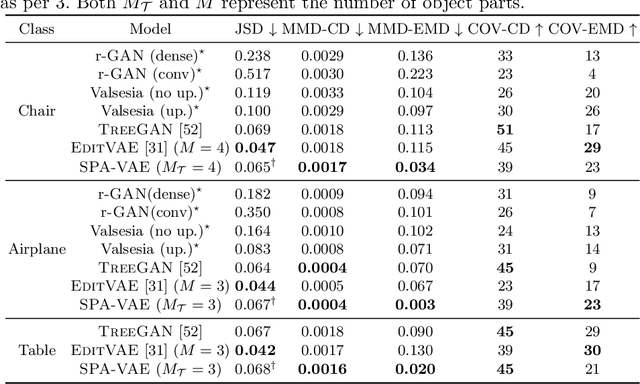

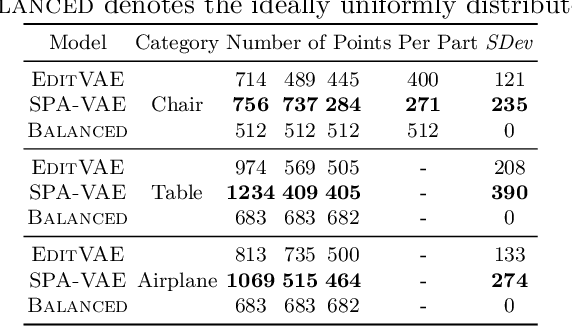
This paper addresses the problem of unsupervised parts-aware point cloud generation with learned parts-based self-similarity. Our SPA-VAE infers a set of latent canonical candidate shapes for any given object, along with a set of rigid body transformations for each such candidate shape to one or more locations within the assembled object. In this way, noisy samples on the surface of, say, each leg of a table, are effectively combined to estimate a single leg prototype. When parts-based self-similarity exists in the raw data, sharing data among parts in this way confers numerous advantages: modeling accuracy, appropriately self-similar generative outputs, precise in-filling of occlusions, and model parsimony. SPA-VAE is trained end-to-end using a variational Bayesian approach which uses the Gumbel-softmax trick for the shared part assignments, along with various novel losses to provide appropriate inductive biases. Quantitative and qualitative analyses on ShapeNet demonstrate the advantage of SPA-VAE.
EditVAE: Unsupervised Part-Aware Controllable 3D Point Cloud Shape Generation
Oct 13, 2021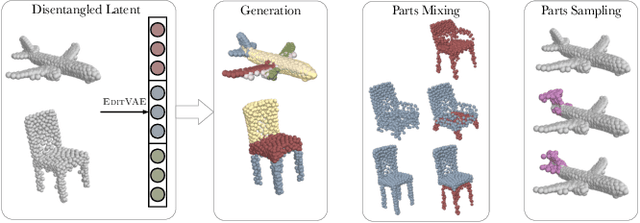
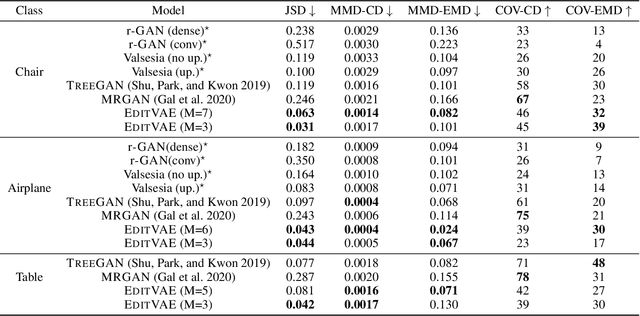
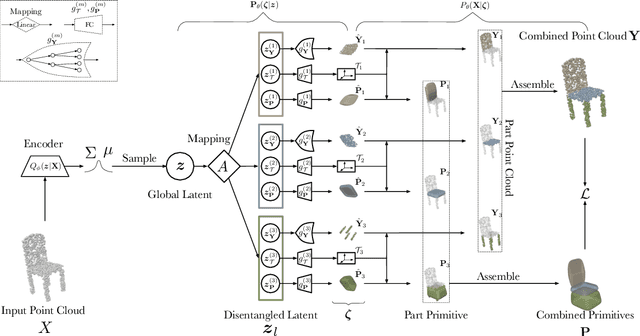

This paper tackles the problem of parts-aware point cloud generation. Unlike existing works which require the point cloud to be segmented into parts a priori, our parts-aware editing and generation is performed in an unsupervised manner. We achieve this with a simple modification of the Variational Auto-Encoder which yields a joint model of the point cloud itself along with a schematic representation of it as a combination of shape primitives. In particular, we introduce a latent representation of the point cloud which can be decomposed into a disentangled representation for each part of the shape. These parts are in turn disentangled into both a shape primitive and a point cloud representation, along with a standardising transformation to a canonical coordinate system. The dependencies between our standardising transformations preserve the spatial dependencies between the parts in a manner which allows meaningful parts-aware point cloud generation and shape editing. In addition to the flexibility afforded by our disentangled representation, the inductive bias introduced by our joint modelling approach yields the state-of-the-art experimental results on the ShapeNet dataset.
Interval-censored Hawkes processes
Apr 16, 2021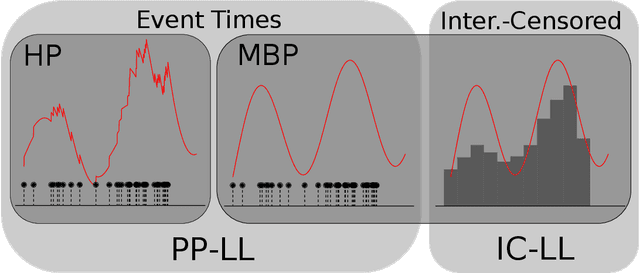
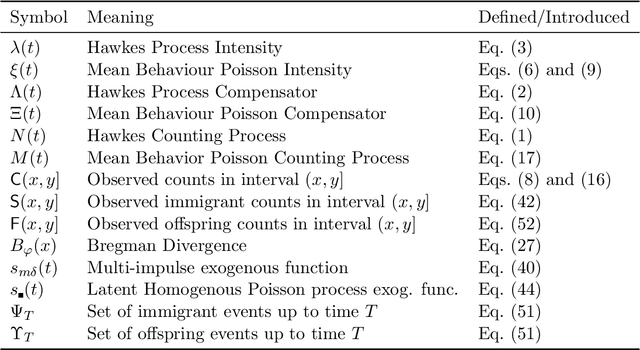
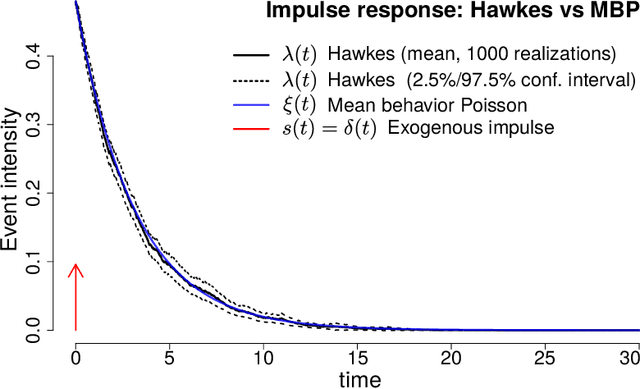
Hawkes processes are a popular means of modeling the event times of self-exciting phenomena, such as earthquake strikes or tweets on a topical subject. Classically, these models are fit to historical event time data via likelihood maximization. However, in many scenarios, the exact times of historical events are not recorded for either privacy (e.g., patient admittance to hospitals) or technical limitations (e.g., most transport data records the volume of vehicles passing loop detectors but not the individual times). The interval-censored setting denotes when only the aggregate counts of events at specific time intervals are observed. Fitting the parameters of interval-censored Hawkes processes requires designing new training objectives that do not rely on the exact event times. In this paper, we propose a model to estimate the parameters of a Hawkes process in interval-censored settings. Our model builds upon the existing Hawkes Intensity Process (HIP) of in several important directions. First, we observe that while HIP is formulated in terms of expected intensities, it is more natural to work instead with expected counts; further, one can express the latter as the solution to an integral equation closely related to the defining equation of HIP. Second, we show how a non-homogeneous Poisson approximation to the Hawkes process admits a tractable likelihood in the interval-censored setting; this approximation recovers the original HIP objective as a special case, and allows for the use of a broader class of Bregman divergences as loss function. Third, we explicate how to compute a tighter approximation to the ground truth in the likelihood. Finally, we show how our model can incorporate information about varying interval lengths. Experiments on synthetic and real-world data confirm our HIPPer model outperforms HIP and several other baselines on the task of interval-censored inference.
Robot Playing Kendama with Model-Based and Model-Free Reinforcement Learning
Mar 15, 2020
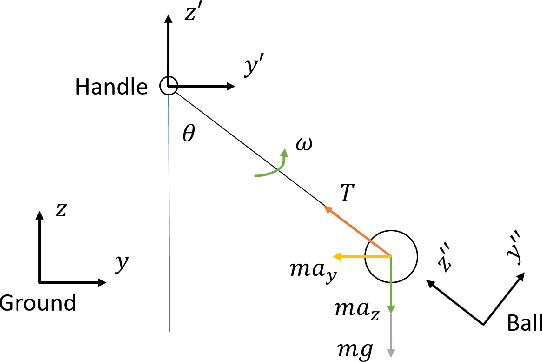
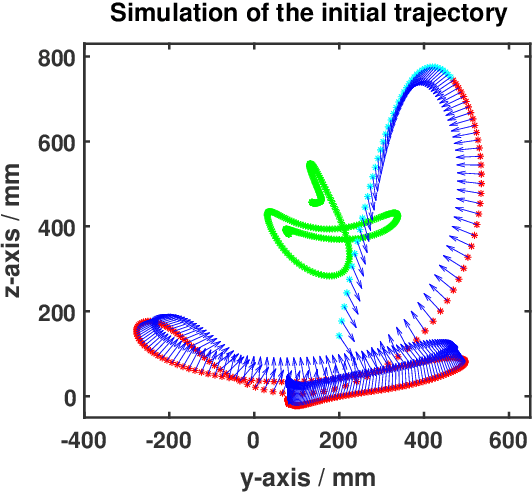
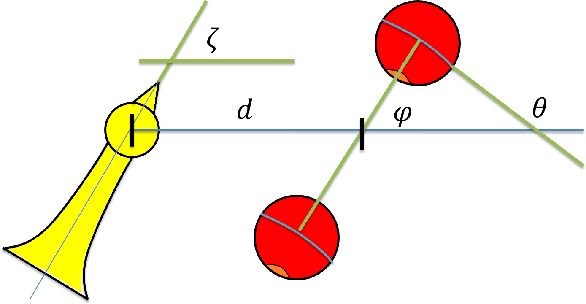
Several model-based and model-free methods have been proposed for the robot trajectory learning task. Both approaches have their benefits and drawbacks. They can usually complement each other. Many research works are trying to integrate some model-based and model-free methods into one algorithm and perform well in simulators or quasi-static robot tasks. Difficulties still exist when algorithms are used in particular trajectory learning tasks. In this paper, we propose a robot trajectory learning framework for precise tasks with discontinuous dynamics and high speed. The trajectories learned from the human demonstration are optimized by DDP and PoWER successively. The framework is tested on the Kendama manipulation task, which can also be difficult for humans to achieve. The results show that our approach can plan the trajectories to successfully complete the task.
Smooth and Efficient Policy Exploration for Robot Trajectory Learning
Aug 10, 2018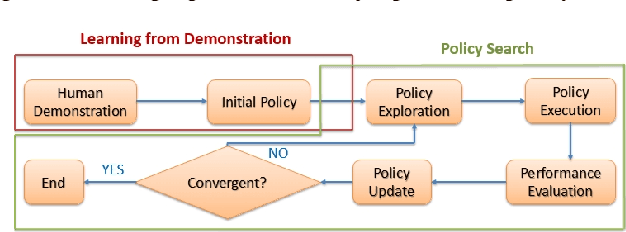
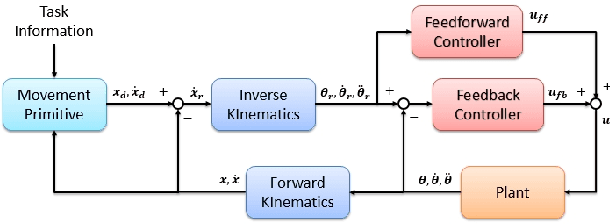


Many policy search algorithms have been proposed for robot learning and proved to be practical in real robot applications. However, there are still hyperparameters in the algorithms, such as the exploration rate, which requires manual tuning. The existing methods to design the exploration rate manually or automatically may not be general enough or hard to apply in the real robot. In this paper, we propose a learning model to update the exploration rate adaptively. The overall algorithm is a combination of methods proposed by other researchers. Smooth trajectories for the robot can be produced by the algorithm and the updated exploration rate maximizes the lower bound of the expected return. Our method is tested in the ball-in-cup problem. The results show that our method can receive the same learning outcome as the previous methods but with fewer iterations.