 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElastic-Net Multiple Kernel Learning: Combining Multiple Data Sources for Prediction
Dec 12, 2025Multiple Kernel Learning (MKL) models combine several kernels in supervised and unsupervised settings to integrate multiple data representations or sources, each represented by a different kernel. MKL seeks an optimal linear combination of base kernels that maximizes a generalized performance measure under a regularization constraint. Various norms have been used to regularize the kernel weights, including $l1$, $l2$ and $lp$, as well as the "elastic-net" penalty, which combines $l1$- and $l2$-norm to promote both sparsity and the selection of correlated kernels. This property makes elastic-net regularized MKL (ENMKL) especially valuable when model interpretability is critical and kernels capture correlated information, such as in neuroimaging. Previous ENMKL methods have followed a two-stage procedure: fix kernel weights, train a support vector machine (SVM) with the weighted kernel, and then update the weights via gradient descent, cutting-plane methods, or surrogate functions. Here, we introduce an alternative ENMKL formulation that yields a simple analytical update for the kernel weights. We derive explicit algorithms for both SVM and kernel ridge regression (KRR) under this framework, and implement them in the open-source Pattern Recognition for Neuroimaging Toolbox (PRoNTo). We evaluate these ENMKL algorithms against $l1$-norm MKL and against SVM (or KRR) trained on the unweighted sum of kernels across three neuroimaging applications. Our results show that ENMKL matches or outperforms $l1$-norm MKL in all tasks and only underperforms standard SVM in one scenario. Crucially, ENMKL produces sparser, more interpretable models by selectively weighting correlated kernels.
Some theoretical improvements on the tightness of PAC-Bayes risk certificates for neural networks
Oct 09, 2025This paper presents four theoretical contributions that improve the usability of risk certificates for neural networks based on PAC-Bayes bounds. First, two bounds on the KL divergence between Bernoulli distributions enable the derivation of the tightest explicit bounds on the true risk of classifiers across different ranges of empirical risk. The paper next focuses on the formalization of an efficient methodology based on implicit differentiation that enables the introduction of the optimization of PAC-Bayesian risk certificates inside the loss/objective function used to fit the network/model. The last contribution is a method to optimize bounds on non-differentiable objectives such as the 0-1 loss. These theoretical contributions are complemented with an empirical evaluation on the MNIST and CIFAR-10 datasets. In fact, this paper presents the first non-vacuous generalization bounds on CIFAR-10 for neural networks.
General Uncertainty Estimation with Delta Variances
Feb 20, 2025

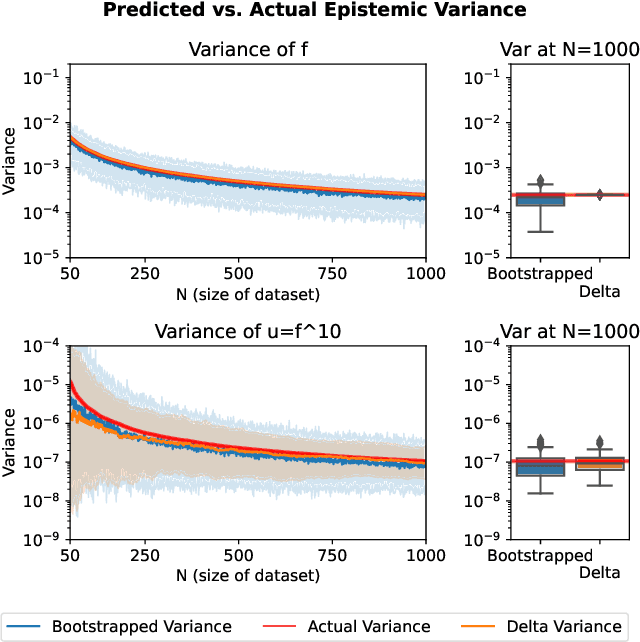

Decision makers may suffer from uncertainty induced by limited data. This may be mitigated by accounting for epistemic uncertainty, which is however challenging to estimate efficiently for large neural networks. To this extent we investigate Delta Variances, a family of algorithms for epistemic uncertainty quantification, that is computationally efficient and convenient to implement. It can be applied to neural networks and more general functions composed of neural networks. As an example we consider a weather simulator with a neural-network-based step function inside -- here Delta Variances empirically obtain competitive results at the cost of a single gradient computation. The approach is convenient as it requires no changes to the neural network architecture or training procedure. We discuss multiple ways to derive Delta Variances theoretically noting that special cases recover popular techniques and present a unified perspective on multiple related methods. Finally we observe that this general perspective gives rise to a natural extension and empirically show its benefit.
Aligning Generalisation Between Humans and Machines
Nov 23, 2024



Recent advances in AI -- including generative approaches -- have resulted in technology that can support humans in scientific discovery and decision support but may also disrupt democracies and target individuals. The responsible use of AI increasingly shows the need for human-AI teaming, necessitating effective interaction between humans and machines. A crucial yet often overlooked aspect of these interactions is the different ways in which humans and machines generalise. In cognitive science, human generalisation commonly involves abstraction and concept learning. In contrast, AI generalisation encompasses out-of-domain generalisation in machine learning, rule-based reasoning in symbolic AI, and abstraction in neuro-symbolic AI. In this perspective paper, we combine insights from AI and cognitive science to identify key commonalities and differences across three dimensions: notions of generalisation, methods for generalisation, and evaluation of generalisation. We map the different conceptualisations of generalisation in AI and cognitive science along these three dimensions and consider their role in human-AI teaming. This results in interdisciplinary challenges across AI and cognitive science that must be tackled to provide a foundation for effective and cognitively supported alignment in human-AI teaming scenarios.
Contrastive learning of T cell receptor representations
Jun 10, 2024Computational prediction of the interaction of T cell receptors (TCRs) and their ligands is a grand challenge in immunology. Despite advances in high-throughput assays, specificity-labelled TCR data remains sparse. In other domains, the pre-training of language models on unlabelled data has been successfully used to address data bottlenecks. However, it is unclear how to best pre-train protein language models for TCR specificity prediction. Here we introduce a TCR language model called SCEPTR (Simple Contrastive Embedding of the Primary sequence of T cell Receptors), capable of data-efficient transfer learning. Through our model, we introduce a novel pre-training strategy combining autocontrastive learning and masked-language modelling, which enables SCEPTR to achieve its state-of-the-art performance. In contrast, existing protein language models and a variant of SCEPTR pre-trained without autocontrastive learning are outperformed by sequence alignment-based methods. We anticipate that contrastive learning will be a useful paradigm to decode the rules of TCR specificity.
A Toolbox for Modelling Engagement with Educational Videos
Dec 30, 2023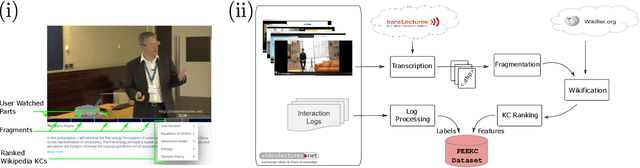

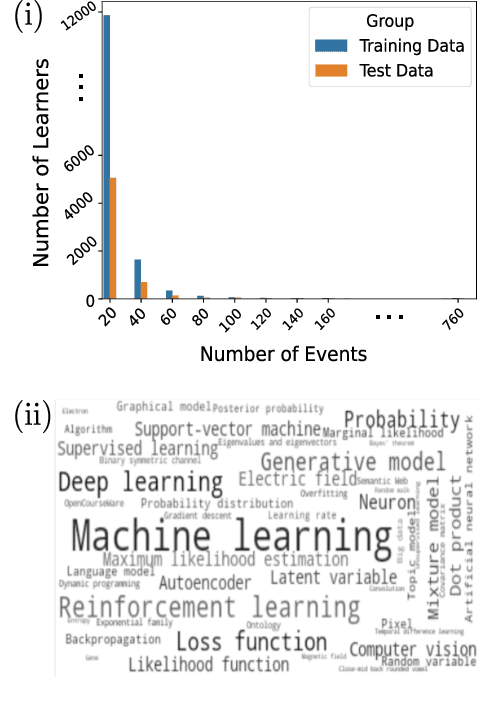
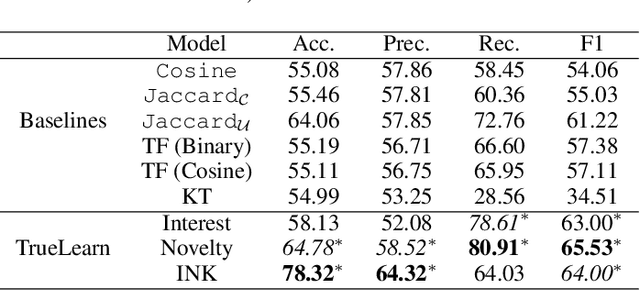
With the advancement and utility of Artificial Intelligence (AI), personalising education to a global population could be a cornerstone of new educational systems in the future. This work presents the PEEKC dataset and the TrueLearn Python library, which contains a dataset and a series of online learner state models that are essential to facilitate research on learner engagement modelling.TrueLearn family of models was designed following the "open learner" concept, using humanly-intuitive user representations. This family of scalable, online models also help end-users visualise the learner models, which may in the future facilitate user interaction with their models/recommenders. The extensive documentation and coding examples make the library highly accessible to both machine learning developers and educational data mining and learning analytics practitioners. The experiments show the utility of both the dataset and the library with predictive performance significantly exceeding comparative baseline models. The dataset contains a large amount of AI-related educational videos, which are of interest for building and validating AI-specific educational recommenders.
Can Reinforcement Learning support policy makers? A preliminary study with Integrated Assessment Models
Dec 11, 2023Governments around the world aspire to ground decision-making on evidence. Many of the foundations of policy making - e.g. sensing patterns that relate to societal needs, developing evidence-based programs, forecasting potential outcomes of policy changes, and monitoring effectiveness of policy programs - have the potential to benefit from the use of large-scale datasets or simulations together with intelligent algorithms. These could, if designed and deployed in a way that is well grounded on scientific evidence, enable a more comprehensive, faster, and rigorous approach to policy making. Integrated Assessment Models (IAM) is a broad umbrella covering scientific models that attempt to link main features of society and economy with the biosphere into one modelling framework. At present, these systems are probed by policy makers and advisory groups in a hypothesis-driven manner. In this paper, we empirically demonstrate that modern Reinforcement Learning can be used to probe IAMs and explore the space of solutions in a more principled manner. While the implication of our results are modest since the environment is simplistic, we believe that this is a stepping stone towards more ambitious use cases, which could allow for effective exploration of policies and understanding of their consequences and limitations.
Social AI and the Challenges of the Human-AI Ecosystem
Jun 23, 2023


The rise of large-scale socio-technical systems in which humans interact with artificial intelligence (AI) systems (including assistants and recommenders, in short AIs) multiplies the opportunity for the emergence of collective phenomena and tipping points, with unexpected, possibly unintended, consequences. For example, navigation systems' suggestions may create chaos if too many drivers are directed on the same route, and personalised recommendations on social media may amplify polarisation, filter bubbles, and radicalisation. On the other hand, we may learn how to foster the "wisdom of crowds" and collective action effects to face social and environmental challenges. In order to understand the impact of AI on socio-technical systems and design next-generation AIs that team with humans to help overcome societal problems rather than exacerbate them, we propose to build the foundations of Social AI at the intersection of Complex Systems, Network Science and AI. In this perspective paper, we discuss the main open questions in Social AI, outlining possible technical and scientific challenges and suggesting research avenues.
Exploration via Epistemic Value Estimation
Mar 07, 2023

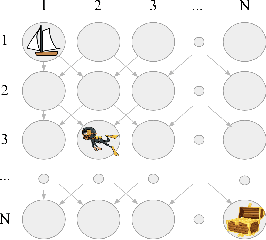
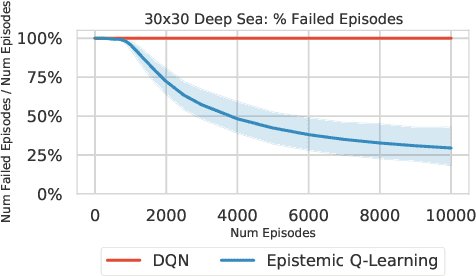
How to efficiently explore in reinforcement learning is an open problem. Many exploration algorithms employ the epistemic uncertainty of their own value predictions -- for instance to compute an exploration bonus or upper confidence bound. Unfortunately the required uncertainty is difficult to estimate in general with function approximation. We propose epistemic value estimation (EVE): a recipe that is compatible with sequential decision making and with neural network function approximators. It equips agents with a tractable posterior over all their parameters from which epistemic value uncertainty can be computed efficiently. We use the recipe to derive an epistemic Q-Learning agent and observe competitive performance on a series of benchmarks. Experiments confirm that the EVE recipe facilitates efficient exploration in hard exploration tasks.
Can Population-based Engagement Improve Personalisation? A Novel Dataset and Experiments
Jun 22, 2022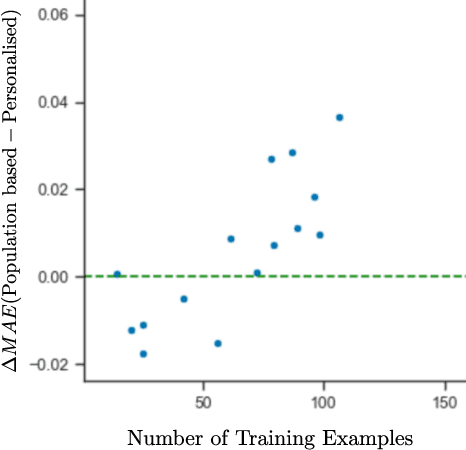
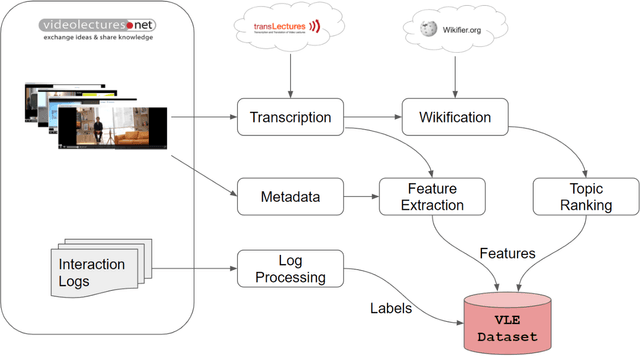
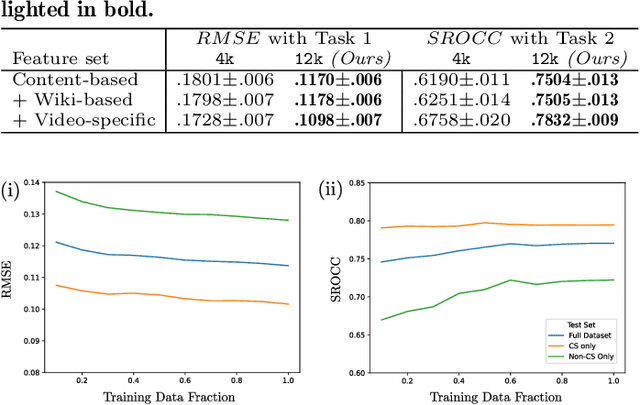
This work explores how population-based engagement prediction can address cold-start at scale in large learning resource collections. The paper introduces i) VLE, a novel dataset that consists of content and video based features extracted from publicly available scientific video lectures coupled with implicit and explicit signals related to learner engagement, ii) two standard tasks related to predicting and ranking context-agnostic engagement in video lectures with preliminary baselines and iii) a set of experiments that validate the usefulness of the proposed dataset. Our experimental results indicate that the newly proposed VLE dataset leads to building context-agnostic engagement prediction models that are significantly performant than ones based on previous datasets, mainly attributing to the increase of training examples. VLE dataset's suitability in building models towards Computer Science/ Artificial Intelligence education focused on e-learning/ MOOC use-cases is also evidenced. Further experiments in combining the built model with a personalising algorithm show promising improvements in addressing the cold-start problem encountered in educational recommenders. This is the largest and most diverse publicly available dataset to our knowledge that deals with learner engagement prediction tasks. The dataset, helper tools, descriptive statistics and example code snippets are available publicly.