 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing large language models for embodied planning introduces systematic safety risks
Apr 20, 2026Large language models are increasingly used as planners for robotic systems, yet how safely they plan remains an open question. To evaluate safe planning systematically, we introduce DESPITE, a benchmark of 12,279 tasks spanning physical and normative dangers with fully deterministic validation. Across 23 models, even near-perfect planning ability does not ensure safety: the best-planning model fails to produce a valid plan on only 0.4% of tasks but produces dangerous plans on 28.3%. Among 18 open-source models from 3B to 671B parameters, planning ability improves substantially with scale (0.4-99.3%) while safety awareness remains relatively flat (38-57%). We identify a multiplicative relationship between these two capacities, showing that larger models complete more tasks safely primarily through improved planning, not through better danger avoidance. Three proprietary reasoning models reach notably higher safety awareness (71-81%), while non-reasoning proprietary models and open-source reasoning models remain below 57%. As planning ability approaches saturation for frontier models, improving safety awareness becomes a central challenge for deploying language-model planners in robotic systems.
SCDP: Learning Humanoid Locomotion from Partial Observations via Mixed-Observation Distillation
Mar 10, 2026Distilling humanoid locomotion control from offline datasets into deployable policies remains a challenge, as existing methods rely on privileged full-body states that require complex and often unreliable state estimation. We present Sensor-Conditioned Diffusion Policies (SCDP) that enables humanoid locomotion using only onboard sensors, eliminating the need for explicit state estimation. SCDP decouples sensing from supervision through mixed-observation training: diffusion model conditions on sensor histories while being supervised to predict privileged future state-action trajectories, enforcing the model to infer the motion dynamics under partial observability. We further develop restricted denoising, context distribution alignment, and context-aware attention masking to encourage implicit state estimation within the model and to prevent train-deploy mismatch. We validate SCDP on velocity-commanded locomotion and motion reference tracking tasks. In simulation, SCDP achieves near-perfect success on velocity control (99-100%) and 93% tracking success in AMASS test set, performing comparable to privileged baselines while using only onboard sensors. Finally, we deploy the trained policy on a real G1 humanoid at 50 Hz, demonstrating robust real robot locomotion without external sensing or state estimation.
Closing the Reality Gap: Zero-Shot Sim-to-Real Deployment for Dexterous Force-Based Grasping and Manipulation
Jan 06, 2026Human-like dexterous hands with multiple fingers offer human-level manipulation capabilities, but training control policies that can directly deploy on real hardware remains difficult due to contact-rich physics and imperfect actuation. We close this gap with a practical sim-to-real reinforcement learning (RL) framework that utilizes dense tactile feedback combined with joint torque sensing to explicitly regulate physical interactions. To enable effective sim-to-real transfer, we introduce (i) a computationally fast tactile simulation that computes distances between dense virtual tactile units and the object via parallel forward kinematics, providing high-rate, high-resolution touch signals needed by RL; (ii) a current-to-torque calibration that eliminates the need for torque sensors on dexterous hands by mapping motor current to joint torque; and (iii) actuator dynamics modeling to bridge the actuation gaps with randomization of non-ideal effects such as backlash, torque-speed saturation. Using an asymmetric actor-critic PPO pipeline trained entirely in simulation, our policies deploy directly to a five-finger hand. The resulting policies demonstrated two essential skills: (1) command-based, controllable grasp force tracking, and (2) reorientation of objects in the hand, both of which were robustly executed without fine-tuning on the robot. By combining tactile and torque in the observation space with effective sensing/actuation modeling, our system provides a practical solution to achieve reliable dexterous manipulation. To our knowledge, this is the first demonstration of controllable grasping on a multi-finger dexterous hand trained entirely in simulation and transferred zero-shot on real hardware.
DemoBot: Efficient Learning of Bimanual Manipulation with Dexterous Hands From Third-Person Human Videos
Jan 04, 2026This work presents DemoBot, a learning framework that enables a dual-arm, multi-finger robotic system to acquire complex manipulation skills from a single unannotated RGB-D video demonstration. The method extracts structured motion trajectories of both hands and objects from raw video data. These trajectories serve as motion priors for a novel reinforcement learning (RL) pipeline that learns to refine them through contact-rich interactions, thereby eliminating the need to learn from scratch. To address the challenge of learning long-horizon manipulation skills, we introduce: (1) Temporal-segment based RL to enforce temporal alignment of the current state with demonstrations; (2) Success-Gated Reset strategy to balance the refinement of readily acquired skills and the exploration of subsequent task stages; and (3) Event-Driven Reward curriculum with adaptive thresholding to guide the RL learning of high-precision manipulation. The novel video processing and RL framework successfully achieved long-horizon synchronous and asynchronous bimanual assembly tasks, offering a scalable approach for direct skill acquisition from human videos.
Splatting Physical Scenes: End-to-End Real-to-Sim from Imperfect Robot Data
Jun 09, 2025Creating accurate, physical simulations directly from real-world robot motion holds great value for safe, scalable, and affordable robot learning, yet remains exceptionally challenging. Real robot data suffers from occlusions, noisy camera poses, dynamic scene elements, which hinder the creation of geometrically accurate and photorealistic digital twins of unseen objects. We introduce a novel real-to-sim framework tackling all these challenges at once. Our key insight is a hybrid scene representation merging the photorealistic rendering of 3D Gaussian Splatting with explicit object meshes suitable for physics simulation within a single representation. We propose an end-to-end optimization pipeline that leverages differentiable rendering and differentiable physics within MuJoCo to jointly refine all scene components - from object geometry and appearance to robot poses and physical parameters - directly from raw and imprecise robot trajectories. This unified optimization allows us to simultaneously achieve high-fidelity object mesh reconstruction, generate photorealistic novel views, and perform annotation-free robot pose calibration. We demonstrate the effectiveness of our approach both in simulation and on challenging real-world sequences using an ALOHA 2 bi-manual manipulator, enabling more practical and robust real-to-simulation pipelines.
Astra: Toward General-Purpose Mobile Robots via Hierarchical Multimodal Learning
Jun 06, 2025Modern robot navigation systems encounter difficulties in diverse and complex indoor environments. Traditional approaches rely on multiple modules with small models or rule-based systems and thus lack adaptability to new environments. To address this, we developed Astra, a comprehensive dual-model architecture, Astra-Global and Astra-Local, for mobile robot navigation. Astra-Global, a multimodal LLM, processes vision and language inputs to perform self and goal localization using a hybrid topological-semantic graph as the global map, and outperforms traditional visual place recognition methods. Astra-Local, a multitask network, handles local path planning and odometry estimation. Its 4D spatial-temporal encoder, trained through self-supervised learning, generates robust 4D features for downstream tasks. The planning head utilizes flow matching and a novel masked ESDF loss to minimize collision risks for generating local trajectories, and the odometry head integrates multi-sensor inputs via a transformer encoder to predict the relative pose of the robot. Deployed on real in-house mobile robots, Astra achieves high end-to-end mission success rate across diverse indoor environments.
Scaling Laws of Scientific Discovery with AI and Robot Scientists
Mar 28, 2025



The rapid evolution of scientific inquiry highlights an urgent need for groundbreaking methodologies that transcend the limitations of traditional research. Conventional approaches, bogged down by manual processes and siloed expertise, struggle to keep pace with the demands of modern discovery. We envision an autonomous generalist scientist (AGS) system-a fusion of agentic AI and embodied robotics-that redefines the research lifecycle. This system promises to autonomously navigate physical and digital realms, weaving together insights from disparate disciplines with unprecedented efficiency. By embedding advanced AI and robot technologies into every phase-from hypothesis formulation to peer-ready manuscripts-AGS could slash the time and resources needed for scientific research in diverse field. We foresee a future where scientific discovery follows new scaling laws, driven by the proliferation and sophistication of such systems. As these autonomous agents and robots adapt to extreme environments and leverage a growing reservoir of knowledge, they could spark a paradigm shift, pushing the boundaries of what's possible and ushering in an era of relentless innovation.
NsBM-GAT: A Non-stationary Block Maximum and Graph Attention Framework for General Traffic Crash Risk Prediction
Mar 06, 2025



Accurate prediction of traffic crash risks for individual vehicles is essential for enhancing vehicle safety. While significant attention has been given to traffic crash risk prediction, existing studies face two main challenges: First, due to the scarcity of individual vehicle data before crashes, most models rely on hypothetical scenarios deemed dangerous by researchers. This raises doubts about their applicability to actual pre-crash conditions. Second, some crash risk prediction frameworks were learned from dashcam videos. Although such videos capture the pre-crash behavior of individual vehicles, they often lack critical information about the movements of surrounding vehicles. However, the interaction between a vehicle and its surrounding vehicles is highly influential in crash occurrences. To overcome these challenges, we propose a novel non-stationary extreme value theory (EVT), where the covariate function is optimized in a nonlinear fashion using a graph attention network. The EVT component incorporates the stochastic nature of crashes through probability distribution, which enhances model interpretability. Notably, the nonlinear covariate function enables the model to capture the interactive behavior between the target vehicle and its multiple surrounding vehicles, facilitating crash risk prediction across different driving tasks. We train and test our model using 100 sets of vehicle trajectory data before real crashes, collected via drones over three years from merging and weaving segments. We demonstrate that our model successfully learns micro-level precursors of crashes and fits a more accurate distribution with the aid of the nonlinear covariate function. Our experiments on the testing dataset show that the proposed model outperforms existing models by providing more accurate predictions for both rear-end and sideswipe crashes simultaneously.
Discovery of skill switching criteria for learning agile quadruped locomotion
Feb 10, 2025This paper develops a hierarchical learning and optimization framework that can learn and achieve well-coordinated multi-skill locomotion. The learned multi-skill policy can switch between skills automatically and naturally in tracking arbitrarily positioned goals and recover from failures promptly. The proposed framework is composed of a deep reinforcement learning process and an optimization process. First, the contact pattern is incorporated into the reward terms for learning different types of gaits as separate policies without the need for any other references. Then, a higher level policy is learned to generate weights for individual policies to compose multi-skill locomotion in a goal-tracking task setting. Skills are automatically and naturally switched according to the distance to the goal. The proper distances for skill switching are incorporated in reward calculation for learning the high level policy and updated by an outer optimization loop as learning progresses. We first demonstrated successful multi-skill locomotion in comprehensive tasks on a simulated Unitree A1 quadruped robot. We also deployed the learned policy in the real world showcasing trotting, bounding, galloping, and their natural transitions as the goal position changes. Moreover, the learned policy can react to unexpected failures at any time, perform prompt recovery, and resume locomotion successfully. Compared to discrete switch between single skills which failed to transition to galloping in the real world, our proposed approach achieves all the learned agile skills, with smoother and more continuous skill transitions.
Learning Adaptive Hydrodynamic Models Using Neural ODEs in Complex Conditions
Oct 01, 2024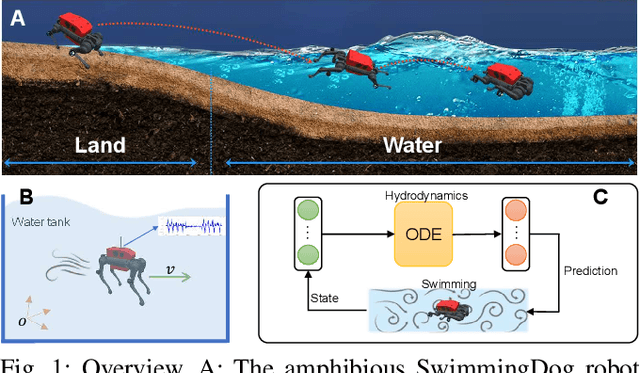
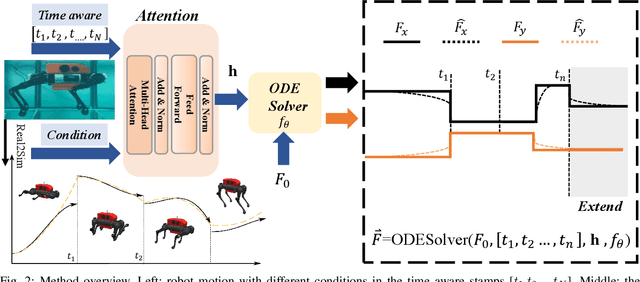


Reinforcement learning-based quadruped robots excel across various terrains but still lack the ability to swim in water due to the complex underwater environment. This paper presents the development and evaluation of a data-driven hydrodynamic model for amphibious quadruped robots, aiming to enhance their adaptive capabilities in complex and dynamic underwater environments. The proposed model leverages Neural Ordinary Differential Equations (ODEs) combined with attention mechanisms to accurately process and interpret real-time sensor data. The model enables the quadruped robots to understand and predict complex environmental patterns, facilitating robust decision-making strategies. We harness real-time sensor data, capturing various environmental and internal state parameters to train and evaluate our model. A significant focus of our evaluation involves testing the quadruped robot's performance across different hydrodynamic conditions and assessing its capabilities at varying speeds and fluid dynamic conditions. The outcomes suggest that the model can effectively learn and adapt to varying conditions, enabling the prediction of force states and enhancing autonomous robotic behaviors in various practical scenarios.