 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Reinforcement Learning Simulation for Environmental Policy Synthesis
Apr 17, 2025
Climate policy development faces significant challenges due to deep uncertainty, complex system dynamics, and competing stakeholder interests. Climate simulation methods, such as Earth System Models, have become valuable tools for policy exploration. However, their typical use is for evaluating potential polices, rather than directly synthesizing them. The problem can be inverted to optimize for policy pathways, but the traditional optimization approaches often struggle with non-linear dynamics, heterogeneous agents, and comprehensive uncertainty quantification. We propose a framework for augmenting climate simulations with Multi-Agent Reinforcement Learning (MARL) to address these limitations. We identify key challenges at the interface between climate simulations and the application of MARL in the context of policy synthesis, including reward definition, scalability with increasing agents and state spaces, uncertainty propagation across linked systems, and solution validation. Additionally, we discuss challenges in making MARL-derived solutions interpretable and useful for policy-makers. Our framework provides a foundation for more sophisticated climate policy exploration while acknowledging important limitations and areas for future research.
AI Will Always Love You: Studying Implicit Biases in Romantic AI Companions
Feb 27, 2025



While existing studies have recognised explicit biases in generative models, including occupational gender biases, the nuances of gender stereotypes and expectations of relationships between users and AI companions remain underexplored. In the meantime, AI companions have become increasingly popular as friends or gendered romantic partners to their users. This study bridges the gap by devising three experiments tailored for romantic, gender-assigned AI companions and their users, effectively evaluating implicit biases across various-sized LLMs. Each experiment looks at a different dimension: implicit associations, emotion responses, and sycophancy. This study aims to measure and compare biases manifested in different companion systems by quantitatively analysing persona-assigned model responses to a baseline through newly devised metrics. The results are noteworthy: they show that assigning gendered, relationship personas to Large Language Models significantly alters the responses of these models, and in certain situations in a biased, stereotypical way.
Crafting desirable climate trajectories with RL explored socio-environmental simulations
Oct 09, 2024



Climate change poses an existential threat, necessitating effective climate policies to enact impactful change. Decisions in this domain are incredibly complex, involving conflicting entities and evidence. In the last decades, policymakers increasingly use simulations and computational methods to guide some of their decisions. Integrated Assessment Models (IAMs) are one of such methods, which combine social, economic, and environmental simulations to forecast potential policy effects. For example, the UN uses outputs of IAMs for their recent Intergovernmental Panel on Climate Change (IPCC) reports. Traditionally these have been solved using recursive equation solvers, but have several shortcomings, e.g. struggling at decision making under uncertainty. Recent preliminary work using Reinforcement Learning (RL) to replace the traditional solvers shows promising results in decision making in uncertain and noisy scenarios. We extend on this work by introducing multiple interacting RL agents as a preliminary analysis on modelling the complex interplay of socio-interactions between various stakeholders or nations that drives much of the current climate crisis. Our findings show that cooperative agents in this framework can consistently chart pathways towards more desirable futures in terms of reduced carbon emissions and improved economy. However, upon introducing competition between agents, for instance by using opposing reward functions, desirable climate futures are rarely reached. Modelling competition is key to increased realism in these simulations, as such we employ policy interpretation by visualising what states lead to more uncertain behaviour, to understand algorithm failure. Finally, we highlight the current limitations and avenues for further work to ensure future technology uptake for policy derivation.
Are Large Language Models Strategic Decision Makers? A Study of Performance and Bias in Two-Player Non-Zero-Sum Games
Jul 05, 2024



Large Language Models (LLMs) have been increasingly used in real-world settings, yet their strategic abilities remain largely unexplored. Game theory provides a good framework for assessing the decision-making abilities of LLMs in interactions with other agents. Although prior studies have shown that LLMs can solve these tasks with carefully curated prompts, they fail when the problem setting or prompt changes. In this work we investigate LLMs' behaviour in strategic games, Stag Hunt and Prisoner Dilemma, analyzing performance variations under different settings and prompts. Our results show that the tested state-of-the-art LLMs exhibit at least one of the following systematic biases: (1) positional bias, (2) payoff bias, or (3) behavioural bias. Subsequently, we observed that the LLMs' performance drops when the game configuration is misaligned with the affecting biases. Performance is assessed based on the selection of the correct action, one which agrees with the prompted preferred behaviours of both players. Alignment refers to whether the LLM's bias aligns with the correct action. For example, GPT-4o's average performance drops by 34% when misaligned. Additionally, the current trend of "bigger and newer is better" does not hold for the above, where GPT-4o (the current best-performing LLM) suffers the most substantial performance drop. Lastly, we note that while chain-of-thought prompting does reduce the effect of the biases on most models, it is far from solving the problem at the fundamental level.
A Toolbox for Modelling Engagement with Educational Videos
Dec 30, 2023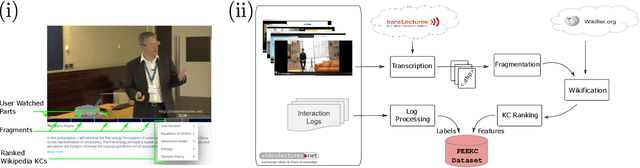

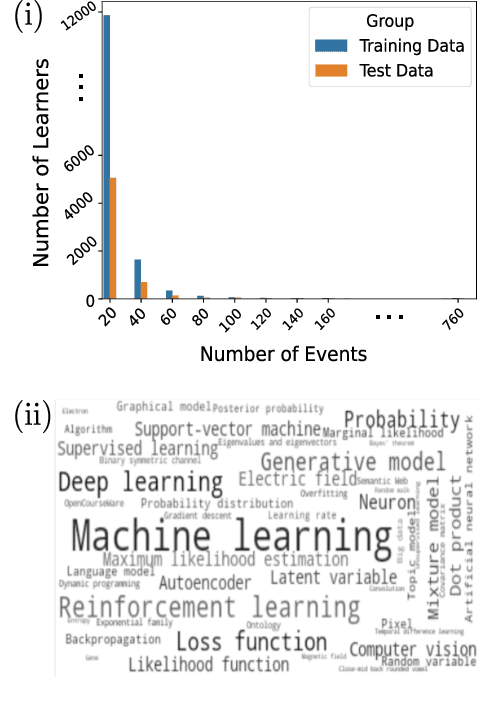
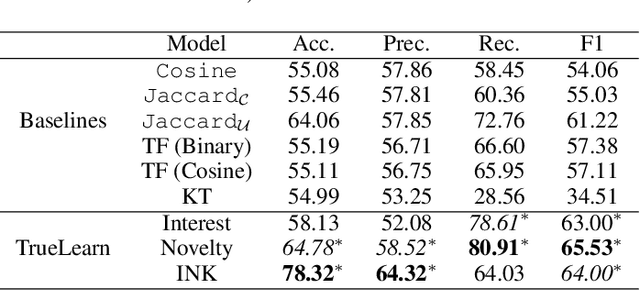
With the advancement and utility of Artificial Intelligence (AI), personalising education to a global population could be a cornerstone of new educational systems in the future. This work presents the PEEKC dataset and the TrueLearn Python library, which contains a dataset and a series of online learner state models that are essential to facilitate research on learner engagement modelling.TrueLearn family of models was designed following the "open learner" concept, using humanly-intuitive user representations. This family of scalable, online models also help end-users visualise the learner models, which may in the future facilitate user interaction with their models/recommenders. The extensive documentation and coding examples make the library highly accessible to both machine learning developers and educational data mining and learning analytics practitioners. The experiments show the utility of both the dataset and the library with predictive performance significantly exceeding comparative baseline models. The dataset contains a large amount of AI-related educational videos, which are of interest for building and validating AI-specific educational recommenders.
TrueLearn: A Python Library for Personalised Informational Recommendations with (Implicit) Feedback
Sep 20, 2023This work describes the TrueLearn Python library, which contains a family of online learning Bayesian models for building educational (or more generally, informational) recommendation systems. This family of models was designed following the "open learner" concept, using humanly-intuitive user representations. For the sake of interpretability and putting the user in control, the TrueLearn library also contains different representations to help end-users visualise the learner models, which may in the future facilitate user interaction with their own models. Together with the library, we include a previously publicly released implicit feedback educational dataset with evaluation metrics to measure the performance of the models. The extensive documentation and coding examples make the library highly accessible to both machine learning developers and educational data mining and learning analytic practitioners. The library and the support documentation with examples are available at https://truelearn.readthedocs.io/en/latest.
Comparing the carbon costs and benefits of low-resource solar nowcasting
Oct 10, 2022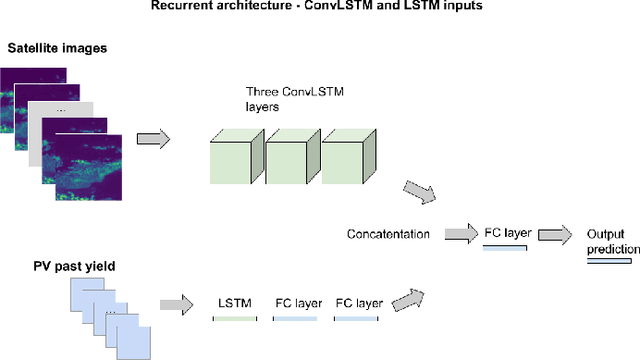
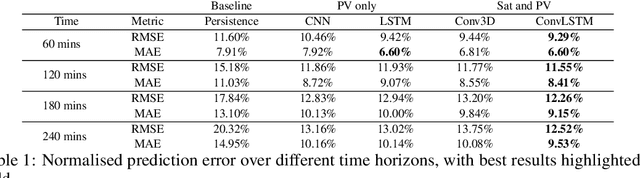

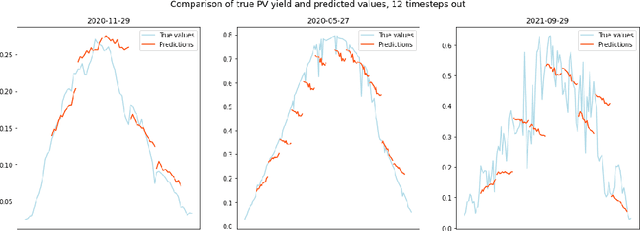
Solar PV yield nowcasting is used to help anticipate peaks and troughs in demand to support grid integration. This paper compares multiple low-resource approaches to nowcasting solar PV yield, using a dataset of UK satellite imagery and solar PV energy readings over a 1 to 4-hour time range. The paper also estimates the carbon emissions generated and averted by deploying models, and finds that even small models that could be deployable in low-resource settings may have a benefit several orders of magnitude greater than its carbon cost. The paper also examines prediction errors and the activations in a CNN.
Semantic TrueLearn: Using Semantic Knowledge Graphs in Recommendation Systems
Dec 08, 2021
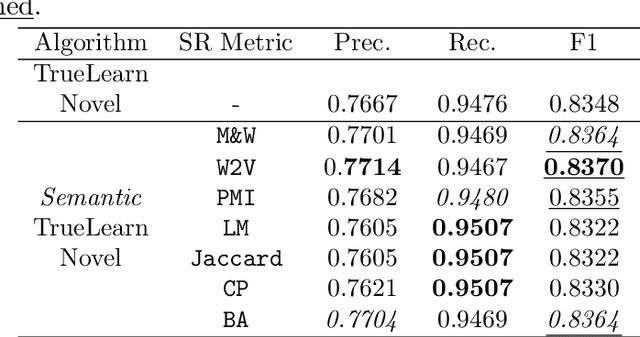
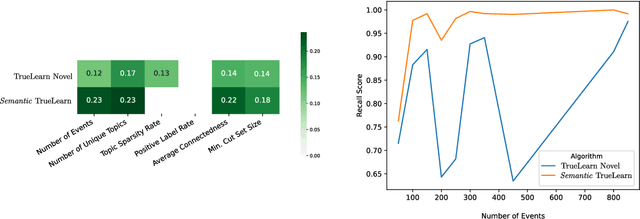

In informational recommenders, many challenges arise from the need to handle the semantic and hierarchical structure between knowledge areas. This work aims to advance towards building a state-aware educational recommendation system that incorporates semantic relatedness between knowledge topics, propagating latent information across semantically related topics. We introduce a novel learner model that exploits this semantic relatedness between knowledge components in learning resources using the Wikipedia link graph, with the aim to better predict learner engagement and latent knowledge in a lifelong learning scenario. In this sense, Semantic TrueLearn builds a humanly intuitive knowledge representation while leveraging Bayesian machine learning to improve the predictive performance of the educational engagement. Our experiments with a large dataset demonstrate that this new semantic version of TrueLearn algorithm achieves statistically significant improvements in terms of predictive performance with a simple extension that adds semantic awareness to the model.
Could AI Democratise Education? Socio-Technical Imaginaries of an EdTech Revolution
Dec 03, 2021Artificial Intelligence (AI) in Education has been said to have the potential for building more personalised curricula, as well as democratising education worldwide and creating a Renaissance of new ways of teaching and learning. Millions of students are already starting to benefit from the use of these technologies, but millions more around the world are not. If this trend continues, the first delivery of AI in Education could be greater educational inequality, along with a global misallocation of educational resources motivated by the current technological determinism narrative. In this paper, we focus on speculating and posing questions around the future of AI in Education, with the aim of starting the pressing conversation that would set the right foundations for the new generation of education that is permeated by technology. This paper starts by synthesising how AI might change how we learn and teach, focusing specifically on the case of personalised learning companions, and then move to discuss some socio-technical features that will be crucial for avoiding the perils of these AI systems worldwide (and perhaps ensuring their success). This paper also discusses the potential of using AI together with free, participatory and democratic resources, such as Wikipedia, Open Educational Resources and open-source tools. We also emphasise the need for collectively designing human-centered, transparent, interactive and collaborative AI-based algorithms that empower and give complete agency to stakeholders, as well as support new emerging pedagogies. Finally, we ask what would it take for this educational revolution to provide egalitarian and empowering access to education, beyond any political, cultural, language, geographical and learning ability barriers.
A PAC-Bayesian Perspective on Structured Prediction with Implicit Loss Embeddings
Dec 21, 2020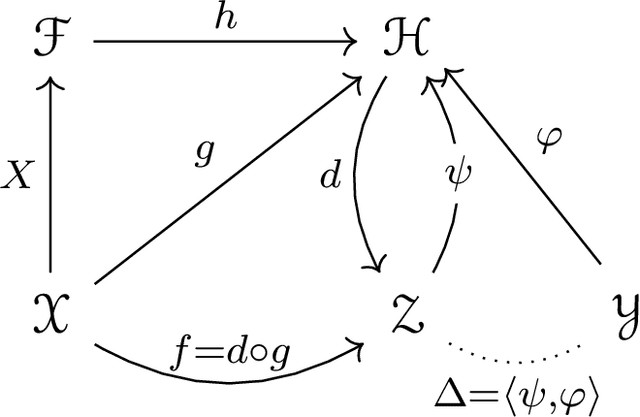
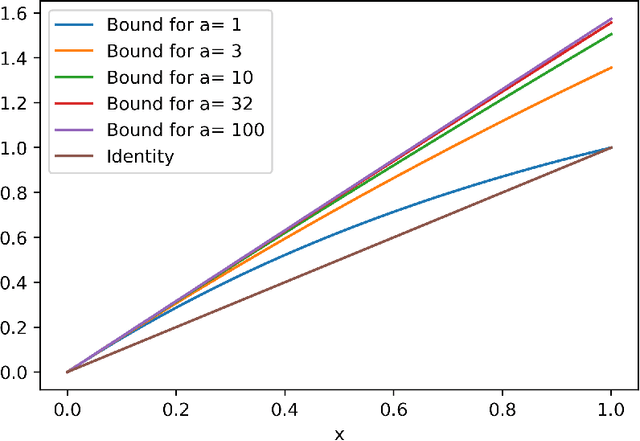
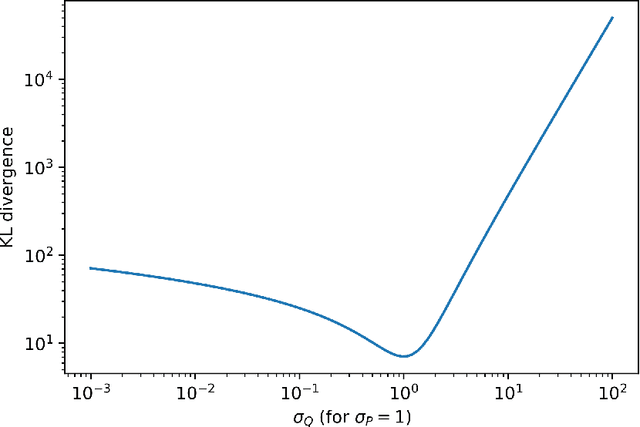
Many practical machine learning tasks can be framed as Structured prediction problems, where several output variables are predicted and considered interdependent. Recent theoretical advances in structured prediction have focused on obtaining fast rates convergence guarantees, especially in the Implicit Loss Embedding (ILE) framework. PAC-Bayes has gained interest recently for its capacity of producing tight risk bounds for predictor distributions. This work proposes a novel PAC-Bayes perspective on the ILE Structured prediction framework. We present two generalization bounds, on the risk and excess risk, which yield insights into the behavior of ILE predictors. Two learning algorithms are derived from these bounds. The algorithms are implemented and their behavior analyzed, with source code available at \url{https://github.com/theophilec/PAC-Bayes-ILE-Structured-Prediction}.