 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Robot Reliable Navigation in Uncertain Topological Environments with Graph Attention Networks
Paper and Code
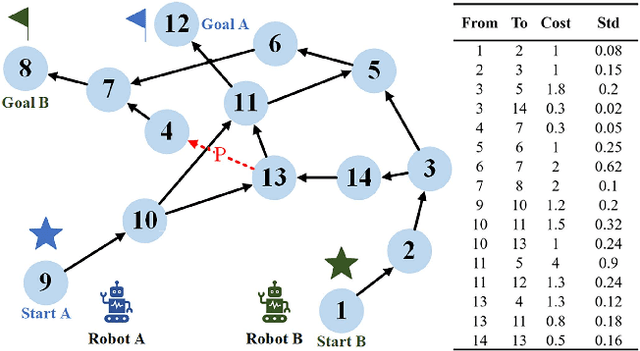
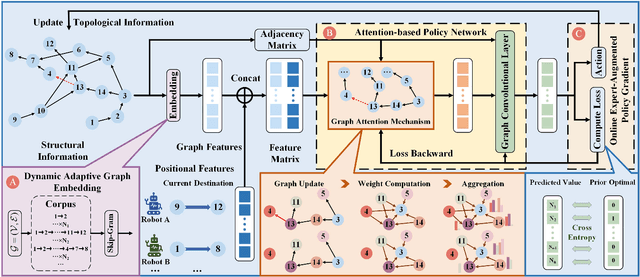
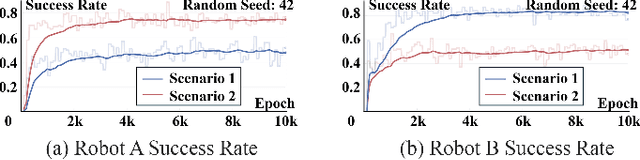
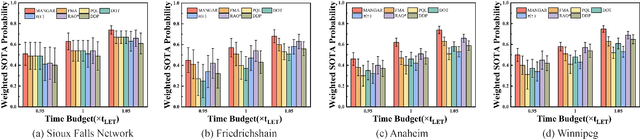
This paper studies the multi-robot reliable navigation problem in uncertain topological networks, which aims at maximizing the robot team's on-time arrival probabilities in the face of road network uncertainties. The uncertainty in these networks stems from the unknown edge traversability, which is only revealed to the robot upon its arrival at the edge's starting node. Existing approaches often struggle to adapt to real-time network topology changes, making them unsuitable for varying topological environments. To address the challenge, we reformulate the problem into a Partially Observable Markov Decision Process (POMDP) framework and introduce the Dynamic Adaptive Graph Embedding method to capture the evolving nature of the navigation task. We further enhance each robot's policy learning process by integrating deep reinforcement learning with Graph Attention Networks (GATs), leveraging self-attention to focus on critical graph features. The proposed approach, namely Multi-Agent Routing in Variable Environments with Learning (MARVEL) employs the generalized policy gradient algorithm to optimize the robots' real-time decision-making process iteratively. We compare the performance of MARVEL with state-of-the-art reliable navigation algorithms as well as Canadian traveller problem solutions in a range of canonical transportation networks, demonstrating improved adaptability and performance in uncertain topological networks. Additionally, real-world experiments with two robots navigating within a self-constructed indoor environment with uncertain topological structures demonstrate MARVEL's practicality.