 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransParking: A Dual-Decoder Transformer Framework with Soft Localization for End-to-End Automatic Parking
Mar 08, 2025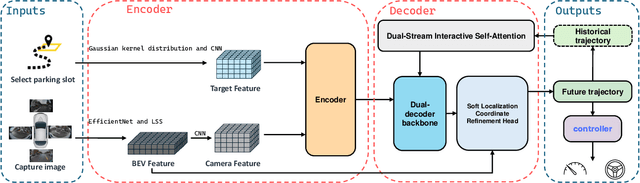
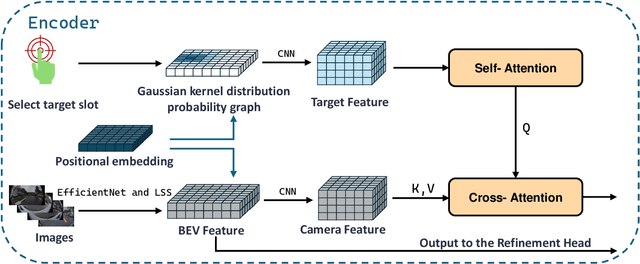
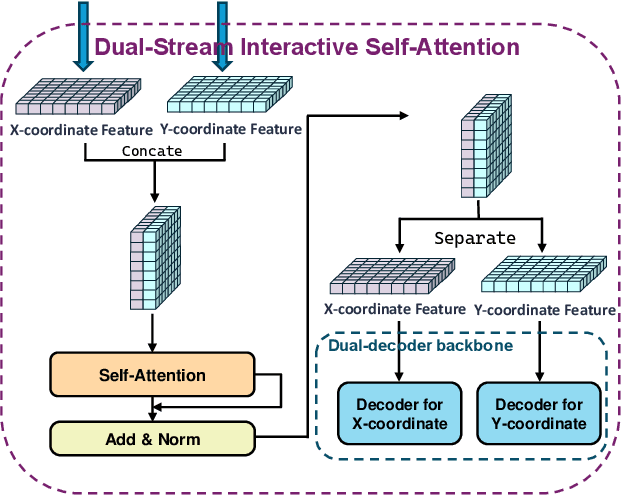
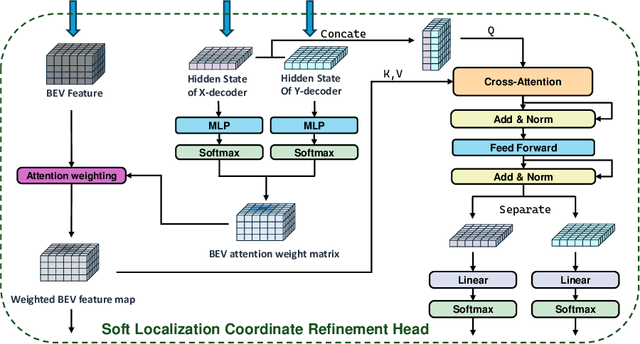
In recent years, fully differentiable end-to-end autonomous driving systems have become a research hotspot in the field of intelligent transportation. Among various research directions, automatic parking is particularly critical as it aims to enable precise vehicle parking in complex environments. In this paper, we present a purely vision-based transformer model for end-to-end automatic parking, trained using expert trajectories. Given camera-captured data as input, the proposed model directly outputs future trajectory coordinates. Experimental results demonstrate that the various errors of our model have decreased by approximately 50% in comparison with the current state-of-the-art end-to-end trajectory prediction algorithm of the same type. Our approach thus provides an effective solution for fully differentiable automatic parking.
Multi-Robot Reliable Navigation in Uncertain Topological Environments with Graph Attention Networks
Nov 25, 2024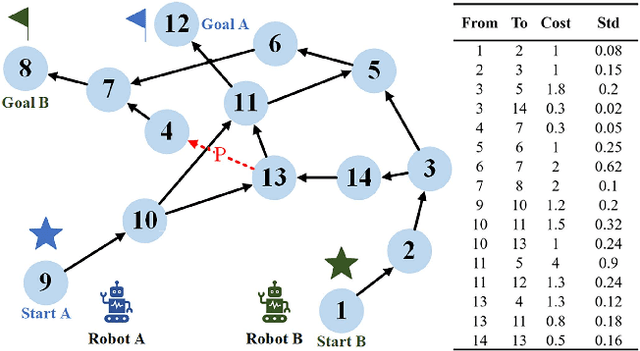
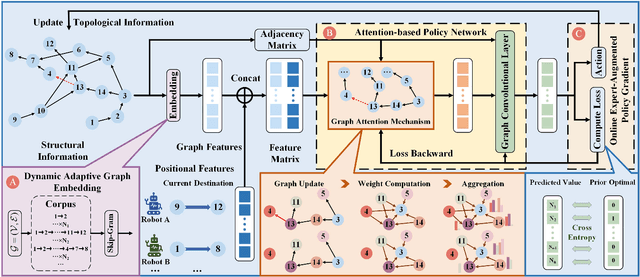
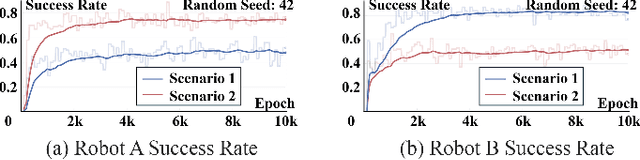
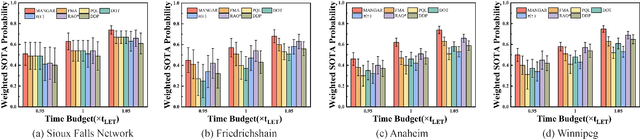
This paper studies the multi-robot reliable navigation problem in uncertain topological networks, which aims at maximizing the robot team's on-time arrival probabilities in the face of road network uncertainties. The uncertainty in these networks stems from the unknown edge traversability, which is only revealed to the robot upon its arrival at the edge's starting node. Existing approaches often struggle to adapt to real-time network topology changes, making them unsuitable for varying topological environments. To address the challenge, we reformulate the problem into a Partially Observable Markov Decision Process (POMDP) framework and introduce the Dynamic Adaptive Graph Embedding method to capture the evolving nature of the navigation task. We further enhance each robot's policy learning process by integrating deep reinforcement learning with Graph Attention Networks (GATs), leveraging self-attention to focus on critical graph features. The proposed approach, namely Multi-Agent Routing in Variable Environments with Learning (MARVEL) employs the generalized policy gradient algorithm to optimize the robots' real-time decision-making process iteratively. We compare the performance of MARVEL with state-of-the-art reliable navigation algorithms as well as Canadian traveller problem solutions in a range of canonical transportation networks, demonstrating improved adaptability and performance in uncertain topological networks. Additionally, real-world experiments with two robots navigating within a self-constructed indoor environment with uncertain topological structures demonstrate MARVEL's practicality.
Real-time Digital Double Framework to Predict Collapsible Terrains for Legged Robots
Sep 20, 2022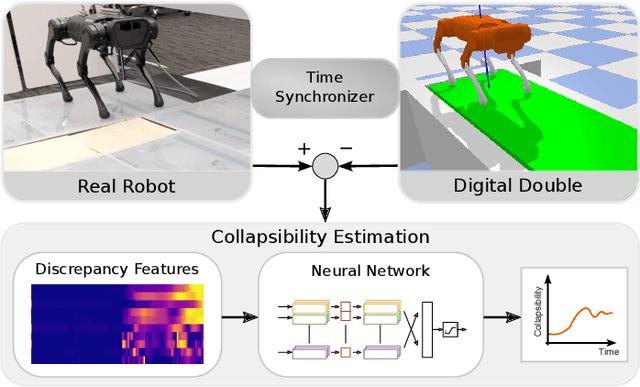
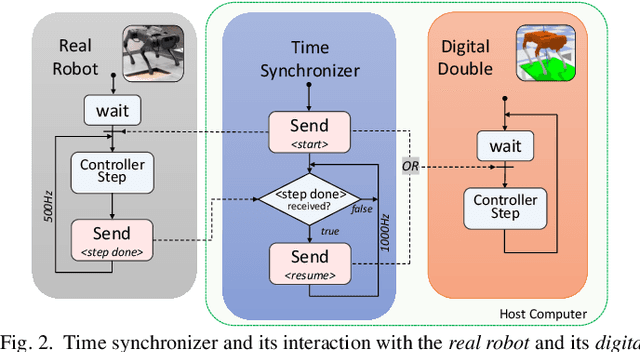
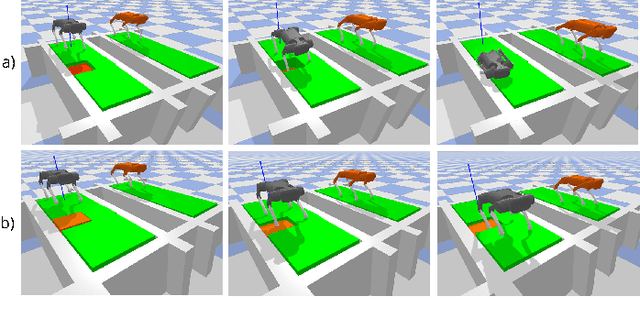
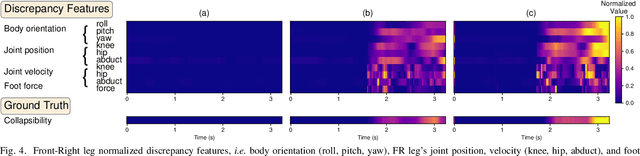
Inspired by the digital twinning systems, a novel real-time digital double framework is developed to enhance robot perception of the terrain conditions. Based on the very same physical model and motion control, this work exploits the use of such simulated digital double synchronized with a real robot to capture and extract discrepancy information between the two systems, which provides high dimensional cues in multiple physical quantities to represent differences between the modelled and the real world. Soft, non-rigid terrains cause common failures in legged locomotion, whereby visual perception solely is insufficient in estimating such physical properties of terrains. We used digital double to develop the estimation of the collapsibility, which addressed this issue through physical interactions during dynamic walking. The discrepancy in sensory measurements between the real robot and its digital double are used as input of a learning-based algorithm for terrain collapsibility analysis. Although trained only in simulation, the learned model can perform collapsibility estimation successfully in both simulation and real world. Our evaluation of results showed the generalization to different scenarios and the advantages of the digital double to reliably detect nuances in ground conditions.
PointAtrousGraph: Deep Hierarchical Encoder-Decoder with Atrous Convolution for Point Clouds
Jul 23, 2019



Motivated by the success of encoding multi-scale contextual information for image analysis, we present our PointAtrousGraph (PAG) - a deep permutation-invariant hierarchical encoder-decoder architecture for learning multi-scale edge features in unorganized 3D points. Our PAG is constructed by several novel modules, such as point atrous convolution, edge-preserved pooling and edge-preserved unpooling. Similar with atrous convolution, our point atrous convolution can effectively enlarge the receptive fields of filters for learning point features without increasing computation amount. Following the idea of non-overlapping max-pooling operation, we propose our edge-preserved pooling to preserve critical edge features during subsampling. In a similar spirit, our edge-preserved unpooling propagates high-dimensional edge features while recovering the spatial information. In addition, we introduce chained skip subsampling/upsampling modules to directly propagate edge features from different hierarchies to the final stage. Experimental results show that our PAG achieves better performance compared to previous state-of-the-art methods in various applications.
Smooth and Efficient Policy Exploration for Robot Trajectory Learning
Aug 10, 2018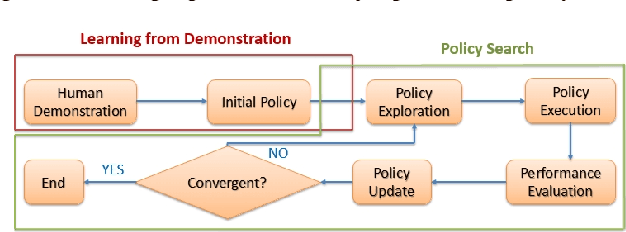
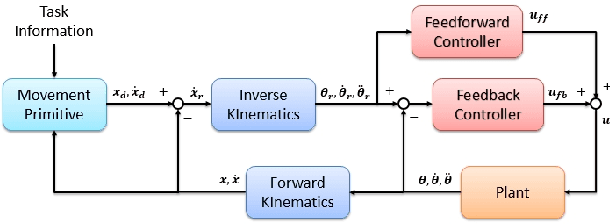


Many policy search algorithms have been proposed for robot learning and proved to be practical in real robot applications. However, there are still hyperparameters in the algorithms, such as the exploration rate, which requires manual tuning. The existing methods to design the exploration rate manually or automatically may not be general enough or hard to apply in the real robot. In this paper, we propose a learning model to update the exploration rate adaptively. The overall algorithm is a combination of methods proposed by other researchers. Smooth trajectories for the robot can be produced by the algorithm and the updated exploration rate maximizes the lower bound of the expected return. Our method is tested in the ball-in-cup problem. The results show that our method can receive the same learning outcome as the previous methods but with fewer iterations.