 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEditVAE: Unsupervised Part-Aware Controllable 3D Point Cloud Shape Generation
Paper and Code
Oct 13, 2021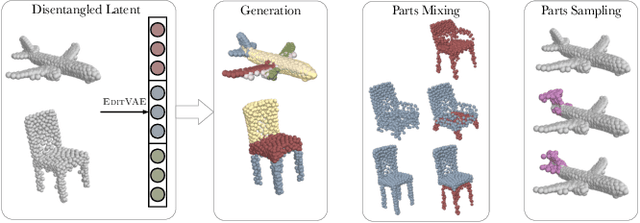
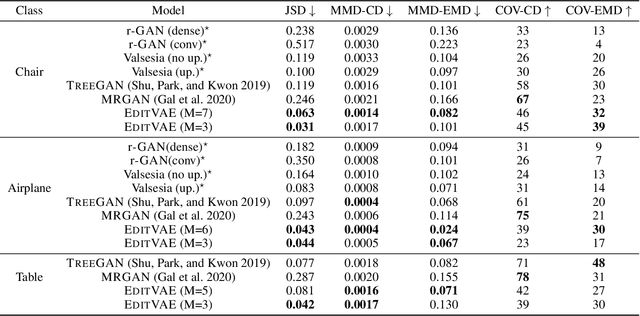
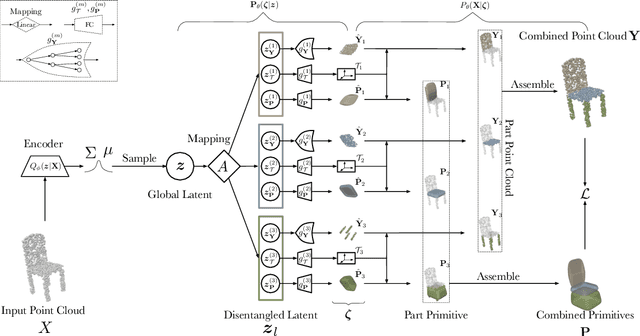

This paper tackles the problem of parts-aware point cloud generation. Unlike existing works which require the point cloud to be segmented into parts a priori, our parts-aware editing and generation is performed in an unsupervised manner. We achieve this with a simple modification of the Variational Auto-Encoder which yields a joint model of the point cloud itself along with a schematic representation of it as a combination of shape primitives. In particular, we introduce a latent representation of the point cloud which can be decomposed into a disentangled representation for each part of the shape. These parts are in turn disentangled into both a shape primitive and a point cloud representation, along with a standardising transformation to a canonical coordinate system. The dependencies between our standardising transformations preserve the spatial dependencies between the parts in a manner which allows meaningful parts-aware point cloud generation and shape editing. In addition to the flexibility afforded by our disentangled representation, the inductive bias introduced by our joint modelling approach yields the state-of-the-art experimental results on the ShapeNet dataset.