 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosed-form Filtering for Non-linear Systems
Feb 15, 2024Sequential Bayesian Filtering aims to estimate the current state distribution of a Hidden Markov Model, given the past observations. The problem is well-known to be intractable for most application domains, except in notable cases such as the tabular setting or for linear dynamical systems with gaussian noise. In this work, we propose a new class of filters based on Gaussian PSD Models, which offer several advantages in terms of density approximation and computational efficiency. We show that filtering can be efficiently performed in closed form when transitions and observations are Gaussian PSD Models. When the transition and observations are approximated by Gaussian PSD Models, we show that our proposed estimator enjoys strong theoretical guarantees, with estimation error that depends on the quality of the approximation and is adaptive to the regularity of the transition probabilities. In particular, we identify regimes in which our proposed filter attains a TV $\epsilon$-error with memory and computational complexity of $O(\epsilon^{-1})$ and $O(\epsilon^{-3/2})$ respectively, including the offline learning step, in contrast to the $O(\epsilon^{-2})$ complexity of sampling methods such as particle filtering.
Measuring dissimilarity with diffeomorphism invariance
Mar 07, 2022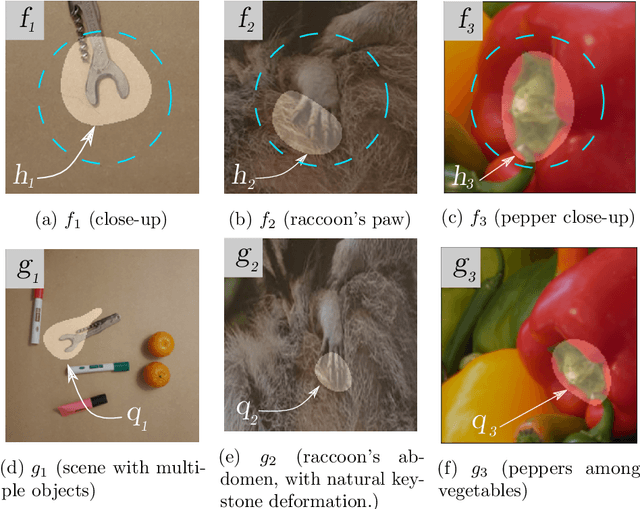
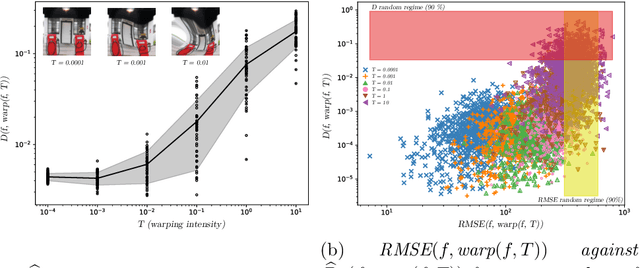
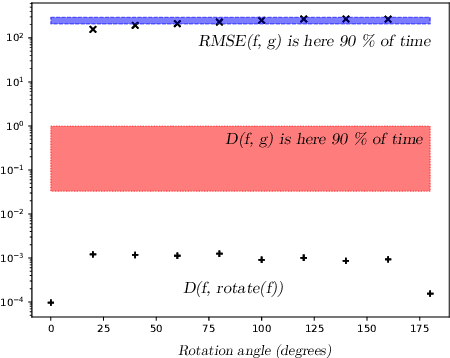
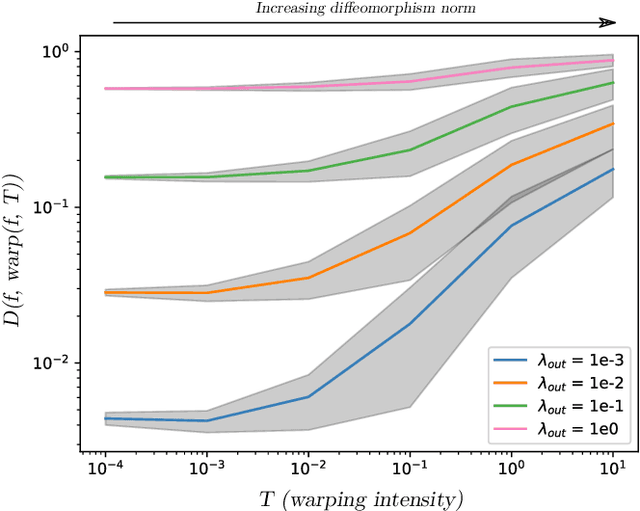
Measures of similarity (or dissimilarity) are a key ingredient to many machine learning algorithms. We introduce DID, a pairwise dissimilarity measure applicable to a wide range of data spaces, which leverages the data's internal structure to be invariant to diffeomorphisms. We prove that DID enjoys properties which make it relevant for theoretical study and practical use. By representing each datum as a function, DID is defined as the solution to an optimization problem in a Reproducing Kernel Hilbert Space and can be expressed in closed-form. In practice, it can be efficiently approximated via Nystr\"om sampling. Empirical experiments support the merits of DID.
A PAC-Bayesian Perspective on Structured Prediction with Implicit Loss Embeddings
Dec 21, 2020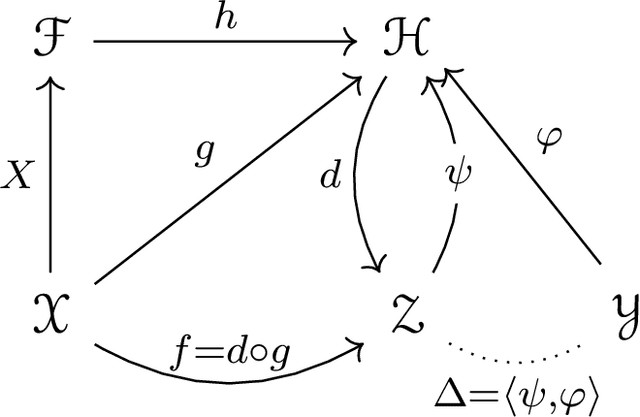
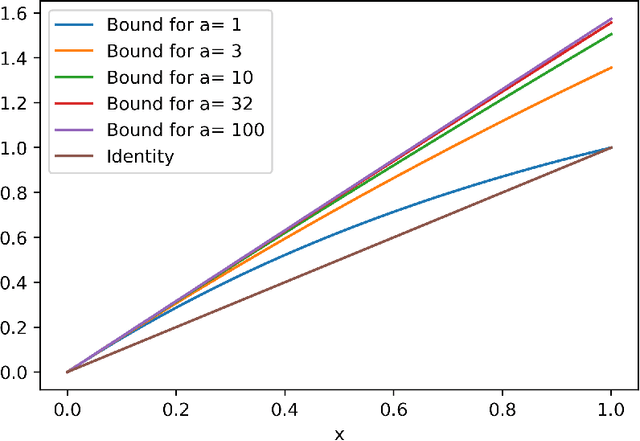
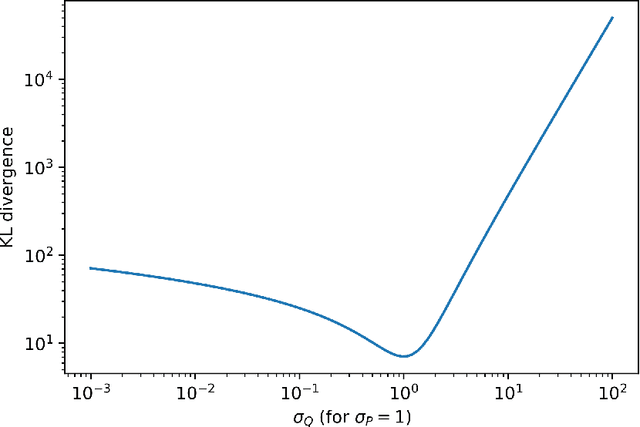
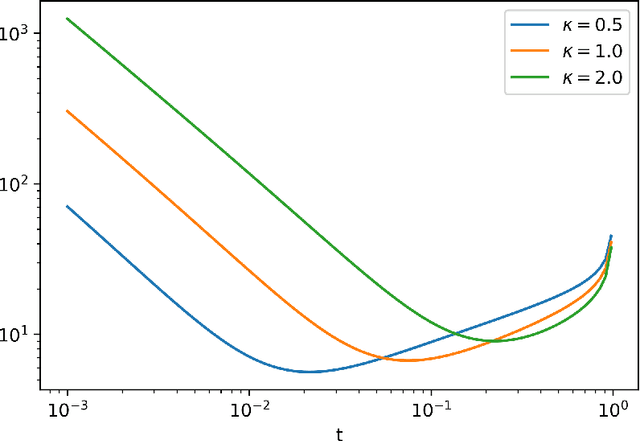
Many practical machine learning tasks can be framed as Structured prediction problems, where several output variables are predicted and considered interdependent. Recent theoretical advances in structured prediction have focused on obtaining fast rates convergence guarantees, especially in the Implicit Loss Embedding (ILE) framework. PAC-Bayes has gained interest recently for its capacity of producing tight risk bounds for predictor distributions. This work proposes a novel PAC-Bayes perspective on the ILE Structured prediction framework. We present two generalization bounds, on the risk and excess risk, which yield insights into the behavior of ILE predictors. Two learning algorithms are derived from these bounds. The algorithms are implemented and their behavior analyzed, with source code available at \url{https://github.com/theophilec/PAC-Bayes-ILE-Structured-Prediction}.