 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmooth and Efficient Policy Exploration for Robot Trajectory Learning
Aug 10, 2018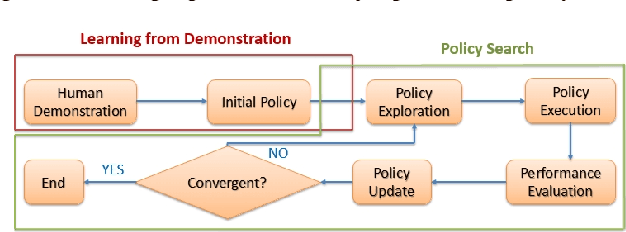
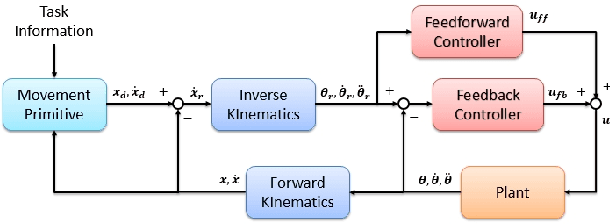


Many policy search algorithms have been proposed for robot learning and proved to be practical in real robot applications. However, there are still hyperparameters in the algorithms, such as the exploration rate, which requires manual tuning. The existing methods to design the exploration rate manually or automatically may not be general enough or hard to apply in the real robot. In this paper, we propose a learning model to update the exploration rate adaptively. The overall algorithm is a combination of methods proposed by other researchers. Smooth trajectories for the robot can be produced by the algorithm and the updated exploration rate maximizes the lower bound of the expected return. Our method is tested in the ball-in-cup problem. The results show that our method can receive the same learning outcome as the previous methods but with fewer iterations.